- 📝 Posted:
- 🚚 Summary of:
- P0240, P0241
- ⌨ Commits:
be69ab6...40c900f,40c900f...08352a5- 💰 Funded by:
- JonathKane, Blue Bolt, [Anonymous]
- 🏷 Tags:
Well, well. My original plan was to ship the first step of Shuusou Gyoku
OpenGL support on the next day after this delivery. But unfortunately, the
complications just kept piling up, to a point where the required solutions
definitely blow the current budget for that goal. I'm currently sitting on
over 70 commits that would take at least 5 pushes to deliver as a meaningful
release, and all of that is just rearchitecting work, preparing the
game for a not too Windows-specific OpenGL backend in the first place. I
haven't even written a single line of OpenGL yet… 🥲
This shifts the intended Big Release Month™ to June after all. Now I know
that the next round of Shuusou Gyoku features should better start with the
SC-88Pro recordings, which are much more likely to get done within their
current budget. At least I've already completed the configuration versioning
system required for that goal, which leaves only the actual audio part.
So, TH04 position independence. Thanks to a bit of funding for stage
dialogue RE, non-ASCII translations will soon become viable, which finally
presents a reason to push TH04 to 100% position independence after
📝 TH05 had been there for almost 3 years. I
haven't heard back from Touhou Patch Center about how much they want to be
involved in funding this goal, if at all, but maybe other backers are
interested as well.
And sure, it would be entirely possible to implement non-ASCII translations
in a way that retains the layout of the original binaries and can be easily
compared at a binary level, in case we consider translations to be a
critical piece of infrastructure. This wouldn't even just be an exercise in
needless perfectionism, and we only have to look to Shuusou Gyoku to realize
why: Players expected
that my builds were compatible with existing SpoilerAL SSG files, which
was something I hadn't even considered the need for. I mean, the game is
open-source 📝 and I made it easy to build.
You can just fork the code, implement all the practice features you want in
a much more efficient way, and I'd probably even merge your code into my
builds then?
But I get it – recompiling the game yields just yet another build that can't
be easily compared to the original release. A cheat table is much more
trustworthy in giving players the confidence that they're still practicing
the same original game. And given the current priorities of my backers,
it'll still take a while for me to implement proof by replay validation,
which will ultimately free every part of the community from depending on the
original builds of both Seihou and PC-98 Touhou.
However, such an implementation within the original binary layout would
significantly drive up the budget of non-ASCII translations, and I sure
don't want to constantly maintain this layout during development. So, let's
chase TH04 position independence like it's 2020, and quickly cover a larger
amount of PI-relevant structures and functions at a shallow level. The only
parts I decompiled for now contain calculations whose intent can't be
clearly communicated in ASM. Hitbox visualizations or other more in-depth
research would have to wait until I get to the proper decompilation of these
features.
But even this shallow work left us with a large amount of TH04-exclusive
code that had its worst parts RE'd and could be decompiled fairly quickly.
If you want to see big TH04 finalization% gains, general TH04 progress would
be a very good investment.
The first push went to the often-mentioned stage-specific custom entities
that share a single statically allocated buffer. Back in 2020, I
📝 wrongly claimed that these were a TH05 innovation,
but the system actually originated in TH04. Both games use a 26-byte
structure, but TH04 only allocates a 32-element array rather than TH05's
64-element one. The conclusions from back then still apply, but I also kept
wondering why these games used a static array for these entities to begin
with. You know what they call an area of memory that you can cleanly
repurpose for things? That's right, a heap! ![]() And absolutely no one would mind one additional heap allocation at the start
of a stage, next to the ones for all the sprites and portraits.
And absolutely no one would mind one additional heap allocation at the start
of a stage, next to the ones for all the sprites and portraits.
