And once again, the Shuusou Gyoku task was too complex to be satisfyingly solved within a single month. Even just finding provably correct loop sections in both the original and arranged MIDI files required some rather involved detection algorithms. I could have just defined what sounded like correct loops, but the results of these algorithms were quite surprising indeed. Turns out that not even Seihou is safe from ZUN quirks, and some tracks technically loop much later than you'd think they do, or don't loop at all. And since I then wanted to put these MIDI loops back into the game to ensure perfect synchronization between the recordings and MIDI versions, I ended up rewriting basically all the MIDI code in a cross-platform way. This rewrite also uncovered a pbg bug that has traveled from Shuusou Gyoku into Windows Touhou, where it survived until ZUN ultimately removed all MIDI code in TH11 (!)…
Fortunately, the backlog still had enough general PC-98 Touhou funds that I could spend on picking some soon-important low-hanging fruit, giving me something to deliver for the end of the month after all. TH04 and TH05 use almost identical code for their main/option menus, so decompiling it would make number go up quite significantly and the associated blog post won't be that long…
Wait, what's this, a bug report from touhou-memories concerning the website?
Tab switchers tended to break on certain Firefox versions, and
video playback didn't work on Microsoft Edge at all?
Those are definitely some high-priority bugs that demand immediate attention.
The tab switcher issue was easily fixed by replacing the previous z-index trickery with a more robust solution involving the hidden attribute. The second one, however, is much more aggravating, because video playback on Edge has been broken ever since I 📝 switched the preferred video codec to AV1.
This goes so far beyond not supporting a specific codec. Usually, unsupported codecs aren't supposed to be an issue: As soon as you start using the HTML <video> tag, you'll learn that not every browser supports all codecs. And so you set up an encoding pipeline to serve each video in a mix of new and ancient formats, put the <source> tag of the most preferred codec first, and rest assured that browsers will fall back on the best-supported option as necessary. Except that Edge doesn't even try, and insists on staying on a non-playing AV1 video. 🙄
The codecs parameter for the <source> type attribute was the first potential solution I came across. Specifying the video codec down to the finest encoding details right in the HTML markup sounds like a good idea, similar to specifying sizes of images and videos to prevent layout reflows on long pages during the initial page load. So why was this the first time I heard of this feature? The fact that there isn't a simple ffprobe -show_html_codecs_string command to retrieve this string might already give a clue about how useful it is in practice. Instead, you have to manually piece the string together by grepping your way through all of a video's metadata…
…and then it still doesn't change anything about Edge's behavior, even when also specifying the string for the VP9 and VP8 sources. Calling the infamously ridiculous HTMLMediaElement.canPlayType() method with a representative parameter of "video/webm; codecs=av01.1.04M.08.0.000.01.13.00.0" explains why: Both the AV1-supporting Chrome and Edge return "probably", but only the former can actually play this format. 🤦
But wait, there is an AV1 video extension in the Microsoft Store that would add support to any unspecified favorite video app. Except that it stopped working inside Edge as of version 116. And even if it did: If you can't query the presence of this extension via JavaScript, it might as well not exist at all.
Not to mention that the favorite video app part is obviously a lie as a lot of widely preferred Windows video apps are bundled with their own codecs, and have probably long supported AV1.
In the end, there's no way around the utter desperation move of removing the AV1 <source> for Edge users. Serving each video in two other formats means that we can at least do something here – try visiting the GitHub release page of the P0234-1 TH01 Anniversary Edition build in Edge and you also don't get to see anything, because that video uses AV1 and GitHub understandably doesn't re-encode every uploaded video into a variety of old formats.
Just for comparison, I tried both that page and the ReC98 blog on an old Android 6 phone from 2014, and even that phone picked and played the AV1 videos with the latest available Chrome and Firefox versions. This was the phone whose available Firefox version didn't support VP9 in 2019, which was my initial reason for adding the VP8 versions. Looks like it's finally time to drop those… 🤔 Maybe in the far future once I start running out of space on this server.
Removing the <source> tags can be done in one of two places:
server-side, detecting Edge via the User-Agent header, or
I went with 2) because more dynamic server-side code would only move us further away from static site generation, which would make a lot of sense as the next evolutionary step in the architecture of this website. The client-side solution is much simpler too, and we can defer the deletion until a user actually hovers over a specific video.
And while we're at it, let's also add a popup complaining about this whole state of affairs. Edge is heavily marketed inside Windows as "the modern browser recommended by Microsoft", and you sure wouldn't expect low-quality chroma-subsampled VP9 from such a tagline. With such a level of anti-support for AV1, Edge users deserve to know exactly what's going on, especially since this post also explains what they will encounter on other websites.
That's the polite way of putting it.
Alright, where was I? For TH01, the main menu was the last thing I decompiled before the 100% finalization mark, so it's rather anticlimactic to already cover the TH04/TH05 one now, with both of the games still being very far away from 100%, just because people will soon want to translate the description text in the bottom-right corner of the screen. But then again, the ZUN Soft logo animation would make for an even nicer final piece of decompiled code, especially since the bouncing-ball logo from TH01, TH02, and TH03 was the very first decompilation I did, all the way back in 2015.
The code quality of ZUN's VRAM-based menus has barely increased between TH01 and TH05. Both the top-level and option menu still need to know the bounding rectangle of the other one to unblit the right pixels when switching between the two. And since ZUN sure loved hardcoded and copy-pasted numbers in the PC-98 days, the coordinates both tend to be excessively large, and excessively wrong. Luckily, each menu item comes with its own correct unblitting rectangle, which avoids any graphical glitches that would otherwise occur.
As for actual observable quirks and bugs, these menus only contain one of each, and both are exclusive to TH04:
Quitting out of the Music Room moves the cursor to the Start option. In TH05, it stays on Music Room.
Changing the S.E. mode seems to do nothing within TH04's menus, and would only take effect if you also change the Music mode afterward, or launch into the game.
And yes, these videos do have a frame rate of 2 FPS.
Now that 100% finalization of their OP.EXE binaries is within reach, all this bloat made me think about the viability of a 📝 single-executable build for TH04's and TH05's debloated and anniversary versions. It would be really nice to have such a build ready before I start working on the non-ASCII translations – not just because they will be based on the anniversary branch by default, but also because it would significantly help their development if there are 4 fewer executables to worry about.
However, it's not as simple for these games as it was for TH01. The unique code in their OP.EXE and MAINE.EXE binaries is much larger than Borland's easily removed C++ exception handler, so I'd have to remove a lot more bloat to keep the resulting single binary at or below the size of the original MAIN.EXE. But I'm sure going to try.
Speaking of code that can be debloated for great effect: The second push of this delivery focused on the first-launch sound setup menu, whose BGM and sound effect submenus are almost complete code duplicates of each other. The debloated branch could easily remove more than half of the code in there, yielding another ≈800 bytes in case we need them.
If hex-editing MIKO.CFG is more convenient for you than deleting that file, you can set its first byte to FF to re-trigger this menu. Decompiling this screen was not only relevant now because it contains text rendered with font ROM glyphs and it would help dig our way towards more important strings in the data segment, but also because of its visual style. I can imagine many potential mods that might want to use the same backgrounds and box graphics for their menus.
How about an initial language selection menu in the same style?
With the two submenus being shown in a fixed sequence, there's not a lot of room for the code to do anything wrong, and it's even more identical between the two games than the main menu already was. Thankfully, ZUN just reblits the respective options in the new color when moving the cursor, with no 📝 palette tricks. TH04's background image only uses 7 colors, so he could have easily reserved 3 colors for that. In exchange, the TH05 image gets to use the full 16 colors with no change to the code.
Rounding out this delivery, we also got TH05's rolling Yin-Yang Orb animation before the title screen… and it's just more bloat and landmines on a smaller scale that might be noticeable on slower PC-98 models. In total, there are three unnecessary inter-page copies of the entire VRAM that can easily insert lag frames, and two minor page-switching landmines that can potentially lead to tearing on the first frame of the roll or fade animation. Clearly, ZUN did not have smoothness or code quality in mind there, as evidenced by the fact that this animation simply displays 8 .PI files in sequence. But hey, a short animation like this is 📝 another perfectly appropriate place for a quick-and-dirty solution if you develop with a deadline.
And that's 1.30% of all PC-98 Touhou code finalized in two pushes! We're slowly running out of these big shared pieces of ASM code…
I've been neglecting TH03's OP.EXE quite a bit since it simply doesn't contain any translatable plaintext outside the Music Room. All menu labels are gaiji, and even the character selection menu displays its monochrome character names using the 4-plane sprites from CHNAME.BFT. Splitting off half of its data into a separate .ASM file was more akin to getting out a jackhammer to free up the room in front of the third remaining Music Room, but now we're there, and I can decompile all three of them in a natural way, with all referenced data.
Next up, therefore: Doing just that, securing another important piece of text for the upcoming non-ASCII translations and delivering another big piece of easily finalized code. I'm going to work full-time on ReC98 for almost all of December, and delivering that and the Shuusou Gyoku SC-88Pro recording BGM back-to-back should free up about half of the slightly higher cap for this month.
And now we're taking this small indie game from the year 2000 and porting
its game window, input, and sound to the industry-standard cross-platform
API with "simple" in its name.
Why did this have to be so complicated?! I expected this to take maybe 1-2
weeks and result in an equally short blog post. Instead, it raised so many
questions that I ended up with the longest blog post so far, by quite a wide
margin. These pushes ended up covering so many aspects that could be
interesting to a general and non-Seihou-adjacent audience, so I think we
need a table of contents for this one:
Before we can start migrating to SDL, we of course have to integrate it into
the build somehow. On Linux, we'd ideally like to just dynamically link to a
distribution's SDL development package, but since there's no such thing on
Windows, we'd like to compile SDL from source there. This allows us to reuse
our debug and release flags and ensures that we get debug information,
without needing to clone build scripts for every
C++ library ever in the process or something.
So let's get my Tup build scripts ready for compiling vendored libraries… or
maybe not? Recently, I've kept hearing about a hot new
technology that not only provides the rare kind of jank-free
cross-compiling build system for C/C++ code, but innovates by even
bundling a C++ compiler into a single 279 MiB package with no
further dependencies. Realistically replacing both Visual Studio and Tup
with a single tool that could target every OS is quite a selling point. The
upcoming Linux port makes for the perfect occasion to evaluate Zig, and to
find out whether Tup is still my favorite build system in 2023.
Even apart from its main selling point, there's a lot to like about Zig:
First and foremost: It's a modern systems programming language with
seamless C interop that we could gradually migrate parts of the codebase to.
The feature set of the core language seems to hit the sweet spot between C
and C++, although I'd have to use it more to be completely sure.
A native, optimized Hello World binary with no string formatting is
4 KiB when compiled for Windows, and 6.4 KiB when cross-compiled
from Windows to Linux. It's so refreshing to see a systems language in 2023
that doesn't bundle a bulky runtime for trivial programs and then defends it
with the old excuse of "but all this runtime code will come in handy the
larger your program gets". With a first impression like this, Zig
managed to realize the "don't pay for what you don't use" mantra that C++
typically claims for itself, but only pulls off maybe half of the time.
You can directly
target specific CPU models, down to even the oldest 386 CPUs?! How
amazing is that?! In contrast, Visual Studio only describes its /arch:IA32
compatibility option in very vague terms, leaving it up to you to figure out
that "legacy 32-bit x86 instruction set without any vector
operations" actually means "i586/P5 Pentium, because the startup code
still includes an unconditional CPUID instruction". In any
case, it means that Zig could also cover the i586 build.
Even better, changing Zig's CPU model setting recompiles both its
bundled C/C++ standard library and Zig's own compiler-rt polyfill
library for that architecture. This ensures that no unsupported
instructions ever show up in the binary, and also removes the need for
any CPUID checks. This is so much better than the Visual
Studio model of linking against a fixed pre-compiled standard library
because you don't have to trust that all these newer instructions
wouldn't actually be executed on older CPUs that don't have them.
I love the auto-formatter. Want to lay out your struct literal into
multiple lines? Just add a trailing comma to the end of the last element.
It's very snappy, and a joy to use.
Like every modern programming language, Zig comes with a test framework
built into the language. While it's not all too important for my grand plan
of having one big test that runs a bunch of replays and compares their game
states against the original binary, small tests could still be useful for
protecting gameplay code against accidental changes. It would be great if I
didn't have to evaluate and choose among
the many testing frameworks for C++ and could just use a language
standard.
Package
management is still in its infancy, but it's looking pretty good so far,
resembling Go's decentralized approach of just pointing to a URL but with
specific version selection from the get-go.
However, as a version number of 0.11.0 might already suggest, the whole
experience was then bogged down by quite a lot of issues:
While Zig's C/C++ compilation feature is very
well architected to reuse the C/C++ standard libraries of GCC and MinGW and
thus automatically keeps up with changes to the C++ standard library,
it's ultimately still just a Clang frontend. If you've been working with a
Visual Studio-exclusive codebase – which, as we're going to see below, can
easily happen even if you compile in C++23 mode – you'd now have to
migrate to Clang and Zig in a single step. Obviously, this can't ever
be fixed without Microsoft open-sourcing their C++ compiler. And even then,
supporting a separate set of command-line flags might not be worth it.
The standard library is very poorly documented, especially in the
build-related parts that are meant to attract the C++ audience.
Often, the only documentation is found in blog posts from a few years
ago, with example code written against old Zig versions that doesn't compile
on the newest version anymore. It's all very far from stable.
However, Zig's project generation sub-commands (zig
init-exe and friends) do emit well-documented boilerplate
code? It does make sense for that code to double as a comprehensive example,
but Zig advertises itself as so simple that I didn't even think about
bootstrapping my project with a CLI tool at first – unlike, say, Rust, where
a project always starts with filling out a small form in
Cargo.toml.
There's no progress output for C/C++ compilation? Like, at all?
This hurts especially because compilation times are significantly longer
than they were with Visual Studio. By default, the current Tupfile builds
Shuusou Gyoku in both debug and release configurations simultaneously. If I
fully rebuild everything from a clean cache, Visual Studio finishes such a
build in roughly the same amount of time that Zig takes to compile just a
debug build.
The --global-cache-dir option is only supported by specific
subcommands of the zig CLI rather than being a top-level
setting, and throws an error if used for any other subcommand. Not having a
system-wide way to change it and being forced into writing a wrapper script
for that is fine, but it would be nice if said wrapper script didn't have to
also parse and switch over the subcommand just to figure out whether it is
allowed to append the setting.
compiler-rt still needs a bit of dead code elimination work. As soon as
your program needs a single polyfilled function, you get all of them,
because they get referenced in some exception-related table even if nothing
uses them? Changing the link_eh_frame_hdr option had no
effect.
And that was not the only std.Build.Step.Compile option
that did nothing. Worse, if I just tweaked the options and changed nothing
about the code itself, Zig simply copied a previously built executable
out of its build cache into the output directory, as revealed by the
timestamp on the .EXE. While I am willing to believe that Zig correctly
detects that all these settings would just produce the same binary, I do not
like how this behavior inspires distrust and uncertainty in Zig's build
process as a whole. After all, we still live in a world where clearing
the build cache is way too often the solution for weird problems in
software, especially when using CMake. And it makes sense why it would be:
If you develop a complex system and then try solving the infamously hard
problem of cache invalidation on top, the risk of getting cache invalidation
wrong is, by definition, higher than if that was the only thing your system
did. That's the reason why I like Tup so much: It solely focuses on
getting cache invalidation right, and rather errs on the side of caution by
maybe unnecessarily rebuilding certain files every once in a while because
the compiler may have read from an environment variable that has changed in
the meantime. But this is the one job I expect a build system to do, and Tup
has been delivering for years and has become fundamentally more trustworthy
as a result.
