I'm 13 days late, but 🎉 ReC98 is now 10 years old! 🎉 On June 26, 2014, I first tried exporting IDA's disassembly of TH05's OP.EXE and reassembling and linking the resulting file back into a binary, and was amazed that it actually yielded an identical binary. Now, this doesn't actually mean that I've spent 10 years working on this project; priorities have been shifting and continue to shift, and time-consuming mistakes were certainly made. Still, it's a good occasion to finally fully realize the good future for ReC98 that GhostPhanom invested in with the very first financial contribution back in 2018, deliver the last three of the first four reserved pushes, cross another piece of time-consuming maintenance off the list, and prepare the build process for hopefully the next 10 years.
But why did it take 8 pushes and over two months to restore feature parity with the old system? 🥲
The original plan for ReC98's good future was quite different from what I ended up shipping here. Before I started writing the code for this website in August 2019, I focused on feature-completing the experimental 16-bit DOS build system for Borland compilers that I'd been developing since 2018, and which would form the foundation of my internal development work in the following years. Eventually, I wanted to polish and publicly release this system as soon as people stopped throwing money at me. But as of November 2019, just one month after launch, the store kept selling out with everyone investing into all the flashier goals, so that release never happened.
In theory, this build system remains the optimal way of developing with old Borland compilers on a real PC-98 (or any other 32-bit single-core system) and outside of Borland's IDE, even after the changes introduced by this delivery. In practice though, you're soon going to realize that there are lots of issues I'd have to revisit in case any PC-98 homebrew developers are interested in funding me to finish and release this tool…
The main idea behind the system still has its charm: Your build script is a regular C++ program that #includes the build system as a static library and passes fixed structures with names of source files and build flags. By employing static constructors, even a 1994 Turbo C++ would let you define the whole build at compile time, although this certainly requires some dank preprocessor magic to remain anywhere near readable at ReC98 scale. 🪄 While this system does require a bootstrapping process, the resulting binary can then use the same dependency-checking mechanisms to recompile and overwrite itself if you change the C++ build code later. Since DOS just simply loads an entire binary into RAM before executing it, there is no lock to worry about, and overwriting the originating binary is something you can just do.
Later on, the system also made use of batched compilation: By passing more than one source file to TCC.EXE, you get to avoid TCC's quite noticeable startup times, thus speeding up the build proportional to the number of translation units in each batch. Of course, this requires that every passed source file is supposed to be compiled with the same set of command-line flags, but that's a generally good complexity-reducing guideline to follow in a build script. I went even further and enforced this guideline in the system itself, thus truly making per-file compiler command line switches considered harmful. Thanks to Turbo C++'s #pragma option, changing the command line isn't even necessary for the few unfortunate cases where parts of ZUN's code were compiled with inconsistent flags.
I combined all these ideas with a general approach of "targeting DOSBox": By maximizing DOS syscalls and minimizing algorithms and data structures, we spend as much time as possible in DOSBox's native-code DOS implementation, which should give us a performance advantage over DOS-native implementations of MAKE that typically follow the opposite approach.
Of course, all this only matters if the system is correct and reliable at its core. Tup teaches us that it's fundamentally impossible to have a reliable generic build system without
augmenting the build graph with all actual files read and written by each invoked build tool, which involves tracing all file-related syscalls, and
persistently serializing the full build graph every time the system runs, allowing later runs to detect every possible kind of change in the build script and rebuild or clean up accordingly.
Unfortunately, the design limitations of my system only allowed half-baked attempts at solving both of these prerequisites:
If your build system is not supposed to be generic and only intended to work with specific tools that emit reliable dependency information, you can replace syscall tracing with a parser for those specific formats. This is what my build system was doing, reading dependency information out of each .OBJ file's OMF COMENT record.
Since DOS command lines are limited to 127 bytes, DOS compilers support reading additional arguments from response files, typically indicated with an @ next to their path on the command line. If we now put every parameter passed to TCC or TLINK into a response file and leave these files on disk afterward, we've effectively serialized all command-line arguments of the entire build into a makeshift database. In later builds, the system can then detect changed command-line arguments by comparing the existing response files from the previous run with the new contents it would write based on the current build structures. This way, we still only recompile the parts of the codebase that are affected by the changed arguments, which is fundamentally impossible with Makefiles.
