Well, well. My original plan was to ship the first step of Shuusou Gyoku
OpenGL support on the next day after this delivery. But unfortunately, the
complications just kept piling up, to a point where the required solutions
definitely blow the current budget for that goal. I'm currently sitting on
over 70 commits that would take at least 5 pushes to deliver as a meaningful
release, and all of that is just rearchitecting work, preparing the
game for a not too Windows-specific OpenGL backend in the first place. I
haven't even written a single line of OpenGL yet… 🥲
This shifts the intended Big Release Month™ to June after all. Now I know
that the next round of Shuusou Gyoku features should better start with the
SC-88Pro recordings, which are much more likely to get done within their
current budget. At least I've already completed the configuration versioning
system required for that goal, which leaves only the actual audio part.
So, TH04 position independence. Thanks to a bit of funding for stage
dialogue RE, non-ASCII translations will soon become viable, which finally
presents a reason to push TH04 to 100% position independence after
📝 TH05 had been there for almost 3 years. I
haven't heard back from Touhou Patch Center about how much they want to be
involved in funding this goal, if at all, but maybe other backers are
interested as well.
And sure, it would be entirely possible to implement non-ASCII translations
in a way that retains the layout of the original binaries and can be easily
compared at a binary level, in case we consider translations to be a
critical piece of infrastructure. This wouldn't even just be an exercise in
needless perfectionism, and we only have to look to Shuusou Gyoku to realize
why: Players expected
that my builds were compatible with existing SpoilerAL SSG files, which
was something I hadn't even considered the need for. I mean, the game is
open-source 📝 and I made it easy to build.
You can just fork the code, implement all the practice features you want in
a much more efficient way, and I'd probably even merge your code into my
builds then?
But I get it – recompiling the game yields just yet another build that can't
be easily compared to the original release. A cheat table is much more
trustworthy in giving players the confidence that they're still practicing
the same original game. And given the current priorities of my backers,
it'll still take a while for me to implement proof by replay validation,
which will ultimately free every part of the community from depending on the
original builds of both Seihou and PC-98 Touhou.
However, such an implementation within the original binary layout would
significantly drive up the budget of non-ASCII translations, and I sure
don't want to constantly maintain this layout during development. So, let's
chase TH04 position independence like it's 2020, and quickly cover a larger
amount of PI-relevant structures and functions at a shallow level. The only
parts I decompiled for now contain calculations whose intent can't be
clearly communicated in ASM. Hitbox visualizations or other more in-depth
research would have to wait until I get to the proper decompilation of these
features.
But even this shallow work left us with a large amount of TH04-exclusive
code that had its worst parts RE'd and could be decompiled fairly quickly.
If you want to see big TH04 finalization% gains, general TH04 progress would
be a very good investment.
The first push went to the often-mentioned stage-specific custom entities
that share a single statically allocated buffer. Back in 2020, I
📝 wrongly claimed that these were a TH05 innovation,
but the system actually originated in TH04. Both games use a 26-byte
structure, but TH04 only allocates a 32-element array rather than TH05's
64-element one. The conclusions from back then still apply, but I also kept
wondering why these games used a static array for these entities to begin
with. You know what they call an area of memory that you can cleanly
repurpose for things? That's right, a heap!
And absolutely no one would mind one additional heap allocation at the start
of a stage, next to the ones for all the sprites and portraits.
However, we are still running in Real Mode with segmented memory. Accessing
anything outside a common data segment involves modifying segment registers,
which has a nonzero CPU cycle cost, and Turbo C++ 4.0J is terrible at
optimizing away the respective instructions. Does this matter? Probably not,
but you don't take "risks" like these if you're in a permanent
micro-optimization mindset…
In TH04, this system is used for:
Kurumi's symmetric bullet spawn rays, fired from her hands towards the left
and right edges of the playfield. These are rather infamous for being the
last thing you see before
📝 the Divide Error crash that can happen in ZUN's original build.
Capped to 6 entities.
The 4 📝 bits used in Marisa's Stage 4 boss
fight. Coincidentally also related to the rare Divide Error
crash in that fight.