Zig activates Clang's UBSan
in debug builds by default, which executes a program-crashing
UD2 instruction whenever the program is about to rely on
undefined C++ behavior. In theory, that's a great help for spotting hidden
portability issues, but it's not helpful at all if these crashes are
seemingly caused by C++ standard library code?! Without any clear info
about the actual cause, this just turned into yet another annoyance on
top of all the others. Especially because I apparently kept searching for
the wrong terms when I first encountered this issue, and only found
out how to deactivate it after I already decided against Zig.
Also, can we get /PDBALTPATH?
Baking absolute paths from the filesystem of the developer's machine into
released binaries is not only cringe in itself, but can also cause potential
privacy or security accidents.
So for the time being, I still prefer Tup. But give it maybe two or three
years, and I'm sure that Zig will eventually become the best tool for
resurrecting legacy C++ codebases. That is, if the proposed divorce of the
core Zig compiler from LLVMisn't an indication that the
productive parts of the Zig community consider the C/C++ building features
to be "good enough", and are about to de-emphasize them to focus more
strongly on the actual Zig language. Gaining adoption for your new systems
language by bundling it with a C/C++ build system is such a great and unique
strategy, and it almost worked in my case. And who knows, maybe Zig will
already be good enough by the time I get to port PC-98 Touhou to modern
systems.
(If you came from the Zig
wiki, you can stop reading here.)
A few remnants of the Zig experiment still remain in the final delivery. If
that experiment worked out, I would have had to immediately change the
execution encoding to UTF-8, and decompile a few ASM functions exclusive to
the 8-bit rendering mode which we could have otherwise ignored. While Clang
does support inline assembly with Intel syntax via
-fms-extensions, it has trouble with ; comments
and instructions like REP STOSD, and if I have to touch that
code anyway… (The REP STOSD function translated into a single
call to memcpy(), by the way.)
Another smaller issue was Visual Studio's lack of standard library header
hygiene, where #including some of the high-level STL features also includes
more foundational headers that Clang requires to be included separately, but
I've already known about that. Instead, the biggest shocker was that Visual
Studio accepts invalid syntax for a language feature as recent as C++20
concepts:
// Defines the interface of a text rendering session class. To simplify this
// example, it only has a single `Print(const char* str)` method.
template <class T> concept Session = requires(T t, const char* str) {
t.Print(str);
};
// Once the rendering backend has started a new session, it passes the session
// object as a parameter to a user-defined function, which can then freely call
// any of the functions defined in the `Session` concept to render some text.
template <class F, class S> concept UserFunctionForSession = (
Session<S> && requires(F f, S& s) {
{ f(s) };
}
);
// The rendering backend defines a `Prerender()` method that takes the
// aforementioned user-defined function object. Unfortunately, C++ concepts
// don't work like this: The standard doesn't allow `auto` in the parameter
// list of a `requires` expression because it defines another implicit
// template parameter. Nevertheless, Visual Studio compiles this code without
// errors.
template <class T, class S> concept BackendAttempt = requires(
T t, UserFunctionForSession<S> auto func
) {
t.Prerender(func);
};
// A syntactically correct definition would use a different constraint term for
// the type of the user-defined function. But this effectively makes the
// resulting concept unusable for actual validation because you are forced to
// specify a type for `F`.
template <class T, class S, class F> concept SyntacticallyFixedBackend = (
UserFunctionForSession<F, S> && requires(T t, F func) {
t.Prerender(func);
}
);
// The solution: Defining a dummy structure that behaves like a lambda as an
// "archetype" for the user-defined function.
struct UserFunctionArchetype {
void operator ()(Session auto& s) {
}
};
// Now, the session type disappears from the template parameter list, which
// even allows the concrete session type to be private.
template <class T> concept CorrectBackend = requires(
T t, UserFunctionArchetype func
) {
t.Prerender(func);
};
What's this, Visual Studio's infamous delayed template parsing applied to
concepts, because they're templates as well? Didn't
they get rid of that 6 years ago? You would think that we've moved
beyond the age where compilers differed in their interpretation of the core
language, and that opting into a current C++ standard turns off any
remaining antiquated behaviors…
So let's actually get my Tup build scripts ready for compiling
vendored libraries, because the
📝 previous 70 lines of Lua definitely
weren't. For this use case, we'd like to have some notion of distinct build
targets that can have a unique set of compilation and linking flags. We'd
also like to always build them in debug and release versions even if you
only intend to build your actual program in one of those versions – with the
previous system of specifying a single version for all code, Tup would
delete the other one, which forces a time-consuming and ultimately needless
rebuild once you switch to the other version.
The solution I came up with treats the set of compiler command-line options
like a tree whose branches can concatenate new options and/or filter the
versions that are built on this branch. In total, this is my 4th
attempt at writing a compiler abstraction layer for Tup. Since we're
effectively forced to write such layers in Lua, it will always be a
bit janky, but I think I've finally arrived at a solid underlying design
that might also be interesting for others. Hence, I've split off the result
into its own separate
repository and added high-level documentation and a documented example.
And yes, that's a Code Nutrition
label! I've wanted to add one of these ever since I first heard about the
idea, since it communicates nicely how seriously such an open-source project
should be taken. Which, in this case, is actually not all too
seriously, especially since development of the core Tup project has all but
stagnated. If Zig does indeed get better and better at being a Clang
frontend/build system, the only niches left for Tup will be Visual
Studio-exclusive projects, or retrocoding with nonstandard toolchains (i.e.,
ReC98). Quite ironic, given Tup's Unix heritage…
Oh, and maybe general Makefile-like tasks where you just want to run
specific programs. Maybe once the general hype swings back around and people
start demanding proper graph-based dependency tracking instead of just a command runner…
Alright, alternatives evaluated, build system ready, time to include SDL!
Once again, I went for Git submodules, but this time they're held together
by a
batch file that ensures that the intended versions are checked out before
starting Tup. Git submodules have a bad rap mainly because of their
usability issues, and such a script should hopefully work around
them? Let's see how this plays out. If it ends up causing issues after all,
I'll just switch to a Zig-like model of downloading and unzipping a source
archive. Since Windows comes with curl and tar
these days, this can even work without any further dependencies, and will
also remove all the test code bloat.
Compiling SDL from a non-standard build system requires a
bit of globbing to include all the code that is being referenced, as
well as a few linker settings, but it's ultimately not much of a big deal.
I'm quite happy that it was possible at all without pre-configuring a build,
but hey, that's what maintaining a Visual Studio project file does to a
project.
By building SDL with the stock Windows configuration, we then end up with
exactly what the SDL developers want us to use… which is a DLL. You
can statically link SDL, but they really don't want you to do
that. So strongly, in fact, that they not
merely argue how well the textbook advantages of dynamic linking have worked
for them and gamers as a whole, but implemented a whole dynamic API
system that enforces overridable dynamic function loading even in static
builds. Nudging developers to their preferred solution by removing most
advantages from static linking by default… that's certainly a strategy. It
definitely fits with SDL's grassroots marketing, which is very good at
painting SDL as the industry standard and the only reliable way to keep your
game running on all originally supported operating systems. Well, at least
until SDL 3 is so stable that SDL 2 gets deprecated and won't
receive any code for new backends…
However, dynamic linking does make sense if you consider what SDL is.
Offering all those multiple rendering, input, and sound backends is what
sets it apart from its more hip competition, and you want to have all of
them available at any time so that SDL can dynamically select them based on
what works best on a system. As a result, everything in SDL is being
referenced somewhere, so there's no dead code for the linker to eliminate.
Linking SDL statically with link-time code generation just prolongs your
link time for no benefit, even without the dynamic API thwarting any chance
of SDL calls getting inlined.
There's one thing I still don't like about all this, though. The dynamic
API's table references force you to include all of SDL's subsystems in the
DLL even if your game doesn't need some of them. But it does fit with their
intention of having SDL2.dll be swappable: If an older game
stopped working because of an outdated SDL2.dll, it should be
possible for anyone to get that game working again by replacing that DLL
with any newer version that was bundled with any random newer game. And
since that would fail if the newer SDL2.dll was size-optimized
to not include some of the subsystems that the older game required, they
simply removed (or de-prioritized) the possibility altogether.
Maybe that was their train of thought? You can always just use the official Windows
DLL, whose whole point is to include everything, after all. 🤷
So, what do we get in these 1.5 MiB? There are:
renderer backends for Direct3D 9/11/12, regular OpenGL, OpenGL ES 2.0,
Vulkan, and a software renderer,
and audio backends for WinMM, DirectSound, WASAPI, and direct-to-disk
recording.
Unfortunately, SDL 2 also statically references some newer Windows API
functions and therefore doesn't run on Windows 98. Since this build of
Shuusou Gyoku doesn't introduce any new features to the input or sound
interfaces, we can still use pbg's original DirectSound and DirectInput code
for the i586 build to keep it working with the rest of the
platform-independent game logic code, but it will start to lag behind in
features as soon as we add support for SC-88Pro BGM or more sophisticated input
remapping. If we do want to keep this build at the same feature level as
the SDL one, we now have a choice: Do we write new DirectInput and
DirectSound code and get it done quickly but only for Shuusou Gyoku, or do
we port SDL 2 to Windows 98 and benefit all other SDL 2 games as
well? I leave
that for my backers to decide.
Immediately after writing the first bits of actual SDL code to initialize
the library and create the game window, you notice that SDL makes it very
simple to gradually migrate a game. After creating the game window, you can
call SDL_GetWindowWMInfo()
to retrieve HWND and HINSTANCE handles that allow
you to continue using your original DirectDraw, DirectSound, and DirectInput
code and focus on porting one subsystem at a time.
Sadly, D3DWindower can no longer turn SDL's fullscreen mode into a windowed
one, but DxWnd still works, albeit behaving a bit janky and insisting on
minimizing the game whenever its window loses focus. But in exchange, the
game window can surprisingly be moved now! Turns out that the originally
fixed window position had nothing to do with the way the game created its
DirectDraw context, and everything to do with pbg
blocking the Win32 "syscommand" that allows a window to be moved. By
deleting a system menu… seriously?! Now I'm dying to hear the Raymond
Chen explanation for how this behavior dates back to an unfortunate decision
during the Win16 days or something.
As implied by that commit, I immediately backported window movability to the
i586 build.
However, the most important part of Shuusou Gyoku's main loop is its frame
rate limiter, whose Win32 version leaves a bit of room for improvement.
Outside of the uncapped [おまけ] DrawMode, the
original main loop continuously checks whether at least 16 milliseconds have
elapsed since the last simulated (but not necessarily rendered) frame. And
by that I mean continuously, and deliberately without using any of
the Windows system facilities to sleep the process in the meantime, as
evidenced by a commented-out Sleep(1) call. This has two
important effects on the game:
The 60Fps DrawMode actually corresponds to a
frame rate of
(1000 / 16) = 62.5 FPS,
not 60. Since the game didn't account for the missing
2/3 ms to bring the limit down to exactly 60 FPS,
62.5 FPS is Shuusou Gyoku's actual official frame rate in a
non-VSynced setting, which we should also maintain in the SDL port.
Not sleeping the process turns Shuusou Gyoku's frame rate limitation
into a busy-waiting loop, which always uses 100% of a single CPU core just
to wait for the next frame.
Sure, modern computers are fast, but a frame won't ever take an
infinitely fast 0 milliseconds to render. So we still need to take the
current frame time into account.
SDL_Delay()'s documentation says that the wake-up could be
further delayed due to OS scheduling.
To address both of these issues, I went with a base delay time of
15 ms minus the time spent on the current frame, followed by
busy-waiting for the last millisecond to make sure that the next frame
starts on the exact frame boundary. And lo and behold: Even though this
still technically wastes up to 1 ms of CPU time, it still dropped CPU
usage into the 0%-2% range during gameplay on my Intel Core i5-8400T CPU,
which is over 5 years old at this point. Your laptop battery will appreciate
this new build quite a bit.
Time to look at audio then, because it sure looks less complicated than
input, doesn't it? Loading sounds from .WAV file buffers, playing a fixed
number of instances of every sound at a given position within the stereo
field and with optional looping… and that's everything already. The
DirectSound implementation is so straightforward that the most complex part
of its code is the .WAV file parser.
Well, the big problem with audio is actually finding a cross-platform
backend that implements these features in a way that seamlessly works with
Shuusou Gyoku's original files. DirectSound really is the perfect sound API
for this game:
It doesn't require the game code to specify any output sample format.
Just load the individual sound effects in their original format, and
playback just works and sounds correctly.
Its final sound stream seems to have a latency of 10 ms, which is
perfectly fine for a game running at 62.5 FPS. Even 15 ms would be
OK.
Sound effect looping? Specified by passing the
DSBPLAY_LOOPING flag to
IDirectSoundBuffer::Play().
Stereo panning balancing? One method call.
Playing the same sound multiple times simultaneously from a single
memory buffer? One
method call. (It can fail though, requiring you to copy the data after
all.)
Pausing all sounds while the game window is not focused? That's the
default behavior, but it can be equally easily disabled with just
a single per-buffer flag.
Future streaming of waveform BGM? No problem either. Windows Touhou has
always done that, and here's
some code I wrote 12½ years ago that would even work without DirectSound
8's notification feature.
No further binary bloat, because it's part of the operating system.
The last point can't really be an argument against anything, but we'd still
be left with 7 other boxes that a cross-platform alternative would have to
tick. We already picked SDL for our portability needs, so how does its audio
subsystem stack up? Unfortunately, not great:
It's fully DIY. All you get is a single output buffer, and you have to
do all the mixing and effect processing yourself. In other words, it's the
masochistic approach to cross-platform audio.
There are helper functions for resampling and mixing, but the
documentation of the latter is full of FUD. With a disclaimer that so
vehemently discourages the use of this function, what are you supposed to do
if you're newly integrating SDL audio into a game? Hunt for a separate sound
mixing library, even though your only quality goal is parity with stone-age
DirectSound? 🙄
It forces the game to explicitly define the PCM sampling rate, bit
depth, and channel count of the output buffer. You can't
just pass a nullptr to SDL_OpenAudioDevice(),
and if you pass a zeroed SDL_AudioSpec structure, SDL just defaults
to an unacceptable 22,050 Hz sampling rate, regardless of what the
audio device would actually prefer. It took until last year for them to
notice that people would at least like to query the native
format. But of course, this approach requires the backend to actually
provide this information – and since we've seen above that DirectSound
doesn't care, the
DirectSound version of this function has to actually use the more modern
WASAPI, and remains unimplemented if that API is not available.