However, we are still running in Real Mode with segmented memory. Accessing
anything outside a common data segment involves modifying segment registers,
which has a nonzero CPU cycle cost, and Turbo C++ 4.0J is terrible at
optimizing away the respective instructions. Does this matter? Probably not,
but you don't take "risks" like these if you're in a permanent
micro-optimization mindset… ![]()
In TH04, this system is used for:
Kurumi's symmetric bullet spawn rays, fired from her hands towards the left and right edges of the playfield. These are rather infamous for being the last thing you see before 📝 the
Divide Errorcrash that can happen in ZUN's original build. Capped to 6 entities. The 4 📝 bits used in Marisa's Stage 4 boss
fight. Coincidentally also related to the rare
The 4 📝 bits used in Marisa's Stage 4 boss
fight. Coincidentally also related to the rare Divide Errorcrash in that fight. Stage 4 Reimu's spinning orbs. Note how the game uses two different sets
of sprites just to have two different outline colors. This was probably
better than messing with the palette, which can easily cause unintended
effects if you only have 16 colors to work with. Heck, I have an entire blog post tag just to highlight
these cases. Capped to the full 32 entities.
Stage 4 Reimu's spinning orbs. Note how the game uses two different sets
of sprites just to have two different outline colors. This was probably
better than messing with the palette, which can easily cause unintended
effects if you only have 16 colors to work with. Heck, I have an entire blog post tag just to highlight
these cases. Capped to the full 32 entities.
 The chasing cross bullets, seen in Phase 14 of the same Stage 6 Yuuka
fight. Featuring some smart sprite work, making use of point symmetry to
achieve a fluid animation in just 4 frames. This is
good-code in sprite form. Capped to 31 entities, because the 32nd custom entity during this fight is defined to be…
The chasing cross bullets, seen in Phase 14 of the same Stage 6 Yuuka
fight. Featuring some smart sprite work, making use of point symmetry to
achieve a fluid animation in just 4 frames. This is
good-code in sprite form. Capped to 31 entities, because the 32nd custom entity during this fight is defined to be…
The single purple pulsating and shrinking safety circle, seen in Phase 4 of the same fight. The most interesting aspect here is actually still related to the cross bullets, whose spawn function is wrongly limited to 32 entities and could theoretically overwrite this circle.
 This
is strictly landmine territory though:
This
is strictly landmine territory though:- Yuuka never uses these bullets and the safety circle simultaneously
- She never spawns more than 24 cross bullets
- All cross bullets are fast enough to have left the screen by the time Yuuka restarts the corresponding subpattern
- The cross bullets spawn at Yuuka's center position, and assign its Q12.4 coordinates to structure fields that the safety circle interprets as raw pixels. The game does try to render the circle afterward, but since Yuuka's static position during this phase is nowhere near a valid pixel coordinate, it is immediately clipped.
The flashing lines seen in Phase 5 of the Gengetsu fight, telegraphing the slightly random bullet columns.


 Stage 4 Reimu's spinning orbs. Note how the game uses two different sets
of sprites just to have two different outline colors. This was probably
better than messing with the palette, which can easily cause unintended
effects if you only have 16 colors to work with. Heck,
Stage 4 Reimu's spinning orbs. Note how the game uses two different sets
of sprites just to have two different outline colors. This was probably
better than messing with the palette, which can easily cause unintended
effects if you only have 16 colors to work with. Heck, These structures only took 1 push to reverse-engineer rather than the 2 I needed for their TH05 counterparts because they are much simpler in this game. The "structure" for Gengetsu's lines literally uses just a single X position, with the remaining 24 bytes being basically padding. The only minor bug I found on this shallow level concerns Marisa's bits, which are clipped at the right and bottom edges of the playfield 16 pixels earlier than you would expect:
The remaining push went to a bunch of smaller structures and functions:
- The structure for the up to 2 "thick" (a.k.a. "Master Spark") lasers. Much saner than the 📝 madness of TH05's laser system while being equally customizable in width and duration.
-
The structure for the various monochrome 16×16 shapes in the background of
the Stage 6 Yuuka fight, drawn on top of the checkerboard.