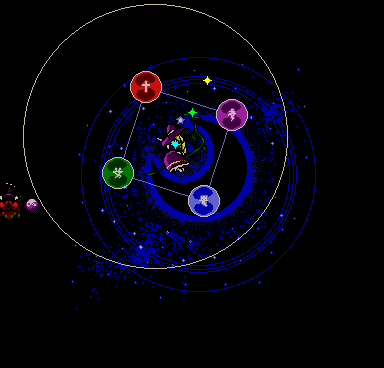
Stage 4 Reimu's spinning orbs. Note how the game uses two different sets
of sprites just to have two different outline colors. This was probably
better than messing with the palette, which can easily cause unintended
effects if you only have 16 colors to work with. Heck, I have an entire blog post tag just to highlight
these cases. Capped to the full 32 entities.
The chasing cross bullets, seen in Phase 14 of the same Stage 6 Yuuka
fight. Featuring some smart sprite work, making use of point symmetry to
achieve a fluid animation in just 4 frames. This is
good-code in sprite form. Capped to 31 entities, because the 32nd custom entity during this fight is defined to be…
The single purple pulsating and shrinking safety circle, seen in Phase 4 of
the same fight. The most interesting aspect here is actually still related
to the cross bullets, whose spawn function is wrongly limited to 32 entities
and could theoretically overwrite this circle. This
is strictly landmine territory though:
Yuuka never uses these bullets and the safety circle
simultaneously
She never spawns more than 24 cross bullets
All cross bullets are fast enough to have left the screen by the
time Yuuka restarts the corresponding subpattern
The cross bullets spawn at Yuuka's center position, and assign its
Q12.4 coordinates to structure fields that the safety circle interprets
as raw pixels. The game does try to render the circle afterward, but
since Yuuka's static position during this phase is nowhere near a valid
pixel coordinate, it is immediately clipped.
The flashing lines seen in Phase 5 of the Gengetsu fight,
telegraphing the slightly random bullet columns.
These structures only took 1 push to reverse-engineer rather than the 2 I
needed for their TH05 counterparts because they are much simpler in this
game. The "structure" for Gengetsu's lines literally uses just a single X
position, with the remaining 24 bytes being basically padding. The only
minor bug I found on this shallow level concerns Marisa's bits, which are
clipped at the right and bottom edges of the playfield 16 pixels earlier
than you would expect:
The remaining push went to a bunch of smaller structures and functions:
The structure for the up to 2 "thick" (a.k.a. "Master Spark") lasers. Much
saner than the
📝 madness of TH05's laser system while being
equally customizable in width and duration.
The structure for the various monochrome 16×16 shapes in the background of
the Stage 6 Yuuka fight, drawn on top of the checkerboard.
The rendering code for the three falling stars in the background of Stage 5.
The effect here is entirely palette-related: After blitting the stage tiles,
the 📝 1bpp star image is ORed
into only the 4th VRAM plane, which is equivalent to setting the
highest bit in the palette color index of every pixel within the star-shaped
region. This of course raises the question of how the stage would look like
if it was fully illuminated:
The full tile map of TH04's Stage 5, in both dark and fully
illuminated views. Since the illumination effect depends on two
matching sets of palette colors that are distinguished by a single
bit, the illuminated view is limited to only 8 of the 16 colors. The
dark view, on the other hand, can freely use colors from the
illuminated set, since those are unaffected by the OR
operation.
Most code that modifies a stage's tile map, and directly specifies tiles via
their top-left offset in VRAM.
Thanks to code alignment reasons, this forced a much longer detour into the
.STD format loader. Nothing all too noteworthy there since we're still
missing the enemy script and spawn structures before we can call .STD
"reverse-engineered", but maybe still helpful if you're looking for an
overview of the format. Also features a buffer overflow landmine if a .STD
file happens to contain more than 32 enemy scripts… you know, the usual
stuff.
To top off the second push, we've got the vertically scrolling checkerboard
background during the Stage 6 Yuuka fight, made up of 32×32 squares. This
one deserves a special highlight just because of its needless complexity.
You'd think that even a performant implementation would be pretty simple:
Set the GRCG to TDW mode
Set the GRCG tile to one of the two square colors
Start with Y as the current scroll offset, and X
as some indicator of which color is currently shown at the start of each row
of squares
Iterate over all lines of the playfield, filling in all pixels that
should be displayed in the current color, skipping over the other ones
Count down Y for each line drawn
If Y reaches 0, reset it to 32 and flip X
At the bottom of the playfield, change the GRCG tile to the other color,
and repeat with the initial value of X flipped
The most important aspect of this algorithm is how it reduces GRCG state
changes to a minimum, avoiding the costly port I/O that we've identified
time and time again as one of the main bottlenecks in TH01. With just 2
state variables and 3 loops, the resulting code isn't that complex either. A
naive implementation that just drew the squares from top to bottom in a
single pass would barely be simpler, but much slower: By changing the GRCG
tile on every color, such an implementation would burn a low 5-digit number
of CPU cycles per frame for the 12×11.5-square checkerboard used in the
game.