Standardizing the game on a single sampling rate, bit depth, and channel
count might be a decent choice for games that consistently use a single
format for all its sounds anyway. In that case, you get to do all mixing and
processing in that format, and the audio backend will at most do one final
conversion into the playback device's native format. But in Shuusou Gyoku,
most sound effects use 22,050 Hz, the boss explosion sound effect uses
11,025 Hz, and the future SC-88Pro BGM will obviously use
44,100 Hz. In such a scenario, you would have to pick the highest
sampling rate among all sound sources, and resample any lower-quality sounds
to that rate. But if the audio device uses a different sampling rate, those
lower-quality sounds would get resampled a second time.
I know that this
will be fixed in SDL 3, but that version is still under heavy
development.
Positives? Uh… the callback-based nature means that BGM streaming is
rather trivial, and would even be comparatively less complicated than with
DirectSound. Having a mutex to prevent
writes to your sound instance structures while they're being read by the
audio thread is nice too.
OK, sure, but you're not supposed to use it for anything more than a
single stream of audio. SDL_mixer exists precisely to cover such non-trivial
use cases, and it even supports sound effect looping and panning with just a
single function call! But as far as the rest of the library is concerned, it
manages to be an even bigger disappointment than raw SDL audio:
As it sits on top of SDL's audio subsystem, it still can't just use your
audio device's native sample format.
It only offers a very opinionated system for streaming – and of course,
its opinion is wrong. 😛 The fact that it only supports a single streaming
audio track wouldn't matter all too much if you could switch to another
track at sample precision. But since you can't, you're forced to implement
looping BGM using a single file…
…which brings us to the unfortunate issue of loop point definitions.
And, perhaps most importantly, the complete lack of any way to set them
through the API?! It doesn't take long until you come up with a theory for
why the API only offers a function to retrieve loop points: The
"music" abstraction is so format-agnostic that it even supports MIDI
and tracker formats where a typical loop point in PCM samples doesn't make
sense. Both of these formats already have in-band ways of specifying loop
points in their respective time units. They
might not be standardized, but it's still much better than usual
single-file solutions for PCM streams where the loop point has to be stored
in an out-of-band way – such as in a metadata tag or an entirely separate
file.
Speaking of MIDI, why is it so common among these APIs to not have
any way of specifying the MIDI device? The fact that Windows Vista
removed the Control Panel option for specifying the system-wide default
MIDI output device is no excuse for your API lacking the option as well.
In fact, your MIDI API now needs such a setting more than it was
needed in the Windows XP and 9x days.
Funnily enough, they did once receive a patch for a function to set loop
points which was never upstreamed… and this patch came from
the main developer behind PyTouhou, who needed that feature for obvious
reasons. The world sure is a small place.
As a result, they turned loop points into a property that each
individual format may
or may
not have. Want to loop
MP3 files at sample precision? Tough luck, time to reconvert to another
lossy format. 🙄 This is the exact jank I decided against when I implemented
BGM modding for thcrap back in 2018,
where I concluded that separate intro and
loop files are the way to go.
But OK, we only plan to use FLAC and Ogg Vorbis for the SC-88Pro BGM, for
which SDL_mixer does support loop points in the form of Vorbiscomments,
and hey, we can even pass them at sample accuracy. Sure, it's wrong and
everything, but nothing I couldn't work with…
However, the final straw that makes SDL_mixer unsuitable for Shuusou
Gyoku is its core sound mixing paradigm of distributing all sound effects
onto a fixed number of channels, set to 8
by default. Which raises the quite ridiculous question of how many we
would actually need to cover the maximum amount of sounds that can
simultaneously be played back in any game situation. The theoretic maximum
would be 41, which is the combined sum of individual sound buffer instances
of all 20 original sound effects. The practical limit would surely be a lot
smaller, but we could only find out that one through experiments, which
honestly is quite a silly proposition.
It makes you wonder why they went with this paradigm in the first
place. And sure enough, they actually
use the aforementioned SDL core function for mixing audio. Yes, the
same function whose current documentation advises against using it for
this exact use case. 🙄 What's the argument here? "Sure, 8 is
significantly more than 2, but any mixing artifacts that will occur for
the next 6 sounds are not worrying about, but they get really bad
after the 8th sound, so we're just going to protect you from
that"?
This dire situation made me wonder if SDL was the wrong choice for Shuusou
Gyoku to begin with. Looking at other low-level cross-platform game
libraries, you'll quickly notice that all of them come with mostly
equally capable 2D renderers these days, and mainly differentiate themselves
in minute API details that you'd only notice upon a really close look. raylib is another one of those
libraries and has been getting exceptionally popular in recent years, to the
point of even having more than twice as many GitHub stars as SDL. By
restricting itself to OpenGL, it can even offer an
abstraction for shaders, which we'd really like for the 西方Project lens ball effect.
In the case of raylib's audio system, the lack of sound effect looping is
the minute API detail that would make it annoying to use for Shuusou Gyoku.
But it might be worth a look at how raylib implements all this if it doesn't
use SDL… which turned out to be the best look I've taken in a long time,
because raylib builds on top of miniaudio
which is exactly the kind of audio library I was hoping to find.
Let's check the list from above:
🟢 miniaudio's high-level API initialization defaults to the native
sample format of the playback device. Its internal processing uses 32-bit
floating-point samples and only converts back to the native bit depth as
necessary when writing the final stream into the backend's audio buffer.
WASAPI, for example, never needs any further conversion because it operates
with 32-bit floats as well.
🟢 The final audio stream uses the same 10 ms update period (and
thus, sound effect latency) that I was getting with DirectSound.
🟢 Stereo panning balancing? ma_sound_set_pan(),
although it does require a conversion from Shuusou Gyoku's dB units into a
linear attenuation factor.
🟢 Sound effect looping? ma_sound_set_looping().
🟢 Playing the same sound multiple times simultaneously from a single
memory buffer? Perfectly possible, but requires a bit of digging in the
header to find the best solution. More on that below.
🟢 Future streaming of waveform BGM? Just call
ma_sound_init_from_file() with the
MA_SOUND_FLAG_STREAM flag.
👍 It also comes with a FLAC decoder in the core library and an Ogg
Vorbis one as part of the repo, …
🤩 … and even supports gapless switching between the intro and loop
files via a single declarative call to
ma_data_source_set_next()!
(Oh, and it also has ma_data_set_loop_point_in_pcm_frames()
for anyone who still believes in obviously and objectively
inferior out-of-band loop points.)
🟢 Pausing all sounds while the game window is not focused? It's not
automatic, but adding new functions to the sound interface and calling
ma_engine_stop() and ma_engine_start() does the
trick, and most importantly doesn't cause any samples to be lost in the
process.
🟡 Sound control is implemented in a lock-free way, allowing your main
game thread to call these at any time without causing glitches on the audio
thread. While that looks nice and optimal on the surface, you now have to
either believe in the soundness (ha) of the implementation, or verify that
atomic structure fields actually are enough to not cause any race
conditions (which I did for the calls that Shuusou Gyoku uses, and I didn't
find any). "It's all lock-free, don't worry about it" might be
easier, but I consider SDL's approach of just providing a mutex to
prevent the output callback from running while you mutate the sound state to
actually be simpler conceptually.
🟡 miniaudio adds 247 KB to the binary in its minimum
configuration, a bit more than expected. Some of that is bloat from effect
code that we never use, but it does include backends for all three Windows
audio subsystems (WASAPI, DirectSound, and WinMM).
✅ But perhaps most importantly: It natively supports all modern
operating systems that one could seriously want to port this game to, and
could be easily ported to any other backend, including
SDL.
Oh, and it's written by the same developer who also wrote the best FLAC
library back in 2018. And that's despite them being single-file C libraries,
which I consider to be massively overrated…
The drawback? Similar to Zig, it's only on version 0.11.18, and also focuses
on good high-level documentation at the expense of an API reference. Unlike
Zig though, the three issues I ran into turned out to be actual and fixable
bugs: Two minor
ones related to looping of streamed sounds shorter than 2 seconds which
won't ever actually affect us before we get into BGM modding, and a critical one that
added high-frequency corruption to any mono sound effect during its
expansion to stereo. The latter took days to track down – with symptoms
like these, you'd immediately suspect the bug to lie in the resampler or its
low-pass filter, both of which are so much more of a fickle and configurable
part of the conversion chain here. Compared to that, stereo expansion is so
conceptually simple that you wouldn't imagine anyone getting it wrong.
While the latter PR has been merged, the fix is still only part of the
dev branch and hasn't been properly released yet. Fortunately,
raylib is not affected by this bug: It does currently
ship version 0.11.16 of miniaudio, but its usage of the library predates
miniaudio's high-level API and it therefore uses a different,
non-SSE-optimized code path for its format conversions.
The only slightly tricky part of implementing a miniaudio backend for
Shuusou Gyoku lies in setting up multiple simultaneously playing instances
for each individual sound. The documentation and answers on the issue
tracker heavily push you toward miniaudio's resource manager and its file
abstractions to handle this use case. We surely could turn Shuusou Gyoku's
numeric sound effect IDs into fake file names, but it doesn't really fit the
existing architecture where the sound interface just receives in-memory .WAV
file buffers loaded from the SOUND.DAT packfile.
In that case, this seems to be the best way:
Call ma_decode_memory() to decode from any of the supported
audio formats to a buffer of raw PCM samples. At this point, you can
choose between
decoding into the original format the sound effect is stored in,
which would require it to be converted to the playback format every
time it's played, or
decoding into 32-bit floats (the native bit depth of the miniaudio
engine) and the native sampling rate of the playback device, which
avoids any further resampling and floating-point conversion, but takes
up more memory.
Nowadays, it's not clear at all which of the two approaches is faster.
Does it actually matter if we save the audio thread from doing all those
floating-point operations on every sample? Or is that no longer true these
days because the audio thread is probably running on a different CPU core,
the rest of the game largely doesn't touch the floating-point parts of your
CPU anyway, and you'd rather want to keep sound effects small so that they
can better fit into the CPU cache? That would be an interesting question to
benchmark, but just like the similar text rendering question from the last
blog posts, it doesn't matter for this tiny 2000s retro game. 😌
I went with 2) mainly because it simplified all the debugging I was doing.
At a sampling rate of 48,000 Hz, this increases the memory usage for
all sound effects from 379 KiB to 3.67 MiB. At least I'm not
channel-expanding all sound effects as well here…
We've seen earlier that mono➜stereo expansion
is SSE-optimized, so it's very hard to justify a further doubling of the
memory usage here.
Then, for each instance of the sound, call
ma_audio_buffer_ref_init() to create a reference
buffer with its own playback cursor, and
ma_sound_init_from_data_source() to create a new
high-level sound node that will play back the reference buffer.
As a side effect of hunting that one critical bug in miniaudio, I've now
learned a fair bit about audio resampling in general. You'll probably need
some knowledge about basic
digital signal behavior to follow this section, and that video is still
probably the best introduction to the topic.
So, how could this ever be an issue? The only time I ever consciously
thought about resampling used to be in the context of the Opus codec and its
enforced sampling rate of 48,000 Hz, and how Opus advocates
claim that resampling is a solved problem and nothing to worry about,
especially in the context of a lossy codec. Still, I didn't add Opus to
thcrap's BGM modding feature entirely because the mere thought of having to
downsample to 44,100 Hz in the decoder was off-putting enough. But even
if my worries were unfounded in that specific case: Recording the
Stereo Mix of Shuusou Gyoku's now two audio backends revealed that
apparently not every audio processing chain features an Opus-quality
resampler…
If we take a look at the material that resamplers actually have to work with
here, it quickly becomes obvious why their results are so varied. As
mentioned above, Shuusou Gyoku's sound effects use rather low sampling rates
that are pretty far away from the 48,000 Hz your audio device is most
definitely outputting. Therefore, any potential imaging noise across the
extended high-frequency range – i.e., from the original Nyquist frequencies
of 11,025 Hz/5,512.5 Hz up to the new limit of 24,000 Hz – is
still within the audible range of most humans and can clearly color the
resulting sound.
But it gets worse if the audio data you put into the resampler is
objectively defective to begin with, which is exactly the problem we're
facing with over half of Shuusou Gyoku's sound effects. Encoding them all as
8-bit PCM is definitely excusable because it was the turn of the millennium
and the resulting noise floor is masked by the BGM anyway, but the blatant
clipping and DC offsets definitely aren't:
KEBARI
TAME
LASER
LASER2
BOMB
SELECT
HIT
CANCEL
WARNING
SBLASER
BUZZ
MISSILE
JOINT
DEAD
SBBOMB
BOSSBOMB
ENEMYSHOT
HLASER
TAMEFAST
WARP
Waveforms for all 20 of Shuusou Gyoku's sound effects, in the order they
appear inside SOUND.DAT and with their internal names. We can
see quite an abundance of clipping, as well
as a significant DC
offset in WARNING, BUZZ, JOINT,
SBBOMB, and BOSSBOMB.
Wait a moment, true peaks? Where do those come from? And, equally
importantly, how can we even observe, measure, and store anything
above the maximum amplitude of a digital signal?
The answer to the first question can be directly derived from the Xiph.org
video I linked above: Digital signals are lollipop graphs, not stairsteps as
commonly depicted in audio editing software. Converting them back to an
analog signal involves constructing a continuous curve that passes through
each sample point, and whose frequency components stay below the Nyquist
frequency. And if the amplitude of that reconstructed wave changes too
strongly and too rapidly, the resulting curve can easily overshoot the
maximum digital amplitude of 0
dBFS even if none of the defined samples are above that limit.
So let's store the resampled output as a FLAC file and load it into Audacity
to visualize the clipped peaks… only to find all of them replaced with the
typical kind of clipping distortion? 😕 Turns out that I've stumbled over
the one case where the FLAC format isn't lossless and there's
actually no alternative to .WAV: FLAC just doesn't support
floating-point samples and simply truncates them to discrete integers during
encoding. When we measured inter-sample peaks above, we weren't only
resampling to a floating-point format to avoid any quantization to discrete
integer values, but also to make it possible to store amplitudes beyond the
0 dBFS point of ±1.0 in the first place. Once we lose that ability,
these amplitudes are clipped to the maximum value of the integer bit depth,
and baked into the waveform with no way to get rid of them again. After all,
the resampled file now uses a higher sampling rate, and the clipping
distortion is now a defined part of what the sound is.
Finally, storing a digital signal with inter-sample peaks in a
floating-point format also makes it possible for you to reduce the
volume, which moves these peaks back into the regular, unclipped amplitude
range. This is especially relevant for Shuusou Gyoku as you'll probably
never listen to sound effects at full volume.
Now that we understand what's going on there, we can finally compare the
output of various resamplers and pick a suitable one to use with miniaudio.
And immediately, we see how they fall into two categories:
High-quality resamplers are the ones I described earlier: They cleanly
recreate the signal at a higher sampling rate from its raw frequency
representation and thus add no high-frequency noise, but can lead to
inter-sample peaks above 0 dBFS.