-
The rendering code for the three falling stars in the background of Stage 5.
The effect here is entirely palette-related: After blitting the stage tiles,
the 📝 1bpp star image is
ORed into only the 4th VRAM plane, which is equivalent to setting the highest bit in the palette color index of every pixel within the star-shaped region. This of course raises the question of how the stage would look like if it was fully illuminated:

The full tile map of TH04's Stage 5, in both dark and fully illuminated views. Since the illumination effect depends on two matching sets of palette colors that are distinguished by a single bit, the illuminated view is limited to only 8 of the 16 colors. The dark view, on the other hand, can freely use colors from the illuminated set, since those are unaffected by the ORoperation. -
Most code that modifies a stage's tile map, and directly specifies tiles via
their top-left offset in VRAM.
Thanks to code alignment reasons, this forced a much longer detour into the .STD format loader. Nothing all too noteworthy there since we're still missing the enemy script and spawn structures before we can call .STD "reverse-engineered", but maybe still helpful if you're looking for an overview of the format. Also features a buffer overflow landmine if a .STD file happens to contain more than 32 enemy scripts… you know, the usual stuff.
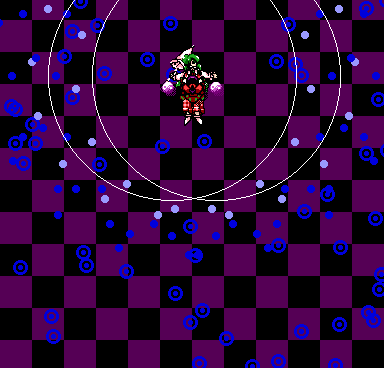
To top off the second push, we've got the vertically scrolling checkerboard background during the Stage 6 Yuuka fight, made up of 32×32 squares. This one deserves a special highlight just because of its needless complexity. You'd think that even a performant implementation would be pretty simple:
- Set the GRCG to TDW mode
- Set the GRCG tile to one of the two square colors
- Start with Y as the current scroll offset, and X as some indicator of which color is currently shown at the start of each row of squares
- Iterate over all lines of the playfield, filling in all pixels that should be displayed in the current color, skipping over the other ones
- Count down Y for each line drawn
- If Y reaches 0, reset it to 32 and flip X
- At the bottom of the playfield, change the GRCG tile to the other color, and repeat with the initial value of X flipped
The most important aspect of this algorithm is how it reduces GRCG state
changes to a minimum, avoiding the costly port I/O that we've identified
time and time again as one of the main bottlenecks in TH01. With just 2
state variables and 3 loops, the resulting code isn't that complex either. A
naive implementation that just drew the squares from top to bottom in a
single pass would barely be simpler, but much slower: By changing the GRCG
tile on every color, such an implementation would burn a low 5-digit number
of CPU cycles per frame for the 12×11.5-square checkerboard used in the
game.
And indeed, ZUN retained all important aspects of this algorithm… but still
implemented it all in ASM, with a ridiculous layer of x86 segment arithmetic
on top? ![]() Which blows up the complexity to 4 state
variables, 5 nested loops, and a bunch of constants in unusual units. I'm
not sure what this code is supposed to optimize for, especially with that
rather questionable register allocation that nevertheless leaves one of the
general-purpose registers unused.
Which blows up the complexity to 4 state
variables, 5 nested loops, and a bunch of constants in unusual units. I'm
not sure what this code is supposed to optimize for, especially with that
rather questionable register allocation that nevertheless leaves one of the
general-purpose registers unused. ![]() Fortunately,
the function was still decompilable without too many code generation hacks,
and retains the 5 nested loops in all their
Fortunately,
the function was still decompilable without too many code generation hacks,
and retains the 5 nested loops in all their goto-connected
glory. If you want to add a checkerboard to your next PC-98
demo, just stick to the algorithm I gave above.
(Using a single XOR for flipping the starting X offset between 32 and 64
pixels is pretty nice though, I have to give him that.)