And indeed, ZUN retained all important aspects of this algorithm… but still
implemented it all in ASM, with a ridiculous layer of x86 segment arithmetic
on top? Which blows up the complexity to 4 state
variables, 5 nested loops, and a bunch of constants in unusual units. I'm
not sure what this code is supposed to optimize for, especially with that
rather questionable register allocation that nevertheless leaves one of the
general-purpose registers unused. Fortunately,
the function was still decompilable without too many code generation hacks,
and retains the 5 nested loops in all their goto-connected
glory. If you want to add a checkerboard to your next PC-98
demo, just stick to the algorithm I gave above.
(Using a single XOR for flipping the starting X offset between 32 and 64
pixels is pretty nice though, I have to give him that.)
This makes for a good occasion to talk about the third and final GRCG mode,
completing the series I started with my previous coverage of the
📝 RMW and
📝 TCR modes. The TDW (Tile Data Write) mode
is the simplest of the three and just writes the 8×1 GRCG tile into VRAM
as-is, without applying any alpha bitmask. This makes it perfect for
clearing rectangular areas of pixels – or even all of VRAM by doing a single
memset():
// Set up the GRCG in TDW mode.
outportb(0x7C, 0x80);
// Fill the tile register with color #7 (0111 in binary).
outportb(0x7E, 0xFF); // Plane 0: (B): (********)
outportb(0x7E, 0xFF); // Plane 1: (R): (********)
outportb(0x7E, 0xFF); // Plane 2: (G): (********)
outportb(0x7E, 0x00); // Plane 3: (E): ( )
// Set the 32 pixels at the top-left corner of VRAM to the exact contents of
// the tile register, effectively repeating the tile 4 times. In TDW mode, the
// GRCG ignores the CPU-supplied operand, so we might as well just pass the
// contents of a register with the intended width. This eliminates useless load
// instructions in the compiled assembly, and even sort of signals to readers
// of this code that we do not care about the source value.
*reinterpret_cast<uint32_t far *>(MK_FP(0xA800, 0)) = _EAX;
// Fill the entirety of VRAM with the GRCG tile. A simple C one-liner that will
// probably compile into a single `REP STOS` instruction. Unfortunately, Turbo
// C++ 4.0J only ever generates the 16-bit `REP STOSW` here, even when using
// the `__memset__` intrinsic and when compiling in 386 mode. When targeting
// that CPU and above, you'd ideally want `REP STOSD` for twice the speed.
memset(MK_FP(0xA800, 0), _AL, ((640 / 8) * 400));
However, this might make you wonder why TDW mode is even necessary. If it's
functionally equivalent to RMW mode with a CPU-supplied bitmask made up
entirely of 1 bits (i.e., 0xFF, 0xFFFF, or
0xFFFFFFFF), what's the point? The difference lies in the
hardware implementation: If all you need to do is write tile data to
VRAM, you don't need the read and modify parts of RMW mode
which require additional processing time. The PC-9801 Programmers'
Bible claims a speedup of almost 2× when using TDW mode over equivalent
operations in RMW mode.
And that's the only performance claim I found, because none of these old
PC-98 hardware and programming books did any benchmarks. Then again, it's
not too interesting of a question to benchmark either, as the byte-aligned
nature of TDW blitting severely limits its use in a game engine anyway.
Sure, maybe it makes sense to temporarily switch from RMW to TDW mode
if you've identified a large rectangular and byte-aligned section within a
sprite that could be blitted without a bitmask? But the necessary
identification work likely nullifies the performance gained from TDW mode,
I'd say. In any case, that's pretty deep
micro-optimization territory. Just use TDW mode for the
few cases it's good at, and stick to RMW mode for the rest.