Linear resamplers use much simpler math to merely interpolate
between neighboring samples. Since the newly interpolated samples can only
ever stay within 0 dBFS, this approach fully avoids inter-sample
clipping, but at the expense of adding high-frequency imaging noise that has
to then be removed using a low-pass filter.
miniaudio only comes with a linear resampler – but so does DirectSound as it
turns out, so we can get actually pretty close to how the game sounded
originally:
All of Shuusou Gyoku's sound effects combined and resampled into a
single 48,000 Hz / 32-bit float .WAV file, using GoldWave's File Merger tool. By
converting to 32-bit float first and then resampling, the
conversion preserved the exact frequency range of the original
22,050 Hz and 11,025 Hz files, even despite clipping. There
are small noise peaks across the entire frequency range, but they
only occur at the exact boundary between individual sound effects. These
are a simple result of the discontinuities that naturally occur in the
waveform when concatenating signals that don't start or end at a 0
sample.
As mentioned above, you'll only get this sound out of your DAC at lower
volumes where all of the resampled peaks still fit within 0 dBFS.
But you most likely will have reduced your volume anyway, because these
effects would be ear-splittingly loud otherwise.
The result of converting 1️⃣ into FLAC. The necessary bit depth
conversion from 32-bit float to 16-bit integers clamps any data above
0 dBFS or ±1.0f to the discrete
-32,67832,767, the maximum value of such
an integer. The resulting straight lines at maximum amplitude in the
time domain then turn into distortion across the entire 24,000 Hz
frequency domain, which then remains a part of the waveform even at
lower volumes. The locations of the high-frequency noise exactly match
the clipped locations in the time-domain waveform images above.
The resulting additional distortion can be best heard in
BOSSBOMB, where the low source frequency ensures that any
distortion stays firmly within the hearing range of most humans.
All of Shuusou Gyoku's sound effects as played through DirectSound and
recorded through Stereo Mix. DirectSound also seems to use a linear
low-pass filter that leaves quite a bit of high-frequency noise in the
signals, making these effects sound crispier than they should be.
Depending on where you stand, this is either highly inaccurate and
something that should be fixed, or actually good because the sound
effects really benefit from that added high end. I myself am definitely
in the latter camp – and hey, this sound is the result of original game
code, so it is accurate at least in that regard.
All of Shuusou Gyoku's sound effects as converted by miniaudio and
directly saved to a file, with the same low-pass filter setting used in
the P0256 build. This first-order low-pass filter is a decent
approximation of DirectSound's resampler, even though it sounds slightly
crispier as the high-frequency noise is boosted a little further. By
default, miniaudio would use a 4th-order low-pass filter, so
this is the second-lowest resampling quality you can get, short of
disabling the low-pass filter altogether.
Conversion results when using miniaudio's 8th-order low-pass
filter for resampling, the highest quality supported. This is the
closest we can get to the reference conversion without using a custom
resampler. If we do want to go for perfect accuracy though, we might as
well go
for 1️⃣ directly?
These spectrum images were initially created using ffmpeg's -lavfi
showspectrumpic=mode=combined:s=1280x720 filter. The samples
appear in the same order as in the waveform above.
And yes, these are indeed the first videos on this blog to have sound! I
spent another push on preparing the
📝 video conversion pipeline for audio
support, and on adding the highly important volume control to the player.
Web video codecs only support lossy audio, so the sound in these videos will
not exactly match the spectrum image, but the lossless source files do
contain the original audio as uncompressed PCM streams.
Compared to that whole mess of signals and noise, keyboard and joypad input
is indeed much simpler. Thanks to SDL, it's almost trivial, and only
slightly complicated because SDL offers two subsystems with seemingly
identical APIs:
SDL_GameController provides a consistent interface for the typical kind
of modern gamepad with two analog sticks, a D-pad, and at least 4 face and 2
shoulder buttons. This API is implemented by simply combining SDL_Joystick
with a
long list of mappings for specific controllers, and therefore doesn't
work with joypads that don't match this standard.
According
to SDL, this is what a "game controller" looks like. Here's
the source of the SVG.
To match Shuusou Gyoku's original WinMM backend, we'd ideally want to keep
the best aspects from both APIs but without being restricted to
SDL_GameController's idea of a controller. The Joy
Pad menu just identifies each button with a numeric ID, so
SDL_Joystick would be a natural fit. But what do we do about directional
controls if SDL_Joystick doesn't tell us which joypad axes correspond to the
X and Y directions, and we don't have the SDL-recommended configuration UI yet?
Doing that right would also mean supporting
POV hats and D-pads, after all… Luckily, all joypads we've tested map
their main X axis to ID 0 and their main Y axis to ID 1, so this seems like
a reasonable default guess.
The necessary consolidation of the game's original input handling uncovered
several minor bugs around the High Score and Game Over screen that I
sufficiently described in the release notes of the new build. But it also
revealed an interesting detail about the Joy Pad
screen: Did you know that Shuusou Gyoku lets you unbind all these
actions by pressing more than one joypad button at the same time? The
original game indicated unbound actions with a [Button
0] label, which is pretty confusing if you have ever programmed
anything because you now no longer know whether the game starts numbering
buttons at 0 or 1. This is now communicated much more clearly.
ESC is not bound to any joypad button in
either screenshot, but it's only really obvious in the P0256
build.
With that, we're finally feature-complete as far as this delivery is
concerned! Let's send a build over to the backers as a quick sanity check…
a~nd they quickly found a bug when running on Linux and Wine. When holding a
button, the game randomly stops registering directional inputs for a short
while on some joypads? Sounds very much like a Wine bug, especially if the
same pad works without issues on Windows.
And indeed, on certain joypads, Wine maps the buttons to completely
different and disconnected IDs, as if it simply invents new buttons or axes
to fill the resulting gaps. Until we can differentiate joypad bindings
per controller, it's therefore unlikely that you can use the same joypad
mapping on both Windows and Linux/Wine without entering the Joy Pad menu and remapping the buttons every time you
switch operating systems.
Still, by itself, this shouldn't cause any issues with my SDL event handling
code… except, of course, if I forget a break; in a switch case.
🫠
This completely preventable implicit fallthrough has now caused a few hours
of debugging on my end. I'd better crank up the warning level to keep this
from ever happening again. Opting into this specific warning also revealed
why we haven't been getting it so far: Visual Studio did gain a whole host
of new warnings related to the C++ Core
Guidelines a while ago, including the one I
was looking for, but actually getting the compiler to throw these
requires activating
a separate static analysis mode together with a plugin, which
significantly slows down build times. Therefore I only activate them for
release builds, since these already take long enough.
Since all that input debugging already started a 5th push, I
might as well fill that one by restoring the original screenshot feature.
After all, it's triggered by a key press (and is thus related to the input
backend), reads the contents of the frame buffer (and is thus related to the
graphics backend), and it honestly looks bad to have this disclaimer in the
release notes just because we're one small feature away from 100% parity
with pbg's original binary.
Coincidentally, I had already written code to save a DirectDraw surface to a
.BMP file for all the debugging I did in the last delivery, so we were
basically only missing filename generation. Except that Shuusou
Gyoku's original choice of mapping screenshots to the PrintScreen key did
not age all too well:
And as of Windows 11, the OS takes full control of the key by binding it
to the Snipping Tool by default, complete with a UI that politely steals
focus when hitting that key.
As a result, both Arandui and I independently arrived at the
idea of remapping screenshots to the P key, which is the same screenshot key
used by every Windows Touhou game since TH08.
The rest of the feature remains unchanged from how it was in pbg's original
build and will save every distinct frame rendered by the game (i.e., before
flipping the two framebuffers) to a .BMP file as long as the P key is being
held. At a 32-bit color depth, these screenshots take up 1.2 MB per
frame, which will quickly add up – especially since you'll probably hold the
P key for more than 1/60 of a second and therefore end
up saving multiple frames in a row. We should probably compress
them one day.
Since I already translated some of Shuusou Gyoku's ASM code to C++ during
the Zig experiment, it made sense to finish the fifth push by covering the
rest of those functions. The integer math functions are used all throughout
the game logic, and are the main reason why this goal is important for a
Linux port, or any port to a 64-bit architecture for that matter. If you've
ever read a micro-optimization-related blog post, you'll know that hand-written ASM is a great recipe that often results in the finest jank, and the game's square root function definitely delivers in that regard, right out of the gate.
What slightly differentiates this algorithm from the typical definition of
an integer
square root is that it rounds up: In real numbers, √3 is
≈ 1.73, so isqrt(3) returns 2 instead of 1. However, if
the result is always rounded down, you can determine whether you have to
round up by simply squaring the calculated root and comparing it to the radicand. And even that
is only necessary if the difference between the two doesn't naturally fall
out of the algorithm – which is what also happens with Shuusou Gyoku's
original ASM code, but pbg
didn't realize this and squared the result regardless.
That's one suboptimal detail already. Let's call the original ASM function
in a loop over the entire supported range of radicands from 0 to
231 and produce a list of results that I can verify my C++
translation against… and watch as the function's linear time complexity with
regard to the radicand causes the loop to run for over 15 hours on my
system. 🐌 In a way, I've found the literal opposite of Q_rsqrt()
here: Not fast, not inverse, no bit hacks, and surely without the
awe-inspiring kind of WTF.
I really didn't want to run the same loop over a
literal C++ translation of the same algorithm afterward. Calculating
integer square roots is a common problem with lots of solutions, so let's
see if we can go better than linear.
And indeed, Wikipedia
also has a bitwise algorithm that runs in logarithmic time, uses only
additions, subtractions, and bit shifts, and even ends up with an error term
that we can use to round up the result as necessary, without a
multiplication. And this algorithm delivers the exact same results over the
exact same range in… 50 seconds. 🏎️ And that's with the I/O to print
the first value that returns each of the 46,341 different square root
results.
"But wait a moment!", I hear you say. "Why are you bothering with
an integer square root algorithm to begin with? Shouldn't good old
round(sqrt(x)) from <math.h> do the trick
just fine? Our CPUs have had SSE for a long time, and this probably compiles
into the single SQRTSD instruction. All that extra
floating-point hardware might mean that this instruction could even run in
parallel with non-SSE code!"
And yes, all of that is technically true. So I tested it, and my very
synthetic and constructed micro-benchmark did indeed deliver the same
results in… 48 seconds. That's not enough of a
difference to justify breaking the spirit of treating the FPU as lava that
permeates Shuusou Gyoku's code base. Besides, it's not used for that much to
begin with:
pre-calculating the 西方Project lens ball effect
the fade animation when entering and leaving stages
rendering the circular part of stationary lasers
pulling items to the player when bombing
After a quick C++ translation of the RNG function that spells out a 32-bit
multiplication on a 32-bit CPU using 16-bit instructions, we reach the final
pieces of ASM code for the 8-bit atan2() and trapezoid
rendering. These could actually pass for well-written ASM code in how they
express their 64-bit calculations: atan8() prepares its 64-bit
dividend in the combined EDX and EAX registers in
a way that isn't obvious at all from a cursory look at the code, and the
trapezoid functions effectively use Q32.32 subpixels. C++ allows us to
cleanly model all these calculations with 64-bit variables, but
unfortunately compiles the divisions into a call to a comparatively much
more bloated 64-bit/64-bit-division polyfill function. So yeah, we've
actually found a well-optimized piece of inline assembly that even Visual
Studio 2022's optimizer can't compete with. But then again, this is all
about code generation details that are specific to 32-bit code, and it
wouldn't be surprising if that part of the optimizer isn't getting much
attention anymore. Whether that optimization was useful, on the other hand…
Oh well, the new C++ version will be much more efficient in 64-bit builds.
And with that, there's no more ASM code left in Shuusou Gyoku's codebase,
and the original DirectXUTYs directory is slowly getting
emptier and emptier.
Phew! Was that everything for this delivery? I think that was everything.
Here's the new build, which checks off 7 of the 15 remaining portability
boxes:
Next up: Taking a well-earned break from Shuusou Gyoku and starting with the
preparations for multilingual PC-98 Touhou translatability by looking at
TH04's and TH05's in-game dialog system, and definitely writing a shorter
blog post about all that…
Stripe is now
properly integrated into this website as an alternative to PayPal! Now, you
can also financially support the project if PayPal doesn't work for you, or
if you prefer using a
provider out of Stripe's greater variety. It's unfortunate that I had to
ship this integration while the store is still sold out, but the Shuusou
Gyoku OpenGL backend has turned out way too complicated to be finished next
to these two pushes within a month. It will take quite a while until the
store reopens and you all can start using Stripe, so I'll just link back to
this blog post when it happens.
Integrating Stripe wasn't the simplest task in the world either. At first,
the Checkout API
seems pretty friendly to developers: The entire payment flow is handled on
the backend, in the server language of your choice, and requires no frontend
JavaScript except for the UI feedback code you choose to write. Your
backend API endpoint initiates the Stripe Checkout session, answers with a
redirect to Stripe, and Stripe then sends a redirect back to your server if
the customer completed the payment. Superficially, this server-based
approach seems much more GDPR-friendly than PayPal, because there are no
remote scripts to obtain consent for. In reality though, Stripe shares
much more potential personal data about your credit card or bank
account with a merchant, compared to PayPal's almost bare minimum of
necessary data.
It's also rather annoying how the backend has to persist the order form
information throughout the entire Checkout session, because it would
otherwise be lost if the server restarts while a customer is still busy
entering data into Stripe's Checkout form. Compare that to the PayPal
JavaScript SDK, which only POSTs back to your server after the
customer completed a payment. In Stripe's case, more JavaScript actually
only makes the integration harder: If you trigger the initial payment
HTTP request from JavaScript, you will have
to improvise a bit to avoid the CORS error when redirecting away to a
different domain.
But sure, it's all not too bad… for regular orders at least. With
subscriptions, however, things get much worse. Unlike PayPal, Stripe
kind of wants to stay out of the way of the payment process as much as
possible, and just be a wrapper around its supported payment methods. So if
customers aren't really meant to register with Stripe, how would they cancel
their subscriptions?
Answer: Through
the… merchant? Which I quite dislike in principle, because why should
you have to trust me to actually cancel your subscription after you
requested it? It also means that I probably should add some sort of UI for
self-canceling a Stripe subscription, ideally without adding full-blown user
accounts. Not that this solves the underlying trust issue, but it's more
convenient than contacting me via email or, worse, going through your bank
somehow. Here is how my solution works:
When setting up a Stripe subscription, the server will generate a random
ID for authentication. This ID is then used as a salt for a hash
of the Stripe subscription ID, linking the two without storing the latter on
my server.
The thank you page, which is parameterized with the Stripe
Checkout session ID, will use that ID to retrieve the subscription
ID via an API call to Stripe, and display it together with the above
salt. This works indefinitely – contrary to what the expiry field in the
Checkout session object suggests, Stripe sessions are indeed stored
forever. After all, Stripe also displays this session information in a
merchant's transaction log with an excessive amount of detail. It might have
been better to add my own expiration system to these pages, but this had
been taking long enough already. For now, be aware that sharing the link to
a Stripe thank you page is equivalent to sharing your subscription
cancellation password.
The salt is then used as the key for a subscription management page. To
cancel, you visit this page and enter the Stripe subscription ID to confirm.
The server then checks whether the salt and subscription ID pair belong to
each other, and sends the actual cancellation
request back to Stripe if they do.
I might have gone a bit overboard with the crypto there, but I liked the
idea of not storing any of the Stripe session IDs in the server database.
It's not like that makes the system more complex anyway, and it's nice to
have a separate confirmation step before canceling a subscription.