This makes for a good occasion to talk about the third and final GRCG mode,
completing the series I started with my previous coverage of the
📝 RMW and
📝 TCR modes. The TDW (Tile Data Write) mode
is the simplest of the three and just writes the 8×1 GRCG tile into VRAM
as-is, without applying any alpha bitmask. This makes it perfect for
clearing rectangular areas of pixels – or even all of VRAM by doing a single
memset():
// Set up the GRCG in TDW mode. outportb(0x7C, 0x80); // Fill the tile register with color #7 (0111 in binary). outportb(0x7E, 0xFF); // Plane 0: (B): (********) outportb(0x7E, 0xFF); // Plane 1: (R): (********) outportb(0x7E, 0xFF); // Plane 2: (G): (********) outportb(0x7E, 0x00); // Plane 3: (E): ( ) // Set the 32 pixels at the top-left corner of VRAM to the exact contents of // the tile register, effectively repeating the tile 4 times. In TDW mode, the // GRCG ignores the CPU-supplied operand, so we might as well just pass the // contents of a register with the intended width. This eliminates useless load // instructions in the compiled assembly, and even sort of signals to readers // of this code that we do not care about the source value. *reinterpret_cast<uint32_t far *>(MK_FP(0xA800, 0)) = _EAX; // Fill the entirety of VRAM with the GRCG tile. A simple C one-liner that will // probably compile into a single `REP STOS` instruction. Unfortunately, Turbo // C++ 4.0J only ever generates the 16-bit `REP STOSW` here, even when using // the `__memset__` intrinsic and when compiling in 386 mode. When targeting // that CPU and above, you'd ideally want `REP STOSD` for twice the speed. memset(MK_FP(0xA800, 0), _AL, ((640 / 8) * 400));
However, this might make you wonder why TDW mode is even necessary. If it's
functionally equivalent to RMW mode with a CPU-supplied bitmask made up
entirely of 1 bits (i.e., 0xFF, 0xFFFF, or
0xFFFFFFFF), what's the point? The difference lies in the
hardware implementation: If all you need to do is write tile data to
VRAM, you don't need the read and modify parts of RMW mode
which require additional processing time. The PC-9801 Programmers'
Bible claims a speedup of almost 2× when using TDW mode over equivalent
operations in RMW mode.
And that's the only performance claim I found, because none of these old
PC-98 hardware and programming books did any benchmarks. Then again, it's
not too interesting of a question to benchmark either, as the byte-aligned
nature of TDW blitting severely limits its use in a game engine anyway.
Sure, maybe it makes sense to temporarily switch from RMW to TDW mode
if you've identified a large rectangular and byte-aligned section within a
sprite that could be blitted without a bitmask? But the necessary
identification work likely nullifies the performance gained from TDW mode,
I'd say. In any case, that's pretty deep
micro-optimization territory. Just use TDW mode for the
few cases it's good at, and stick to RMW mode for the rest.
So is this all that can be said about the GRCG? Not quite, because there are 4 bits I haven't talked about yet…
And now we're just 5.37% away from 100% position independence for TH04! From
this point, another 2 pushes should be enough to reach this goal. It might
not look like we're that close based on the current estimate, but a
big chunk of the remaining numbers are false positives from the player shot
control functions. Since we've got a very special deadline to hit, I'm going
to cobble these two pushes together from the two current general
subscriptions and the rest of the backlog. But you can, of course, still
invest in this goal to allow the existing contributions to go to something
else.
… Well, if the store was actually open. ![]() So I'd better
continue with a quick task to free up some capacity sooner rather than
later. Next up, therefore: Back to TH02, and its item and player systems.
Shouldn't take that long, I'm not expecting any surprises there. (Yeah, I
know, famous last words…)
So I'd better
continue with a quick task to free up some capacity sooner rather than
later. Next up, therefore: Back to TH02, and its item and player systems.
Shouldn't take that long, I'm not expecting any surprises there. (Yeah, I
know, famous last words…)