So is this all that can be said about the GRCG? Not quite, because there are
4 bits I haven't talked about yet…
And now we're just 5.37% away from 100% position independence for TH04! From
this point, another 2 pushes should be enough to reach this goal. It might
not look like we're that close based on the current estimate, but a
big chunk of the remaining numbers are false positives from the player shot
control functions. Since we've got a very special deadline to hit, I'm going
to cobble these two pushes together from the two current general
subscriptions and the rest of the backlog. But you can, of course, still
invest in this goal to allow the existing contributions to go to something
else.
… Well, if the store was actually open. So I'd better
continue with a quick task to free up some capacity sooner rather than
later. Next up, therefore: Back to TH02, and its item and player systems.
Shouldn't take that long, I'm not expecting any surprises there. (Yeah, I
know, famous last words…)
Slight change of plans, because we got instructions for
reliably reproducing the TH04 Kurumi Divide Error crash! Major thanks to
Colin Douglas Howell. With those, it also made sense to immediately look at
the crash in the Stage 4 Marisa fight as well. This way, I could release
both of the obligatory bugfix mods at the same time.
Especially since it turned out that I was wrong: Both crashes are entirely
unrelated to the custom entity structure that would have required PI-centric
progress. They are completely specific to Kurumi's and Marisa's
danmaku-pattern code, and really are two separate bugs
with no connection to each other. All of the necessary research nicely fit
into Arandui's 0.5 pushes, with no further deep understanding
required here.
But why were there still three weeks between Colin's message and this blog
post? DMCA distractions aside: There are no easy fixes this time, unlike
📝 back when I looked at the Stage 5 Yuuka crash.
Just like how division by zero is undefined in mathematics, it's also,
literally, undefined what should happen instead of these two
Divide error crashes. This means that any possible "fix" can
only ever be a fanfiction interpretation of the intentions behind ZUN's
code. The gameplay community should be aware of this, and
might decide to handle these cases differently. And if we
have to go into fanfiction territory to work around crashes in the
canon games, we'd better document what exactly we're fixing here and how, as
comprehensible as possible.
With that out of the way, let's look at Kurumi's crash first, since it's way
easier to grasp. This one is known to primarily happen to new players, and
it's easy to see why:
In one of the patterns in her third phase, Kurumi fires a series of 3
aimed rings from both edges of the playfield. By default (that is, on Normal
and with regular rank), these are 6-way rings.
6 happens to be quite a peculiar number here, due to how rings are
(manually) tuned based on the current "rank" value (playperf)
before being fired. The code, abbreviated for clarity:
Let's look at the range of possible playperf values per
difficulty level:
Easy
Normal
Hard
Lunatic
Extra
playperf_min
4
11
20
22
16
playperf_max
16
24
32
34
20
Edit (2022-05-24): This blog post initially had
26 instead of 16 for playperf_min for the Extra Stage. Thanks
to Popfan for pointing out that typo!
Reducing rank to its minimum on Easy mode will therefore result in a
0-ring after tuning.
To calculate the individual angles of each bullet in a ring, ZUN divides
360° (or, more correctly,
📝 0x100) by the total number of
bullets…
Boom, division by zero.
The pattern that causes the crash in Kurumi's fight. Also
demonstrates how the number of bullets in a ring is always halved on
Easy Mode after the rank-based tuning, leading to just a 3-ring on
playperf = 16.
So, what should the workaround look like? Obviously, we want to modify
neither the default number of ring bullets nor the tuning algorithm – that
would change all other non-crashing variations of this pattern on other
difficulties and ranks, creating a fork of the original gameplay. Instead, I
came up with four possible workarounds that all seemed somewhat logical to
me:
Firing no bullet, i.e., interpreting 0-ring literally. This would
create the only constellation in which a call to the bullet group spawn
functions would not spawn at least one new bullet.
Firing a "1-ring", i.e., a single bullet. This would be consistent with
how the bullet spawn functions behave for "0-way" stack and spread
groups.
Firing a "∞-ring", i.e., 200 bullets, which is as much as the game's cap
on 16×16 bullets would allow. This would poke fun at the whole "division by
zero" idea… but given that we're still talking about Easy Mode (and
especially new players) here, it might be a tad too cruel. Certainly the
most trollish interpretation.
Triggering an immediate Game Over, exchanging the hard crash for a
softer and more controlled shutdown. Certainly the option that would be
closest to the behavior of the original games, and perhaps the only one to
be accepted in Serious, High-Level Play™.