But even that wasn't everything I had to keep in mind here. Once you
switch from test to production mode for the final tests, you'll notice that
certain SEPA-based
payment providers take their sweet time to process and activate new
subscriptions. The Checkout session object even informs you about that, by
including a payment status field. Which initially seems just like
another field that could indicate hacking attempts, but treating it as such
and rejecting any unpaid session can also reject perfectly valid
subscriptions. I don't want all this control… 🥲
Instead, all I can do in this case is to tell you about it. In my test, the
Stripe dashboard said that it might take days or even weeks for the initial
subscription transaction to be confirmed. In such a case, the respective
fraction of the cap will unfortunately need to remain red for that entire time.
And that was 1½ pushes just to replicate the basic functionality of a simple
PayPal integration with the simplest type of Stripe integration. On the
architectural site, all the necessary refactoring work made me finally
upgrade my frontend code to TypeScript at least, using the amazing esbuild to handle transpilation inside
the server binary. Let's see how long it will now take for me to upgrade to
SCSS…
With the new payment options, it makes sense to go for another slight price
increase, from up to per push.
The amount of taxes I have to pay on this income is slowly becoming
significant, and the store has been selling out almost immediately for the
last few months anyway. If demand remains at the current level or even
increases, I plan to gradually go up to by the end
of the year. 📝 As📝 usual,
I'm going to deliver existing orders in the backlog at the value they were
originally purchased at. Due to the way the cap has to be calculated, these
contributions now appear to have increased in value by a rather awkward
13.33%.
This left ½ of a push for some more work on the TH01 Anniversary Edition.
Unfortunately, this was too little time for the grand issue of removing
byte-aligned rendering of bigger sprites, which will need some additional
blitting performance research. Instead, I went for a bunch of smaller
bugfixes:
ANNIV.EXE now launches ZUNSOFT.COM if
MDRV98 wasn't resident before. In hindsight, it's completely obvious
why this is the right thing to do: Either you start
ANNIV.EXE directly, in which case there's no resident
MDRV98 and you haven't seen the ZUN Soft logo, or you have
made a single-line edit to GAME.BAT and replaced
op with anniv, in which case MDRV98 is
resident and you have seen the logo. These are the two
reasonable cases to support out of the box. If you are doing
anything else, it shouldn't be that hard to adjust though?
You might be wondering why I didn't just include all code of
ZUNSOFT.COM inside ANNIV.EXE together with
the rest of the game. The reason: ZUNSOFT.COM has
almost nothing in common with regular TH01 code. While the rest of
TH01 uses the custom image formats and bad rendering code I
documented again and again during its RE process,
ZUNSOFT.COM fully relies on master.lib for everything
about the bouncing-ball logo animation. Its code is much closer to
TH02 in that respect, which suggests that ZUN did in fact write this
animation for TH02, and just included the binary in TH01 for
consistency when he first sold both games together at Comiket 52.
Unlike the 📝 various bad reasons for splitting the PC-98 Touhou games into three main executables,
it's still a good idea to split off animations that use a completely
different set of rendering and file format functions. Combined with
all the BFNT and shape rendering code, ZUNSOFT.COM
actually contains even more unique code than OP.EXE,
and only slightly less than FUUIN.EXE.
The optional AUTOEXEC.BAT is now correctly encoded in
Shift-JIS instead of accidentally being UTF-8, fixing the previous
mojibake in its final ECHO line.
The command-line option that just adds a stage selection without
other debug features (anniv s) now works reliably.
This one's quite interesting because it only ever worked
because of a ZUN bug. From a superficial look at the code, it
shouldn't: While the presence of an 's' branch proves
that ZUN had such a mode during development, he nevertheless forgot
to initialize the debug flag inside the resident structure within
this branch. This mode only ever worked because master.lib's
resdata_create() function doesn't clear the resident
structure after allocation. If anything on the system previously
happened to write something other than 0x00,
0x01, or 0x03 to the specific byte that
then gets repurposed as the debug mode flag, this lack of
initialization does in fact result in a distinct non-test and
non-debug stage selection mode.
This is what happens on a certain widely circulated .HDI copy of
TH01 that boots MS-DOS 3.30C. On this system, the memory that
master.lib will allocate to the TH01 resident structure was
previously used by DOS as stack for its kernel, which left the
future resident debug flag byte at address 9FF6:0012 at
a value of 0x12. This might be the entire reason why
game s is even widely documented to trigger a stage
selection to begin with – on the widely circulated TH04 .HDI that
boots MS-DOS 6.20, or on DOSBox-X, the s parameter
doesn't work because both DOS systems leave the resident debug flag
byte at 0x00. And since ANNIV.EXE pushes
MDRV98 into that area of conventional DOS RAM, anniv s
previously didn't work even on MS-DOS 3.30C.
Both bugs in the
📝 1×1 particle system during the Mima fight
have been fixed. These include the off-by-one error that killed off the
very first particle on the 80th
frame and left it in VRAM, and, just like every other entity type, a
replacement of ZUN's EGC unblitter with the new pixel-perfect and fast
one. Until I've rearchitected unblitting as a whole, the particles will
now merely rip barely visible 1×1 holes into the sprites they overlap.
The bomb value shown in the lowest line of the in-game
debug mode output is now right-aligned together with the rest of the
values. This ensures that the game always writes a consistent number
of characters to TRAM, regardless of the magnitude of the
bomb value, preventing the seemingly wrong
timer values that appeared in the original game
whenever the value of the bomb variable changed to a
lower number of digits:
Finally, I've streamlined VRAM page access changes, which allowed me to
consistently replace ZUN's expensive function call with the optimal two
inlined x86 instructions. Interestingly, this change alone removed
2 KiB from the binary size, which is almost all of the difference
between 📝 the P0234-1 release and this
one. Let's see how much longer we can make each new release of
ANNIV.EXE smaller than the previous one.
The final point, however, raised the question of what we're now going to do
about
📝 a certain issue in the 地獄/Jigoku Bad Ending.
ZUN's original expensive way of switching the accessed VRAM page was the
main reason behind the lag frames on slower PC-98 systems, and
search-replacing the respective function calls would immediately get us to
the optimized version shown in that blog post. But is this something we
actually want? If we wanted to retain the lag, we could surely preserve that
function just for this one instance… The discovery of this issue
predates the clear distinction between bloat, quirks, and bugs, so it makes
sense to first classify what this issue even is. The distinction comes all
down to observability, which I defined as changes to rendered frames
between explicitly defined frame boundaries. That alone would be enough to
categorize any cause behind lag frames as bloat, but it can't hurt to be
more explicit here.
Therefore, I now officially judge observability in terms of an infinitely
fast PC-98 that can instantly render everything between two explicitly
defined frames, and will never add additional lag frames. If we plan to port
the games to faster architectures that aren't bottlenecked by disappointing
blitter chips, this is the only reasonable assumption to make, in my
opinion: The minimum system requirements in the games' README files are
minimums, after all, not recommendations. Chasing the exact frame
drop behavior that ZUN must have experienced during the time he developed
these games can only be a guessing game at best, because how can we know
which PC-98 model ZUN actually developed the games on? There might even be
more than one model, especially when it comes to TH01 which had been in
development for at least two years before ZUN first sold it. It's also not
like any current PC-98 emulator even claims to emulate the specific timing
of any existing model, and I sure hope that nobody expects me to import a
bunch of bulky obsolete hardware just to count dropped frames.
That leaves the tearing, where it's much more obvious how it's a bug. On an
infinitely fast PC-98, the ドカーン
frame would never be visible, and thus falls into the same category as the
📝 two unused animations in the Sariel fight.
With only a single unconditional 2-frame delay inside the animation loop, it
becomes clear that ZUN intended both frames of the animation to be displayed
for 2 frames each:
No tearing, and 34 frames in total for the first of the two
instances of this animation.
Next up: Taking the oldest still undelivered push and working towards TH04
position independence in preparation for multilingual translations. The
Shuusou Gyoku OpenGL backend shouldn't take that much longer either,
so I should have lots of stuff coming up in May afterward.
Yes, I'm still alive. This delivery was just plagued by all of the worst
luck: Data loss, physical hard drive failure, exploding phone batteries,
minor illness… and after taking 4 weeks to recover from all of that, I had
to face this beast of a task. 😵
Turns out that neither part of improving video performance and usability on
this blog was particularly easy. Decently encoding the videos into all
web-supported formats required unexpected trade-offs even for the low-res,
low-color material we are working with, and writing custom video player
controls added the timing precision resistance of HTML
<video> on top of the inherent complexity of frontend web
development. Why did this need to be 800 lines of commented JavaScript and
200 lines of commented CSS, and consume almost more than 5 pushes?!
Apparently, the latest price increase also seemed to have raised the minimum
level of acceptable polish in my work, since that's more than the maximum of
3.67 pushes it should have taken. To fund the rest, I stole some of the
reserved JIS trail word rendering research pushes, which means that the next
towards anything will go back towards that goal.
The codec situation is especially sad because it seems like so much of a
solved problem. ZMBV, the lossless capture codec introduced by DOSBox, is
both very well suited for retro game footage and remarkably simple too:
DOSBox-X's implementation of both an encoder and decoder comes in at under
650 lines of C++, excluding the Deflate implementation. Heck, the AVI
container around the codec is more complicated to write than the
compressed video data itself, and AVI is already the easiest choice you have
for a widely supported video container format.
Currently, this blog contains 9:02 minutes of video across 86 files, with a
total frame count of 24,515. In case this post attracts a general video
encoding audience that isn't familiar with what I'm encoding here: The
maximum resolution is 640×400, and most of the video uses 16 colors, with
some parts occasionally using more. With ZMBV, the lossless source files
take up 43.8 MiB, and that's even with AVI's infamously bad
overhead. While you can always spend more time on any compression task and
precisely tune your algorithm to match your source data even better,
43.8 MiB looks like a more than reasonable amount for this type of
content.
Especially compared with what I actually have to ship here, because sadly,
ZMBV is not supported by browsers. 😔 Writing a WebAssembly player for ZMBV
would have certainly been interesting, but it already took 5 pushes to get
to what we have now. So, let's instead shell out to ffmpeg and build a
pipeline to convert ZMBV to the ill-suited codecs supported by web browsers,
replacing the previously committed VP9 and VP8 files. From that point, we
can then look into AV1, the latest and greatest web-supported video codec,
to save some additional bandwidth.
But first, we've got to gather all the ZMBV source files. While I was
working on the 📝 2022-07-10 blog post, I
noticed some weirdly washed-out colors in the converted videos, leading to
the shocking realization that my previous, historically grown conversion
script didn't actually encode in a lossless way. 😢 By extension,
this meant that every video before that post could have had minor
discolorations as well.
For the majority of videos, I still had the original ZMBV capture files
straight out of DOSBox-X, and reproducing the final videos wasn't too big of
a deal. For the few cases where I didn't, I went the extra mile, took the
VP9 files, and manually fixed up all the minor color errors based on
reference videos from the same gameplay stage. There might be a huge ffmpeg
command line with a complicated filter graph to do the job, but for such a
small 4-digit number of frames, it is much more straightforward to just dump
each frame as an image and perform the color replacement with ImageMagick's
-opaque and -fill options.
So, time to encode our new definite collection of source files into AV1, and
what the hell, how slow is this codec? With ffmpeg's
libaom-av1, fully encoding all 86 videos takes almost 9
hours on my mid-range
development system, regardless of the quality selected.
But sure, the encoded videos are managed by a cache, and this obviously only
needs to be done once. If the results are amazing, they might even justify
these glacial encoding speeds. Unfortunately, they don't: In its lossless
-crf 0 mode, AV1 performs even worse than VP9, taking up
222 MiB rather than 182 MiB. It might not sound bad now,
but as we're later going to find out, we want to have a lot of
keyframes in these videos, which will blow up video sizes even further.
So, time to go lossy and maybe take a deep dive into AV1 tuning? Turns out
that it only gets worse from there:
The alternative libsvtav1 encoder is fast and creates small
files… but even on the highest-quality settings, -crf 0 and
-qp 0, the video quality resembled the terrible x264 YUV420P
format that Twitter enforces on uploaded videos.
I don't remember the librav1e results, but they sure
weren't convincing either.
libaom-av1's -usage realtime option is a
complete joke. 771 MiB for all videos, and it doesn't even compress
in real time on my system, more like 2.5× real-time. For comparison,
a certain stone-age technology by the name of "animated GIF" would take
54.3 MiB, encode in sub-realtime (0.47×), and the only necessary tuning
you need is an easily
googled palette generation and usage filter. Why can't I just use
those in a <video> tag?! These results have
clearly proven the top-voted just use modern video codecs Stack
Overflow answers wrong.
What you're actually supposed to do is to drop -cpu-used to
maybe 2 or 3, and then selectively add back prediction filters that suit
your type of content. In our case, these are
and maybe others, depending on much time you want to waste.
Because that's what all this tuning ended up being: a complete waste of
time. No matter which tuning options I tried, all they did was cut down
encoding time in exchange for slightly larger files on average. If there is
a magic tuning option that would suddenly cause AV1 to maybe even beat ZMBV,
I haven't found it. Heck, at particularly low settings,
-enable-intrabc even caused blocky glitches with certain pellet
patterns that looked like the internal frame block hashes were colliding all
over the place. Unfortunately, I didn't save the video where it happened.
So yeah, if you've already invested the computation time and encoded your
content by just specifying a -crf value and keeping the
remaining settings at their time-consuming defaults, any further tuning will
make no difference. Which is… an interesting choice from a usability
perspective. I would have expected the exact
opposite: default to a reasonably fast and efficient profile, and leave the
vast selection of tuning options for those people to explore who do
want to wait 5× as long for their encoder for that additional 5% of
compression efficiency. On the other hand, that surely is one way to get
people to extensively study your glorious engineering efforts, I guess? You
know what would maybe even motivate people to intrinsically do that?
Good documentation, with examples of the intent behind every option and its
optimal use case. Nobody needs long help strings that just spell out all of
the abbreviations that occur in the name of the option…
But hey, that at least means there's no reason to not use anything but ZMBV
for storing and archiving the lossless source files. Best compression
efficiency, encodes in real-time, and the files are much easier to edit.
OK, end of rant. To understand why anyone could be hyped about AV1 to begin
with, we just have to compare it to VP9, not to ZMBV. In that light, AV1
is pretty impressive even at -crf 1, compressing all 86
videos to 68.9 MiB, and even preserving 22.3% of frames completely
losslessly. The remaining frames exhibit the exact kind of quality loss
you'd want for retro game footage: Minor discoloration in individual pixels,
so minuscule that subtracting the encoded image from the source yields an
almost completely black image. Even after highlighting the errors by
normalizing such a difference image, they are barely visible even if you
know where to look. If "compressed PNG size of the normalized difference
between ZMBV and AV1 -crf 1" is a useful metric, this would be
its median frame among the 77.7% of non-lossless frames:
Whether you can actually spot the difference is pretty much down to the
glass between the physical pixels and your eyes. In any case, it's very
hard, even if you know where to look. As far as I'm concerned, I can
confidently call this "visually lossless", and it's definitely good enough
for regular watching and even single-frame stepping on this blog.
Since the appeal of the original lossless files is undeniable though, I also
made those more easily available. You can directly download the one for the
currently active video with the ⍗ button in the new video player – or directly
get all of them from the Git repository if you don't like clicking.
Unfortunately, even that only made up for half of the complexity in this
pipeline. As impressive as the AV1 -crf 1 result may be, it
does in fact come with the drawback of also being impressively heavy to
decode within today's browsers. Seeking is dog slow, with even the latencies
for single-frame stepping being way beyond what I'd consider
tolerable. To compensate, we have to invest another 78 MiB into turning
every 10th frame into a keyframe until single-stepping through an
entire video becomes as fast as it could be on my system.
But fine, 146 MiB, that's still less than the 178 MiB that the old
committed VP9 files used to take up. However, we still want to support VP9
for older browsers, older
hardware, and people who use Safari. And it's this codec where keyframes
are so bad that there is no clear best solution, only compromises. The main
issue: The lower you turn VP9's -crf value, the slower the
seeking performance with the same number of keyframes. Conversely,
this means that raising quality also requires more keyframes for the same
seeking performance – and at these file sizes, you really don't want to
raise either. We're talking 1.2 GiB for all 86 videos at
-crf 10 and -g 5, and even on that configuration,
seeking takes 1.3× as long as it would in the optimal case.
Thankfully, a full VP9 encode of all 86 videos only takes some 30 minutes as
opposed to 9 hours. At that speed, it made sense to try a larger number of
encoding settings during the ongoing development of the player. Here's a
table with all the trials I've kept:
Codec
-crf
-g
Other parameters
Total size
Seek time
VP9
32
20
-vf format=yuv420p
111 MiB
32 s
VP8
10
30
-qmin 10 -qmax 10 -b:v 1G
120 MiB
32 s
VP8
7
30
-qmin 7 -qmax 7 -b:v 1G
140 MiB
32 s
AV1
1
10
146 MiB
32 s
VP8
10
20
-qmin 10 -qmax 10 -b:v 1G
147 MiB
32 s
VP8
6
30
-qmin 6 -qmax 6 -b:v 1G
149 MiB
32 s
VP8
15
10
-qmin 15 -qmax 15 -b:v 1G
177 MiB
32 s
VP8
10
10
-qmin 10 -qmax 10 -b:v 1G
225 MiB
32 s
VP9
32
10
-vf format=yuv422p
329 MiB
32 s
VP8
0-4
10
-qmin 0 -qmax 4 -b:v 1G
376 MiB
32 s
VP8
5
30
-qmin 5 -qmax 5 -b:v 1G
169 MiB
33 s
VP9
63
40
47 MiB
34 s
VP9
32
20
-vf format=yuv422p
146 MiB
34 s
VP8
4
30
-qmin 0 -qmax 4 -b:v 1G
192 MiB
34 s
VP8
4
40
-qmin 4 -qmax 4 -b:v 1G
168 MiB
35 s
VP9
25
20
-vf format=yuv422p
173 MiB
36 s
VP9
15
15
-vf format=yuv422p
252 MiB
36 s
VP9
32
25
-vf format=yuv422p
118 MiB
37 s
VP9
20
20
-vf format=yuv422p
190 MiB
37 s
VP9
19
21
-vf format=yuv422p
187 MiB
38 s
VP9
32
10
553 MiB
38 s
VP9
32
10
-tune-content screen
553 MiB
VP9
32
10
-tile-columns 6 -tile-rows 2
553 MiB
VP9
15
20
-vf format=yuv422p
207 MiB
39 s
VP9
10
5
1210 MiB
43 s
VP9
32
20
264 MiB
45 s
VP9
32
20
-vf format=yuv444p
215 MiB
46 s
VP9
32
20
-vf format=gbrp10le
272 MiB
49 s
VP9
63
24 MiB
67 s
VP8
0-4
-qmin 0 -qmax 4 -b:v 1G
119 MiB
76 s
VP9
32
107 MiB
170 s
The bold rows correspond to the final encoding choices that
are live right now. The seeking time was measured by holding → Right on
the 📝 cheeto dodge strategy video.
Yup, the compromise ended up including a chroma subsampling conversion to
YUV422P. That's the one thing you don't want to do for retro pixel
graphics, as it's the exact cause behind washed-out colors and red fringing
around edges:
The worst example of chroma subsampling in a VP9-encoded file according
to the above metric, from frame 130 (0-based) of
📝 Sariel's restored leaf "spark" animation,
featuring smeared-out contours and even an all-around darker image,
blowing up the image to a whopping 3653 colors. It's certainly an
aesthetic.
But there simply was no satisfying solution around the ~200 MiB mark
with RGB colors, and even this compromise is still a disappointment in both
size and seeking speed. Let's hope that Safari
users do get AV1 support soon… Heck, even VP8, with its exclusive
support for YUV420P, performs much better here, with the impact of
-crf on seeking speed being much less pronounced. Encoding VP8
also just takes 3 minutes for all 86 videos, so I could have experimented
much more. Too bad that it only matters for really ancient systems…
Two final takeaways about VP9:
-tune-content screen and the tile options make no
difference at all.
All results used two-pass encoding. VP9 is the only codec where two
passes made a noticeable difference, cutting down the final encoded size
from 224 MiB to 207 MiB. For AV1, compression even seems to be
slightly worse with two passes, yielding 154,201,892 bytes rather than the
153,643,316 bytes we get with a single pass. But that's a difference of
0.36%, and hardly significant.
Alright, now we're done with codecs and get to finish the work on the
pipeline with perhaps its biggest advantage. With a ffmpeg conversion
infrastructure in place, we can also easily output a video's first frame as
a poster image to be passed into the <video> tag.
If this image is kept at the exact resolution of the video, the browser
doesn't need to wait for an indeterminate amount of "video metadata" to be
loaded, and can reserve the necessary space in the page layout much faster
and without any of these dreaded loading spinners. For the big
/blog page, this cuts down the minimum amount of required
resources from 69.5 MB to 3.6 MB, finally making it usable again without
waiting an eternity for the page to fully load. It's become pretty bad, so I
really had to prioritize this task before adding any more blog posts on top.
That leaves the player itself, which is basically a sum of lots of little
implementation challenges. Single-frame stepping and seeking to discrete
frames is the biggest one of them, as it's technically
not possible within the <video> tag, which only
returns the current time as a continuous value in seconds. It only sort
of works for us because the backend can pass the necessary FPS and frame
count values to the frontend. These allow us to place a discrete grid of
frame "frets" at regular intervals, and thus establish a consistent mapping
from frames to seconds and back. The only drawback here is a noticeably
weird jump back by one frame when pausing a video within the second half of
a frame, caused by snapping the continuous time in seconds back onto the
frame grid in order to maintain a consistent frame counter. But the whole
feature of frame-based seeking more than makes up for that.
The new scrubbable timeline might be even nicer to use with a mouse or a
finger than just letting a video play regularly. With all the tuning work I
put into keyframes, seeking is buttery smooth, and much better than the
built-in <video> UI of either Chrome or Firefox.
Unfortunately, it still costs a whole lot of CPU, but I'd say it's worth it.
🥲
Finally, the new player also has a few features that might not be
immediately obvious:
Keybindings for almost everything you might want them for, indicated by
hovering on top of each button. The tab switchers additionally support the
↑ Up and ↓ Down keys to cycle through all tabs, or the number keys
to jump to a specific tab. Couldn't find a way to indicate these mappings in
the UI yet.
Per-video captions now reserve the maximum height of any caption in the
layout. This prevents layout reflows when switching through such videos,
which previously caused quite annoying lag on the big /blog
page.
Useful fullscreen modes on both desktop and mobile, including all
markers and the video caption. Firefox made this harder than it needed to
be, and if it weren't for display: contents, the implementation
would have been even worse. In the end though, we didn't even need any video
pixel sizes from the backend – just as it should be…
… and supporting Firefox was definitely worth it, as it's the only
browser to support nearest-neighbor interpolation on videos.
As some of the Unicode codepoints on the buttons aren't covered by the
default fonts of some operating systems, I've taken them from the Catrinity font, licensed under the SIL
Open Font License. With all
the edits I did on this font, that license definitely was necessary. I
hope I applied it correctly though; it's not straightforward at all how to
properly license a Modified Version of an original font with a
Reserved Font Name.
And with that, development hell is over, and I finally get to return to the
core business! Just more than one month late.
Next up: Shipping the oldest still pending order, covering the TH04/TH05
ending script format. Meanwhile, the Seihou community also wants to keep
investing in Shuusou Gyoku, so we're also going to see more of that on the
side.
The "bad" news first: Expanding to Stripe in order to support Google Pay
requires bureaucratic effort that is not quite justified yet, and would only
be worth it after the next price increase.
Visualizing technical debt has definitely been overdue for a while though.
With 1 of these 2 pushes being focused on this topic, it makes sense to
summarize once again what "technical debt"
means in the context of ReC98, as this info was previously kind of scattered
over multiple blog posts. Mainly, it encompasses
any ZUN-written code
that we did name and reverse-engineer,
but which we simply moved out into dedicated files that are then
#included back into the big .ASM translation units,
without worrying about decompilation or proving undecompilability for
now.
Technically (ha), it would also include all of master.lib, which has
always been compiled into the binaries in this way, and which will require
quite a bit of dedicated effort to be moved out into a properly linkable
library, once it's feasible. But this code has never been part of any
progress metric – in fact, 0% RE is
defined as the total number of x86 instructions in the binary minus
any library code. There is also no relation between instruction numbers and
the time it will take to finalize master.lib code, let alone a precedent of
how much it would cost.
If we now want to express technical debt as a percentage, it's clear where
the 100% point would be: when all RE'd code is also compiled in from a
translation unit outside the big .ASM one. But where would 0% be? Logically,
it would be the point where no reverse-engineered code has ever been moved
out of the big translation units yet, and nothing has ever been decompiled.
With these boundary points, this is what we get:
Not too bad! So it's 6.22% of total RE that we will have to revisit at some
point, concentrated mostly around TH04 and TH05 where it resulted from a
focus on position independence. The prices also give an accurate impression
of how much more work would be required there.
But is that really the best visualization? After all, it requires an
understanding of our definition of technical debt, so it's maybe not the
most useful measurement to have on a front page. But how about subtracting
those 6.22% from the number shown on the RE% bars? Then, we get this:
Which is where we get to the good news: Twitter surprisingly helped me out
in choosing one visualization over the other, voting
7:2 in favor of the Finalized version. While this one requires
you to manually calculate € finalized - € RE'd to
obtain the raw financial cost of technical debt, it clearly shows, for the
first time, how far away we are from the main goal of fully decompiling all
5 games… at least to the extent it's possible.
Now that the parser is looking at these recursively included .ASM files for
the first time, it needed a small number of improvements to correctly handle
the more advanced directives used there, which no automatic disassembler
would ever emit. Turns out I've been counting some directives as
instructions that never should have been, which is where the additional
0.02% total RE came from.
One more overcounting issue remains though. Some of the RE'd assembly slices
included by multiple games contain different if branches for
each game, like this:
; An example assembly file included by both TH04's and TH05's MAIN.EXE:
if (GAME eq 5)
; (Code for TH05)
else
; (Code for TH04)
endif
Currently, the parser simply ignores if, else, and
endif, leading to the combined code of all branches being
counted for every game that includes such a file. This also affects the
calculated speed, and is the reason why finalization seems to be slightly
faster than reverse-engineering, at currently 471 instructions per push
compared to 463. However, it's not that bad of a signal to send: Most of the
not yet finalized code is shared between TH04 and TH05, so finalizing it
will roughly be twice as fast as regular reverse-engineering to begin with.
(Unless the code then turns out to be twice as complex than average code…
).
For completeness, finalization is now also shown as part of the per-commit metrics. Now it's clearly visible what I was
doing in those very slow five months between P0131 and P0140, where
the progress bar didn't move at all: Repaying 3.49% of previously
accumulated technical debt across all games. 👌
As announced, I've also implemented a new caching system for this website,
as the second main feature of these two pushes. By appending a hash string
to the URLs of static resources, your browser should now both cache them
forever and re-download them once they did change on the server. This
avoids the unnecessary (and quite frankly, embarrassing) re-requests for all
static resources that typically just return a 304 Not Modified
response. As a result, the blog should now load a bit faster on repeated
visits, especially on slower connections. That should allow me to
deliberately not paginate it for another few years, without it getting all
too slow – and should prepare us for the day when our first game
reaches 100% and the server will get smashed.
However, I am open to changing the progress blog link in the
navigation bar at the top to the list of tags, once
people start complaining.
Apart frome some more invisible correctness and QoL improvements, I've also
prepared some new funding goals, but I'll cover those once the store
reopens, next year. Syntax highlighting for code snippets would have also
been cool, but unfortunately didn't make it into those two pushes. It's
still on the list though!
Next up: Back to RE with the TH03 score file format, and other code that
surrounds it.
Who said working on the website was "fun"? That code is a mess.
This right here is the first time I seriously
wrote a website from (almost) scratch. Its main job is to parse over a Git
repository and calculate numbers, so any additional bulky frameworks would
only be in the way, and probably need to be run on some sort of wobbly,
unmaintainable "stack" anyway, right? 😛
📝 As with the main project though, I'm only
beginning to figure out the best structure for this, and these new features
prompted quite a lot of upfront refactoring…
Before I start ranting though, let's quickly summarize the most visible
change, the new tag system for this blog!
Yes, I manually went through every one of the 82 posts I've written so
far, and assigned labels to them.
The per-project (rec98 and
website) and per-game (th01th02th03th04th05) tags are automatically generated from the
database and the Git commit history, respectively. That might have
ended us up with a fair bit of category clutter, as any single change
to a tiny aspect is enough for a blog post to be tagged with an
otherwise unrelated game. For now, it doesn't seem too much of
an issue though.
Filtering already works for an arbitrary number of tags. Right now,
these are always combined with AND – no arbitrary boolean expressions for tag filtering yet.
Adding filters simply works by adding components to the URL path:
https://rec98.nmlgc.net/blog/tag/tag1/tag2/tag3/… and so
on.
Hovering over any tag shows a brief description of what that tag is
about. Some of the terms really needed a definition, so I just added one for
all of them. Hope you all enjoy them!
These descriptions are also shown on the new
tag overview page, which now kind of doubles as a
glossary.
Finally, the order page now shows the exact number of pushes a contribution
will fund – no more manual divisions required.
Shoutout to the one email I received, which pointed out this potential
improvement!
As for the "invisible" changes: The one main feature of this website, the
aforementioned calculation of the progress metrics, also turned out as its
biggest annoyance over the years. It takes a little while to parse all the
big .ASM files in the source tree, once for every push that can affect the
average number of removed instructions and unlabeled addresses. And without
a cache, we've had to do that every time we re-launch the app server
process.
Fundamentally, this is – you might have guessed it – a dependency tracking
problem, with two inputs: the .ASM files from the ReC98 repo, and the
Golang code that calculates the instruction and PI numbers. Sure, the code
has been pretty stable, but what if we do end up extending it one day? I've
always disliked manually specified version numbers for use cases like this
one, where the problem at hand could be exactly solved with a hashing
function, without being prone to human error.
(Sidenote: That's why I never actively supported thcrap mods that affected
gameplay while I was still working on that project. We still want to be
able to save and share replays made on modded games, but I do not
want to subject users to the unacceptable burden of manually remembering
which version of which patch stack they've recorded a given replay with.