As I was writing this post, it felt increasingly wrong for me to make this
decision. So I once again went to Twitter, where 56.3%
voted in favor of the 1-bullet option. Good that I asked! I myself was
more leaning towards the 0-bullet interpretation, which only got 28.7% of
the vote. Also interesting are the 2.3% in favor of the Game Over option but
I get it, low-rank Easy Mode isn't exactly the most competitive mode of
playing TH04.
There are reports of Kurumi crashing on higher difficulties as well, but I
could verify none of them. If they aren't fixed by this workaround, they're
caused by an entirely different bug that we have yet to discover.
Onto the Stage 4 Marisa crash then, which does in fact apply to all
difficulty levels. I was also wrong on this one – it's a hell of a lot more
intricate than being just a division by the number of on-screen bits.
Without having decompiled the entire fight, I can't give a completely
accurate picture of what happens there yet, but here's the rough idea:
Marisa uses different patterns, depending on whether at least one of her
bits is still alive, or all of them have been destroyed.
Destroying the last bit will immediately switch to the bit-less
counterpart of the current pattern.
The bits won't respawn before the pattern ended, which ensures that the
bit-less version is always shown in its entirety after being started or
switched into.
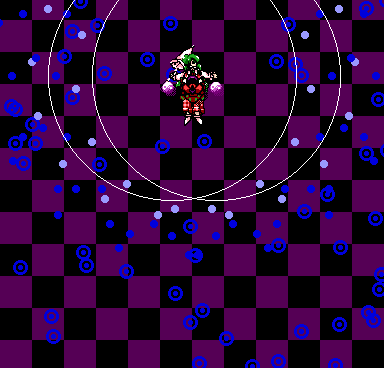
In two of the bit-less patterns, Marisa gradually moves to the point
reflection of her position at the start of the pattern across the playfield
coordinate of (192, 112), or (224, 128) on screen.
Reference points for Marisa's point-reflected movement. Cyan:
Marisa's position, green: (192, 112), yellow: the intended end
point.
The velocity of this movement is determined by both her distance to that
point and the total amount of frames that this instance of the bit-less
pattern will last.
Since this frame amount is directly tied to the frame the player
destroyed the last bit on, it becomes a user-controlled variable. I think
you can see where this is going…
The last 12 frames of this duration, however, are always reserved for a
"braking phase", where Marisa's velocity is halved on each frame.
This part of the code only runs every 4 frames though. This expands the
time window for this crash to 4 frames, rather than just the two frames you
would expect from looking at the division itself.
Both of the broken patterns run for a maximum of 160 frames. Therefore,
the crash will occur when Marisa's last bit is destroyed between frame 152
and 155 inclusive. On these frames, the
last_frame_with_bits_alive variable is set to 148, which is the
crucial 12 duration frames away from the maximum of 160.
Interestingly enough, the calculated velocity is also only
applied every 4 frames, with Marisa actually staying still for the 3 frames
inbetween. As a result, she either moves
too slowly to ever actually reach the yellow point if the last bit
was destroyed early in the pattern (see destruction frames 68 or
112),
or way too quickly, and almost in a jerky, teleporting way (see
destruction frames 144 or 148).
Finally, as you may have already gathered from the formula: Destroying
the last bit between frame 156 and 160 inclusive results in
duration values of 8 or 4. These actually push Marisa
away from the intended point, as the divisor becomes negative.
One of the two patterns in TH04's Stage 4 Marisa boss fight that feature
frame number-dependent point-reflected movement. The bits were hacked to
self-destruct on the respective frame.
tl;dr: "Game crashes if last bit destroyed within 4-frame window near end of
two patterns". For an informed decision on a new movement behavior for these
last 8 frames, we definitely need to know all the details behind the crash
though. Here's what I would interpret into the code:
Not moving at all, i.e., interpreting 0 as the middle ground between
positive and negative movement. This would also make sense because a
12-frame duration implies 100% of the movement to consist of
the braking phase – and Marisa wasn't moving before, after all.
Move at maximum speed, i.e., dividing by 1 rather than 0. Since the
movement duration is still 12 in this case, Marisa will immediately start
braking. In total, she will move exactly ¾ of the way from her initial
position to (192, 112) within the 8 frames before the pattern
ends.
Directly warping to (192, 112) on frame 0, and to the
point-reflected target on 4, respectively. This "emulates" the division by
zero by moving Marisa at infinite speed to the exact two points indicated by
the velocity formula. It also fits nicely into the 8 frames we have to fill
here. Sure, Marisa can't reach these points at any other duration, but why
shouldn't she be able to, with infinite speed? Then again, if Marisa
is far away enough from (192, 112), this workaround would warp her
across the entire playfield. Can Marisa teleport according to lore? I
have no idea…
Triggering an immediate Game O– hell no, this is the Stage 4 boss,
people already hate losing runs to this bug!
Asking Twitter worked great for the Kurumi workaround, so let's do it again!
Gotta attach a screenshot of an earlier draft of this blog post though,
since this stuff is impossible to explain in tweets…
…and it went
through the roof, becoming the most successful ReC98 tweet so far?!
Apparently, y'all really like to just look at descriptions of overly complex
bugs that I'd consider way beyond the typical attention span that can be
expected from Twitter. Unfortunately, all those tweet impressions didn't
quite translate into poll turnout. The results
were pretty evenly split between 1) and 2), with option 1) just coming out
slightly ahead at 49.1%, compared to 41.5% of option 2).
(And yes, I only noticed after creating the poll that warping to both the
green and yellow points made more sense than warping to just one of the two.
Let's hope that this additional variant wouldn't have shifted the results
too much. Both warp options only got 9.4% of the vote after all, and no one
else came up with the idea either. In the end,
you can always merge together your preferred combination of workarounds from
the Git branches linked below.)
So here you go: The new definitive version of TH04, containing not only the
community-chosen Kurumi and Stage 4 Marisa workaround variant, but also the
📝 No-EMS bugfix from last year.
Edit (2022-05-31): This package is outdated, 📝 the current version is here!2022-04-18-community-choice-fixes.zip
Oh, and let's also add spaztron64's TH03 GDC clock fix
from 2019 because why not. This binary was built from the community_choice_fixes
branch, and you can find the code for all the individual workarounds on
these branches:
Again, because it can't be stated often enough: These fixes are
fanfiction. The gameplay community should be aware of
this, and might decide to handle these cases differently.
With all of that taking way more time to evaluate and document, this
research really had to become part of a proper push, instead of just being
covered in the quick non-push blog post I initially intended. With ½ of a
push left at the end, TH05's Stage 1-5 boss background rendering functions
fit in perfectly there. If you wonder how these static backdrop images even
need any boss-specific code to begin with, you're right – it's basically the
same function copy-pasted 4 times, differing only in the backdrop image
coordinates and some other inconsequential details.
Only Sara receives a nice variation of the typical
📝 blocky entrance animation: The usually
opaque bitmap data from ST00.BB is instead used as a transition
mask from stage tiles to the backdrop image, by making clever use of the
tile invalidation system:
TH04 uses the same effect a bit more frequently, for its first three bosses.
Next up: Shinki, for real this time! I've already managed to decompile 10 of
her 11 danmaku patterns within a little more than one push – and yes,
that one is included in there. Looks like I've slightly
overestimated the amount of work required for TH04's and TH05's bosses…
Did you know that moving on top of a boss sprite doesn't kill the player in
TH04, only in TH05?
Yup, Reimu is not getting hit… yet.
That's the first of only three interesting discoveries in these 3 pushes,
all of which concern TH04. But yeah, 3 for something as seemingly simple as
these shared boss functions… that's still not quite the speed-up I had hoped
for. While most of this can be blamed, again, on TH04 and all of its
hardcoded complexities, there still was a lot of work to be done on the
maintenance front as well. These functions reference a bunch of code I RE'd
years ago and that still had to be brought up to current standards, with the
dependencies reaching from 📝 boss explosions
over 📝 text RAM overlay functionality up to
in-game dialog loading.
The latter provides a good opportunity to talk a bit about x86 memory
segmentation. Many aspiring PC-98 developers these days are very scared
of it, with some even going as far as to rather mess with Protected Mode and
DOS extenders just so that they don't have to deal with it. I wonder where
that fear comes from… Could it be because every modern programming language
I know of assumes memory to be flat, and lacks any standard language-level
features to even express something like segments and offsets? That's why
compilers have a hard time targeting 16-bit x86 these days: Doing anything
interesting on the architecture requires giving the programmer full
control over segmentation, which always comes down to adding the
typical non-standard language extensions of compilers from back in the day.