So, we'd somehow need to calculate a hash of everything that defines the
gameplay, exclude the things that don't, and only show
replays that were recorded on the hash that matches the currently running
patch stack. Well, turns out that True Touhou Fans™ quite enjoy watching
the games get broken in every possible way. That's the way ZUN intended the
games to be experienced, after all. Otherwise, he'd be constantly
maintaining the games and shipping bugfix patches… 🤷)
Now, why haven't I been caching the progress numbers all along? Well,
parallelizing that parsing process onto all available CPU cores seemed
enough in 2019 when this site launched. Back then, the estimates were
calculated from slightly over 10 million lines of ASM, which took about 7
seconds to be parsed on my mid-range dev system.
Fast forward to P0142 though, and we have to parse 34.3 million lines of
ASM, which takes about 26 seconds on my dev system. That would have only
got worse with every new delivery, especially since this production server
doesn't have as many cores.
I was thinking about a "doing less" approach for a while: Parsing only the
files that had changed between the start and end commit of a push, and
keeping those deltas across push boundaries. However, that turned out to be
slightly more complex than the few hours I wanted to spend on it.
And who knows how well that would have scaled. We've still got a few
hundred pushes left to go before we're done here, after all.
So with the tag system, as always, taking longer and consuming more pushes
than I had planned, the time had come to finally address the underlying
dependency tracking problem.
Initially, this sounded like a nail that was tailor-made for
📝 my favorite hammer, Tup: Move the parser
to a separate binary, gather the list of all commits via git
rev-list, and run that parser binary on every one of the commits
returned. That should end up correctly tracking the relevant parts of
.git/ and the new binary as inputs, and cause the commits to
be re-parsed if the parser binary changes, right? Too bad that Tup both
refuses to track
anything inside .git/, and can't track a Golang binary
either, due to all of the compiler's unpredictable outputs into its build
cache. But can't we at least turn off–
> The build cache is now required as a step toward eliminating $GOPATH/pkg.
— Go 1.12 release notes
Oh, wonderful. Hey, I always liked $GOPATH! 🙁
But sure, Golang is too smart anyway to require an external build system.
The compiler's
build
ID is exactly what we need to correctly invalidate the progress number
cache. Surely there is a way to retrieve the build ID for any package that
makes up a binary at runtime via some kind of reflection, right? Right? …Of
course not, in the great Unix tradition, this functionality is only
available as a CLI tool that prints its result to stdout.
🙄
But sure, no problem, let's just exec() a separate process on
the parser's library package file… oh wait, such a thing doesn't exist
anymore, unless you manually install the package. This would
have added another complication to the build process, and you'd
still have to manually locate the package file, with its version-specific
directory name. That might have worked out in the end, but figuring
all this out would have probably gone way beyond the budget.
OK, but who cares about packages? We just care about one single file here,
anyway. Didn't they put the official Golang source code parser into the
standard library? Maybe that can give us something close to the
build ID, by hashing the abstract syntax tree of that file. Well, for
starters, one does not simply serialize the returned AST. At least
into Golang's own, most "native" Gob
format, which requires all types from the go/ast package
to be manually registered first.
That leaves
ast.Fprint() as the
only thing close to a ready-made serialization function… and guess what,
that one suffers from Golang's typical non-deterministic order when
rendering any map to a string. 🤦
Guess there's no way around the simplest, most stupid way of simply
calculating any cryptographically secure hash over the ASM parser file. 😶
It's not like we frequently change comments in this file, but still, this
could have been so much nicer.
Oh well, at least I did get that issue resolved now, in an
acceptable way. If you ever happened to see this website rebuilding: That
should now be a matter of seconds, rather than minutes. Next up: Shinki's
background animations!
Calculating the average speed of the previous crowdfunded pushes, we arrive at estimated "goals" of…
So, time's up, and I didn't even get to the entire PayPal integration and FAQ parts… 😕 Still got to clarify a couple of legal questions before formally starting this, though. So for now, let's continue with zorg's next 5 TH05 reverse-engineering and decompilation pushes, and watch those prices go down a bit… hopefully quite significantly!
In order to be able to calculate how many instructions and absolute memory references are actually being removed with each push, we first need the database with the previous pushes from the Discord crowdfunding days. And while I was at it, I also imported the summary posts from back then.
Also, we now got something resembling a web design!
So yeah, "upper bound" and "probability". In reality it's certainly better than the numbers suggest, but as I keep saying, we can't say much about position independence without having reverse-engineered everything.
Now with the number of not yet RE'd x86 instructions the you might have seen in the thpatch Discord. They're a bit smaller now, didn't filter out a couple of directives back then.
Yes, requesting these currently is super slow. That's why I didn't want to have everyone here yet!
Next step: Figuring out the actual total number of game code instructions, for that nice "% done". Also, trying to do the same for position independence.




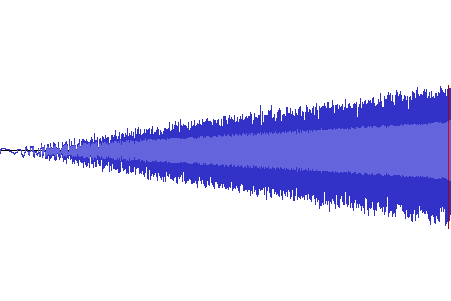
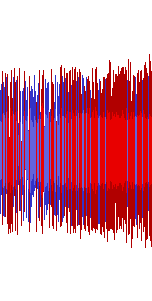

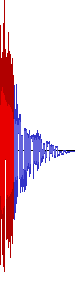

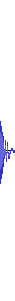

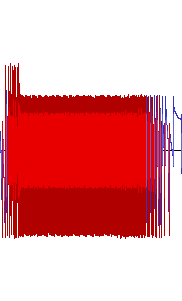


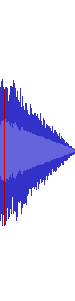

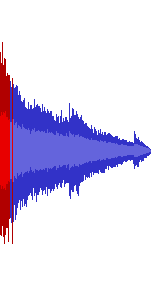
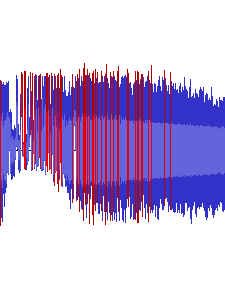
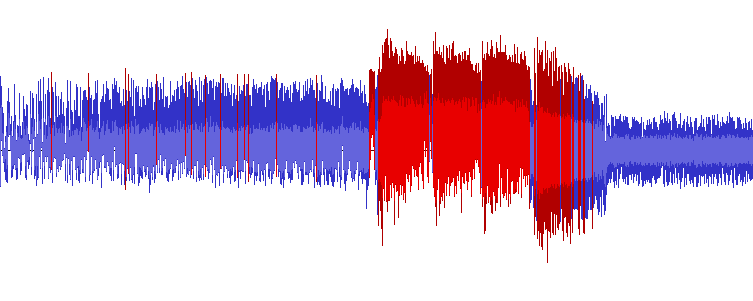

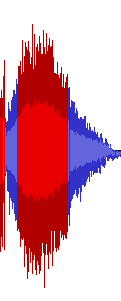
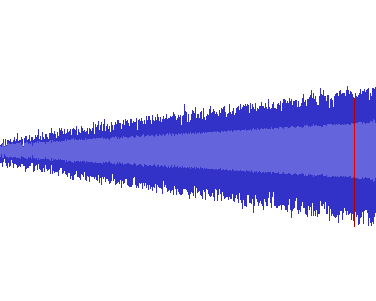

![Joypad button unbinding in the original version of Shuusou Gyoku, indicated by a rather confusing [Button 0] label](/blog/static/2023-09-30-SH01-Joypad-unmapping-original.png?9fe43b80)
![Joypad button unbinding in the P0256 build of Shuusou Gyoku, using a much clearer [--------] label](/blog/static/2023-09-30-SH01-Joypad-unmapping-P0256.png?f7adebb7)






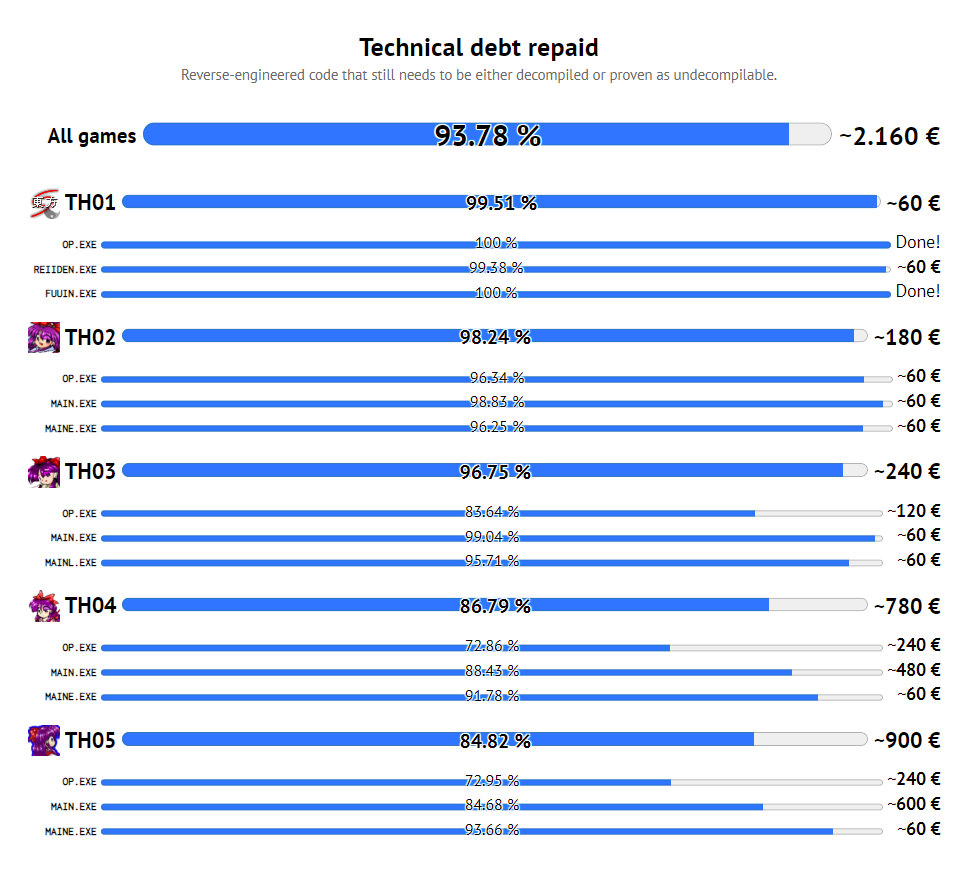
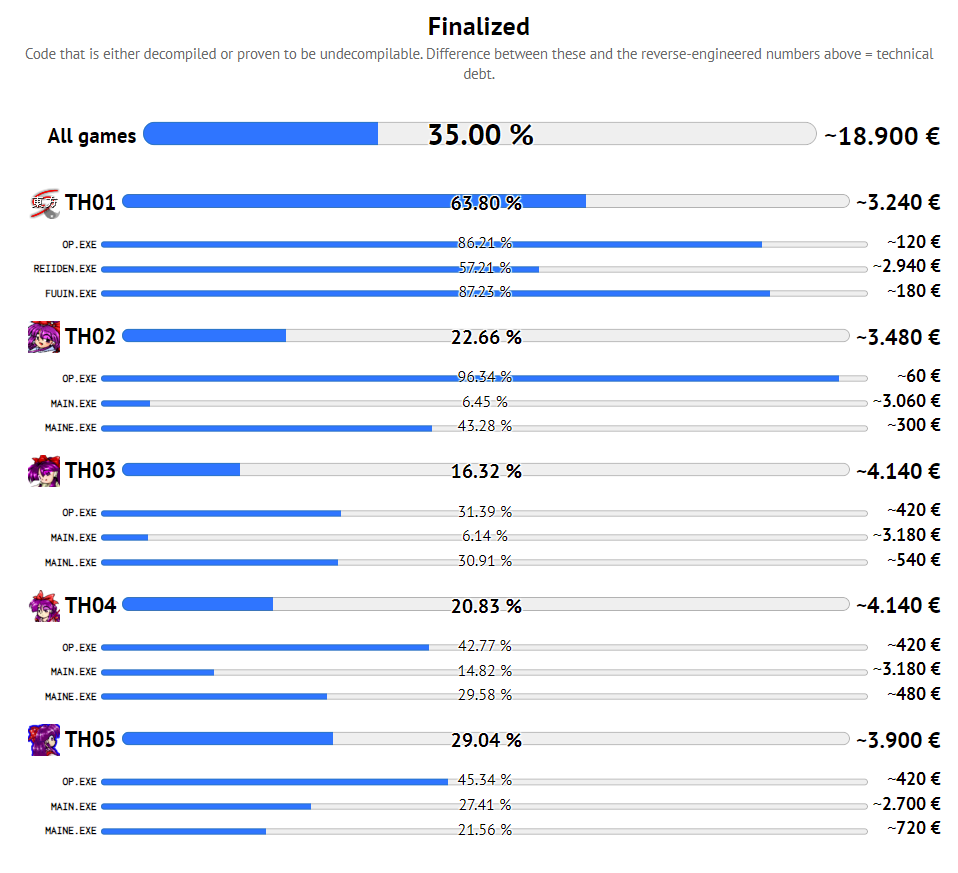
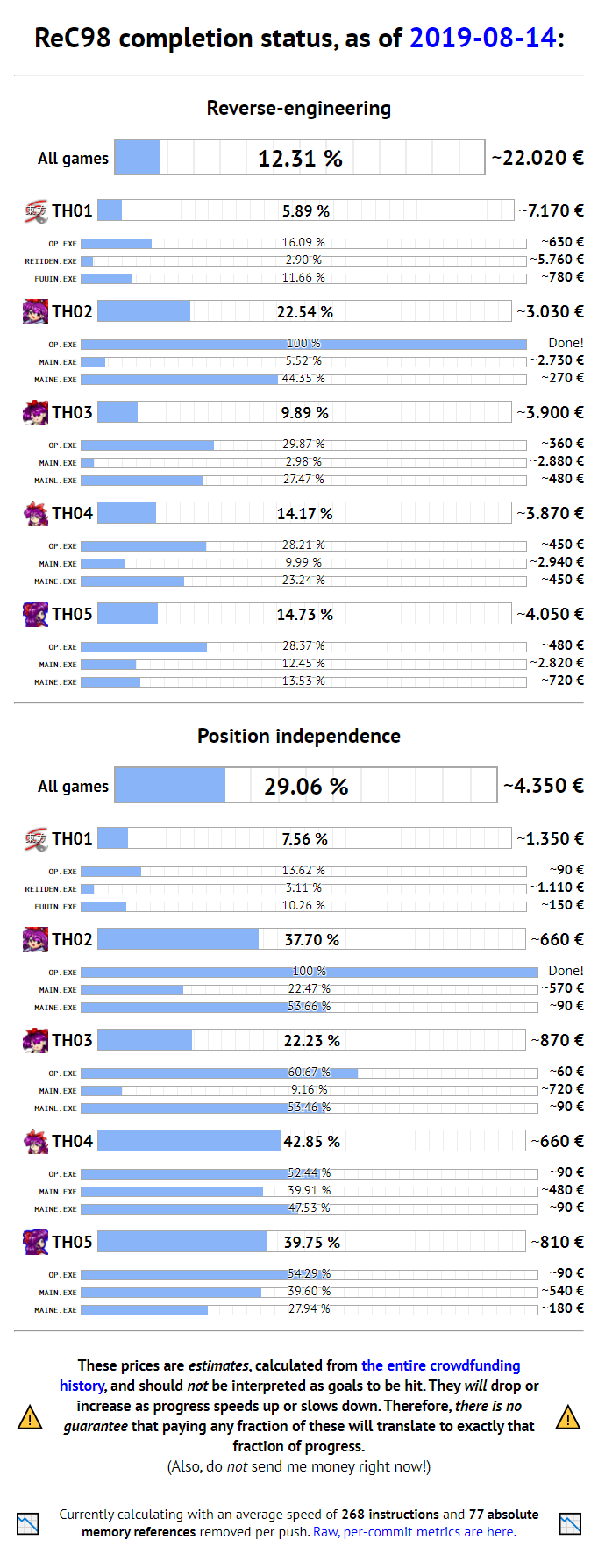
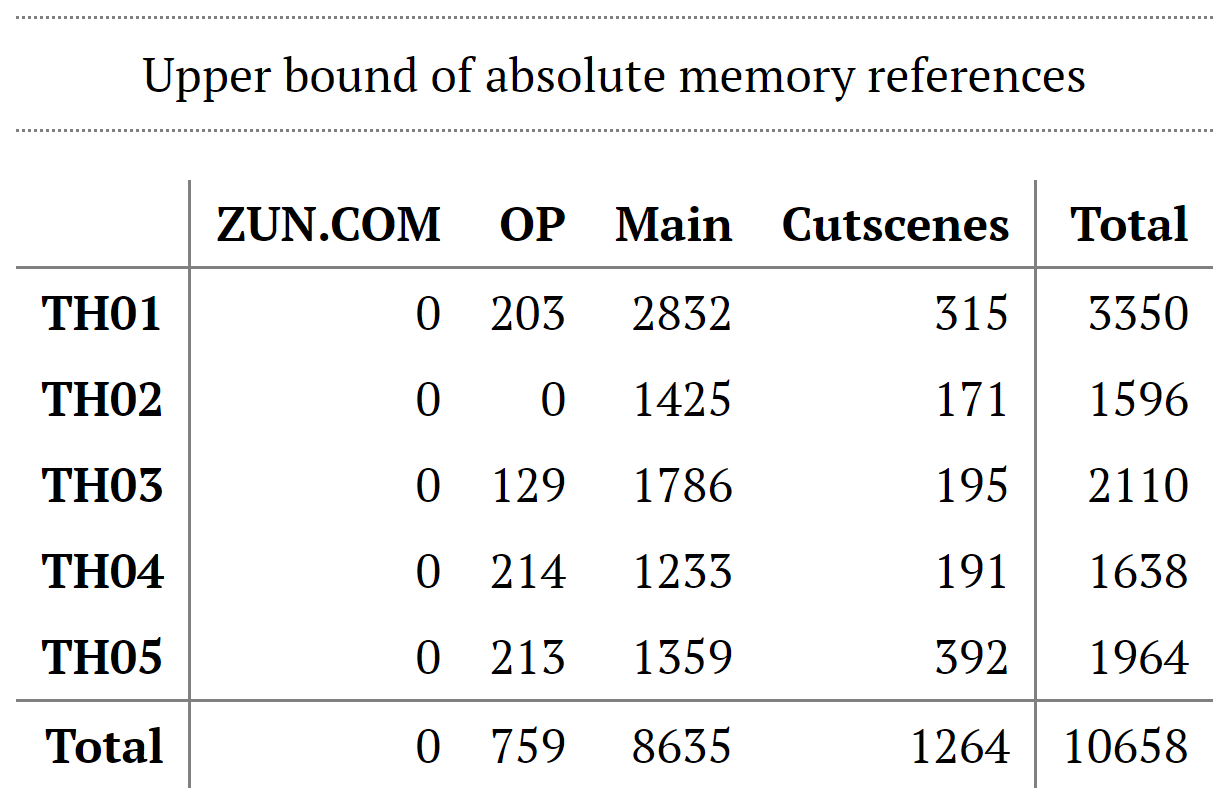
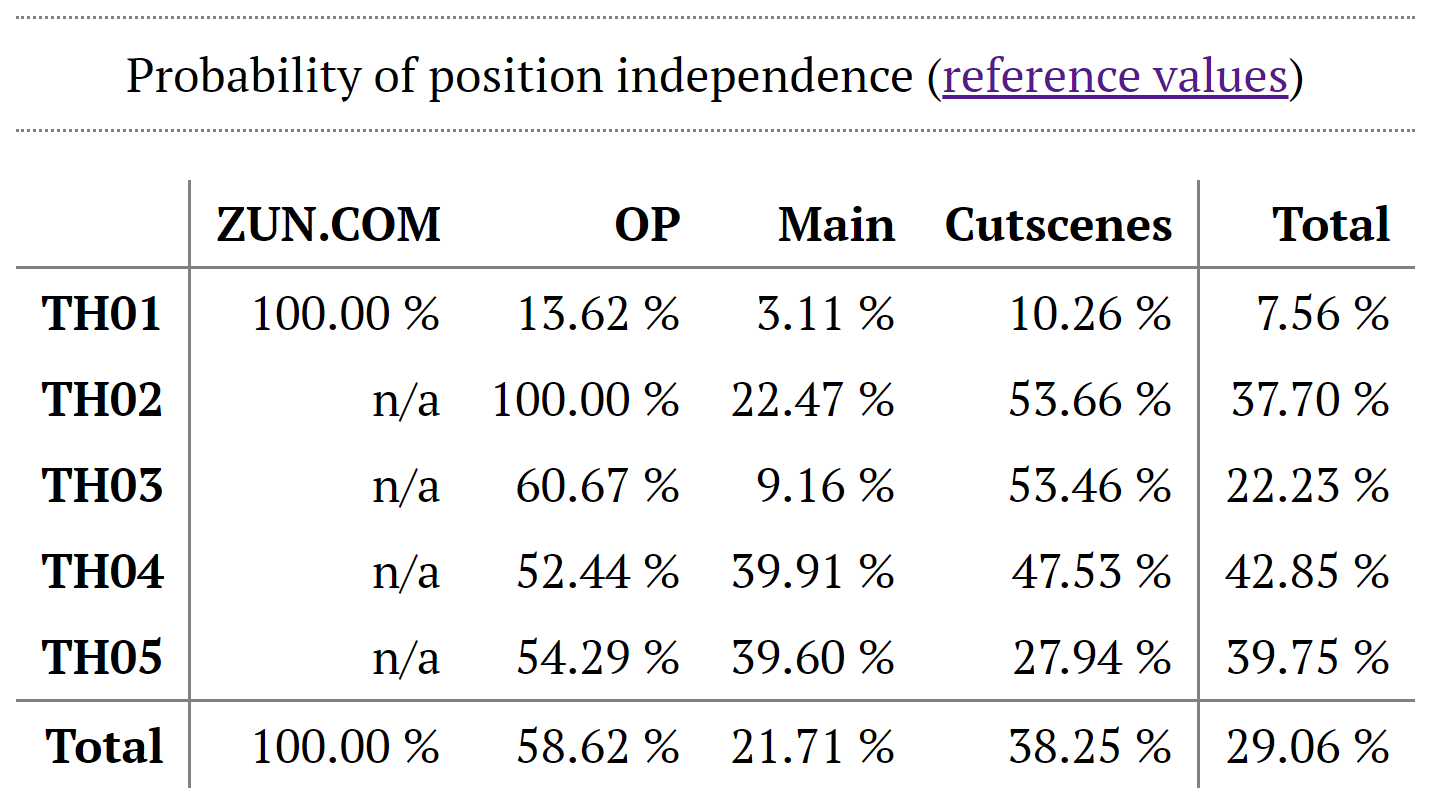
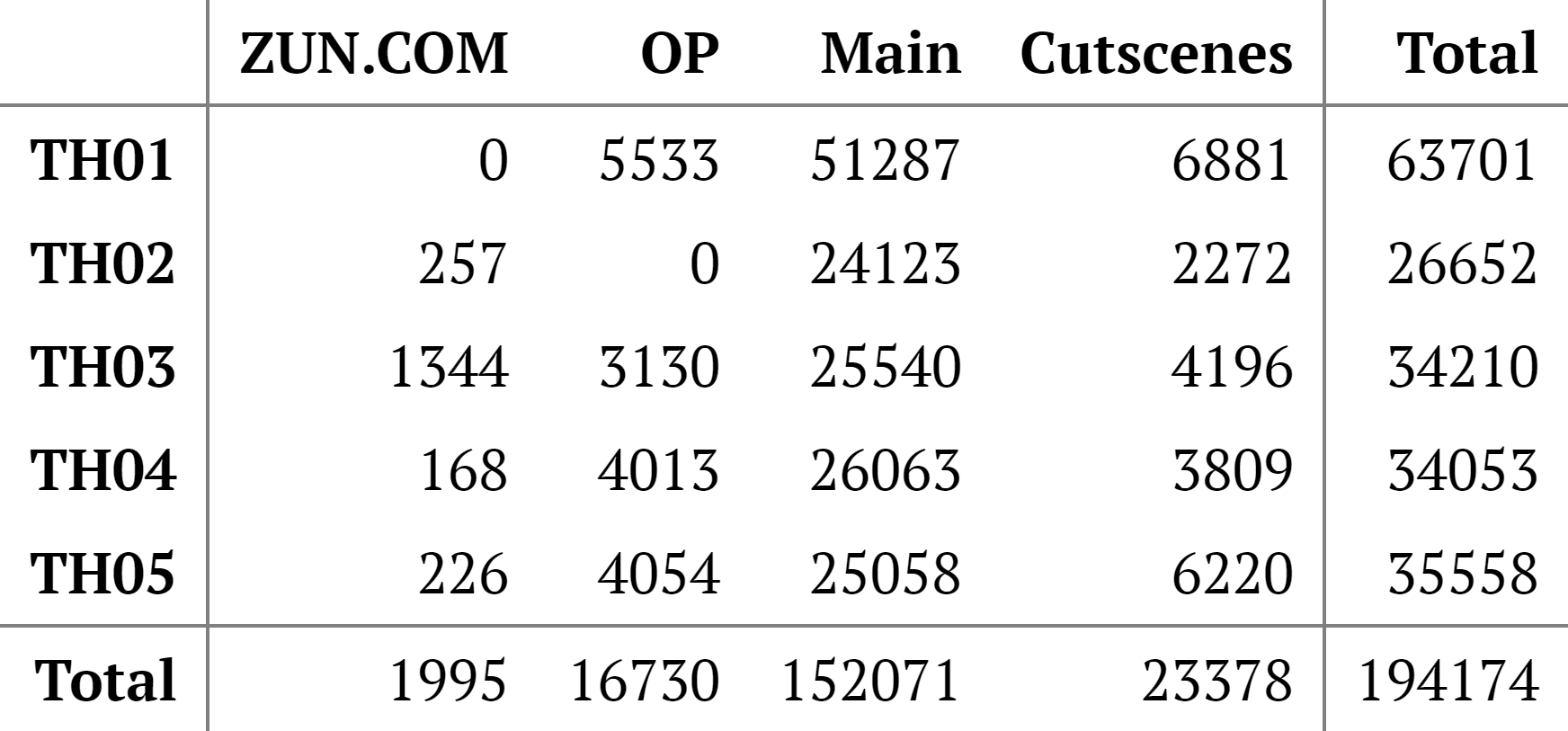
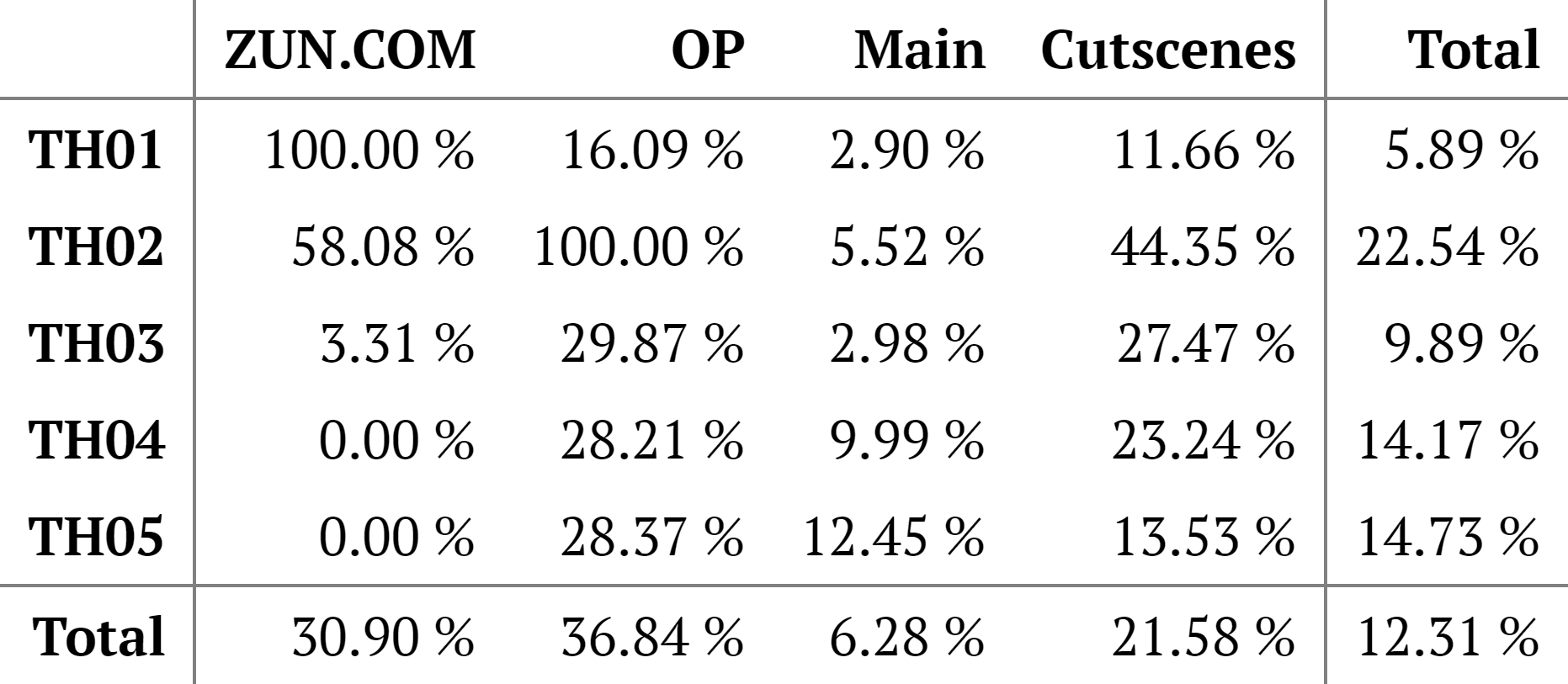
{kind=link}