And as soon as DOS stopped being used, these extensions no longer made sense
and were subsequently removed from newer tools. A good example for this can
be found in an old version of the
NASM manual: The project started as an attempt to make x86 assemblers
simple again by throwing out most of the segmentation features from
MASM-style assemblers, which made complete sense in 1996 when 16-bit DOS and
Windows were already on their way out. But there was a point to all
those features, and that's why ReC98 still has to use the supposedly
inferior TASM.
Not that this fear of segmentation is completely unfounded: All the
segmentation-related keywords, directives, and #pragmas
provided by Borland C++ and TASM absolutely can be the cause of many
weird runtime bugs. Even if the compiler or linker catches them, you are
often left with confusing error messages that aged just as poorly as memory
segmentation itself.
However, embracing the concept does provide quite the opportunity for
optimizations. While it definitely was a very crazy idea, there is a small
bit of brilliance to be gained from making proper use of all these
segmentation features. Case in point: The buffer for the in-game dialog
scripts in TH04 and TH05.
// Thanks to the semantics of `far` pointers, we only need a single 32-bit
// pointer variable for the following code.
extern unsigned char far *dialog_p;
// This master.lib function returns a `void __seg *`, which is a 16-bit
// segment-only pointer. Converting to a `far *` yields a full segment:offset
// pointer to offset 0000h of that segment.
dialog_p = (unsigned char far *)hmem_allocbyte(/* … */);
// Running the dialog script involves pointer arithmetic. On a far pointer,
// this only affects the 16-bit offset part, complete with overflow at 64 KiB,
// from FFFFh back to 0000h.
dialog_p += /* … */;
dialog_p += /* … */;
dialog_p += /* … */;
// Since the segment part of the pointer is still identical to the one we
// allocated above, we can later correctly free the buffer by pulling the
// segment back out of the pointer.
hmem_free((void __seg *)dialog_p);
If dialog_p was a huge pointer, any pointer
arithmetic would have also adjusted the segment part, requiring a second
pointer to store the base address for the hmem_free call. Doing
that will also be necessary for any port to a flat memory model. Depending
on how you look at it, this compression of two logical pointers into a
single variable is either quite nice, or really, really dumb in its
reliance on the precise memory model of one single architecture.
Why look at dialog loading though, wasn't this supposed to be all about
shared boss functions? Well, TH04 unnecessarily puts certain stage-specific
code into the boss defeat function, such as loading the alternate Stage 5
Yuuka defeat dialog before a Bad Ending, or initializing Gengetsu after
Mugetsu's defeat in the Extra Stage.
That's TH04's second core function with an explicit conditional branch for
Gengetsu, after the
📝 dialog exit code we found last year during EMS research.
And I've heard people say that Shinki was the most hardcoded fight in PC-98
Touhou… Really, Shinki is a perfectly regular boss, who makes proper use of
all internal mechanics in the way they were intended, and doesn't blast
holes into the architecture of the game. Even within TH05, it's Mai and Yuki
who rely on hacks and duplicated code, not Shinki.
The worst part about this though? How the function distinguishes Mugetsu
from Gengetsu. Once again, it uses its own global variable to track whether
it is called the first or the second time within TH04's Extra Stage,
unrelated to the same variable used in the dialog exit function. But this
time, it's not just any newly created, single-use variable, oh no. In a
misguided attempt to micro-optimize away a few bytes of conventional memory,
TH04 reserves 16 bytes of "generic boss state", which can (and are) freely
used for anything a boss doesn't want to store in a more dedicated
variable.
It might have been worth it if the bosses actually used most of these
16 bytes, but the majority just use (the same) two, with only Stage 4 Reimu
using a whopping seven different ones. To reverse-engineer the various uses
of these variables, I pretty much had to map out which of the undecompiled
danmaku-pattern functions corresponds to which boss
fight. In the end, I assigned 29 different variable names for each of the
semantically different use cases, which made up another full push on its
own.
Now, 16 bytes of wildly shared state, isn't that the perfect recipe for
bugs? At least during this cursory look, I haven't found any obvious ones
yet. If they do exist, it's more likely that they involve reused state from
earlier bosses – just how the Shinki death glitch in
TH05 is caused by reusing cheeto data from way back in Stage 4 – and
hence require much more boss-specific progress.
And yes, it might have been way too early to look into all these tiny
details of specific boss scripts… but then, this happened:
Looks similar to another
screenshot of a crash in the same fight that was reported in December,
doesn't it? I was too much in a hurry to figure it out exactly, but notice
how both crashes happen right as the last of Marisa's four bits is destroyed.
KirbyComment has suspected
this to be the cause for a while, and now I can pretty much confirm it
to be an unguarded division by the number of on-screen bits in
Marisa-specific pattern code. But what's the cause for Kurumi then?
As for fixing it, I can go for either a fast or a slow option:
Superficially fixing only this crash will probably just take a fraction
of a push.
But I could also go for a deeper understanding by looking at TH04's
version of the 📝 custom entity structure. It
not only stores the data of Marisa's bits, but is also very likely to be
involved in Kurumi's crash, and would get TH04 a lot closer to 100%
PI. Taking that look will probably need at least 2 pushes, and might require
another 3-4 to completely decompile Marisa's fight, and 2-3 to decompile
Kurumi's.
OK, now that that's out of the way, time to finish the boss defeat function…
but not without stumbling over the third of TH04's quirks, relating to the
Clear Bonus for the main game or the Extra Stage:
To achieve the incremental addition effect for the in-game score display
in the HUD, all new points are first added to a score_delta
variable, which is then added to the actual score at a maximum rate of
61,110 points per frame.
There are a fixed 416 frames between showing the score tally and
launching into MAINE.EXE.
As a result, TH04's Clear Bonus is effectively limited to
(416 × 61,110) = 25,421,760 points.
Only TH05 makes sure to commit the entirety of the
score_delta to the actual score before switching binaries,
which fixes this issue.
And after another few collision-related functions, we're now truly,
finally ready to decompile bosses in both TH04 and TH05! Just as the
anything funds were running out… The
remaining ¼ of the third push then went to Shinki's 32×32 ball bullets,
rounding out this delivery with a small self-contained piece of the first
TH05 boss we're probably going to look at.
Next up, though: I'm not sure, actually. Both Shinki and Elis seem just a
little bit larger than the 2¼ or 4 pushes purchased so far, respectively.
Now that there's a bunch of room left in the cap again, I'll just let the
next contribution decide – with a preference for Shinki in case of a tie.
And if it will take longer than usual for the store to sell out again this
time (heh), there's still the
📝 PC-98 text RAM JIS trail word rendering research
waiting to be documented.
 The 4 📝 bits used in Marisa's Stage 4 boss
fight. Coincidentally also related to the rare
The 4 📝 bits used in Marisa's Stage 4 boss
fight. Coincidentally also related to the rare  Stage 4 Reimu's spinning orbs. Note how the game uses two different sets
of sprites just to have two different outline colors. This was probably
better than messing with the palette, which can easily cause unintended
effects if you only have 16 colors to work with. Heck, I have an entire blog post tag just to highlight
these cases. Capped to the full 32 entities.
Stage 4 Reimu's spinning orbs. Note how the game uses two different sets
of sprites just to have two different outline colors. This was probably
better than messing with the palette, which can easily cause unintended
effects if you only have 16 colors to work with. Heck, I have an entire blog post tag just to highlight
these cases. Capped to the full 32 entities.
 The chasing cross bullets, seen in Phase 14 of the same Stage 6 Yuuka
fight. Featuring some smart sprite work, making use of point symmetry to
achieve a fluid animation in just 4 frames. This is
good-code in sprite form. Capped to 31 entities, because the 32nd custom entity during this fight is defined to be…
The chasing cross bullets, seen in Phase 14 of the same Stage 6 Yuuka
fight. Featuring some smart sprite work, making use of point symmetry to
achieve a fluid animation in just 4 frames. This is
good-code in sprite form. Capped to 31 entities, because the 32nd custom entity during this fight is defined to be…
 This
is strictly landmine territory though:
This
is strictly landmine territory though:

 Stage 4 Reimu's spinning orbs. Note how the game uses two different sets
of sprites just to have two different outline colors. This was probably
better than messing with the palette, which can easily cause unintended
effects if you only have 16 colors to work with. Heck,
Stage 4 Reimu's spinning orbs. Note how the game uses two different sets
of sprites just to have two different outline colors. This was probably
better than messing with the palette, which can easily cause unintended
effects if you only have 16 colors to work with. Heck, 








 is still alive, or all of them have been destroyed.
is still alive, or all of them have been destroyed.