But this strategy only covers changes within each binary's compile or link arguments, and ignores the required deletions in "the database" when removing binaries between build runs. This is a non-issue as long as we keep decompiling on master, but as soon as we switch between master and similarly old commits on the debloated/anniversary branches, we can get very confusing errors:
The symptom is a calling convention mismatch: The two vector functions use __cdecl on master and pascal on debloated/anniversary. We've switched from anniversary (which compiles to ANNIV.EXE) back to master (which compiles to REIIDEN.EXE) here, so the .obj file on disk still uses the pascal calling convention. The build system, however, only checks the response files associated with the current target binary (REIIDEN.EXE) and therefore assumes that the .obj files still reflect the (unchanged) command-line flags in the TCC response file associated with this binary. And if none of the inputs of these .obj files changed between the two branches, they aren't rebuilt after switching, even though they would need to be.
Apparently, there's also such a thing as "too much batching", because TCC would suddenly stop applying certain compiler optimizations at very specific places if too many files were compiled within a single process? At least you quickly remember which source files you then need to manually touch and recompile to make the binaries match ZUN's original ones again…
But the final nail in the coffin was something I'd notice on every single build: 5 years down the line, even the performance argument wasn't convincing anymore. The strategy of minimizing emulated code still left me with an 𝑂(𝑛) algorithm, and with this entire thing still being single-threaded, there was no force to counteract the dependency check times as they grew linearly with the number of source files.
At P0280, each build run would perform a total of 28,130 file-related DOS syscalls to figure out which source files have changed and need to be rebuilt. At some point, this was bound to become noticeable even despite these syscalls being native, not to mention that they're still surrounded by emulator code that must convert their parameters and results to and from the DOS ABI. And with the increasing delays before TCC would do its actual work, the entire thing started feeling increasingly jankier.
While this system was waiting to be eventually finished, the public master branch kept using the Makefile that dates back to early 2015. Back then, it didn't takelong for me to abandon raw dumb batch files because Make was simply the most straightforward way of ensuring that the build process would abort on the first compile error.
The following years also proved that Makefile syntax is quite well-suited for expressing the build rules of a codebase at this scale. The built-in support for automatically turning long commands into response files was especially helpful because of how naturally it works together with batched compilation. Both of these advantages culminate in this wonderfully arcane incantation of ASCII special characters and syntactically significant linebreaks:
tcc … @&&|
$**
|
Which translates to "take the filenames of all dependents of this explicit rule, write them into a temporary file with an autogenerated name, insert this filename into the tcc … @ command line, and delete the file after the command finished executing". The @ is part of TCC's command-line interface, the rest is all MAKE syntax.
But 📝 as we all know by now, these surface-level niceties change nothing about Makefiles inherently being unreliable trash due to implementing none of the aforementioned two essential properties of a generic build system. Borland got so close to a correct and reliable implementation of autodependencies, but that would have just covered one of the two properties. Due to this unreliability, the old build16b.bat called Borland's MAKER.EXE with the -B flag, recompiling everything all the time. Not only did this leave modders with a much worse build process than I was using internally, but it also eventually got old for me to merge my internal branch onto master before every delivery. Let's finally rectify that and work towards a single good build process for everyone.
As you would expect by now, I've once again migrated to Tup's Lua syntax. Rewriting it all makes you realize once again how complex the PC-98 Touhou build process is: It has to cover 2 programming languages, 2 pipeline steps, and 3 third-party libraries, and currently generates a total of 39 executables, including the small programs I wrote for research. The final Lua code comprises over 1,300 lines – but then again, if I had written it in 📝 Zig, it would certainly be as long or even longer due to manual memory management. The Tup building blocks I constructed for Shuusou Gyoku quickly turned out to be the wrong abstraction for a project that has no debug builds, but their 📝 basic idea of a branching tree of command-line options remained at the foundation of this script as well.
This rewrite also provided an excellent opportunity for finally dumping all the intermediate compilation outputs into a separate dedicated obj/ subdirectory, finally leaving bin/ nice and clean with only the final executables. I've also merged this new system into most of the public branches of the GitHub repo.
As soon as I first tried to build it all though, I was greeted with a particularly nasty Tup bug. Due to how DOS specified file metadata mutation, MS-DOS Player has to open every file in a way that current Tup treats as a write access… but since unannotated file writes introduce the risk of a malformed build graph if these files are read by another build command later on, Tup providently deletes these files after the command finished executing. And by these files, I mean TCC.EXE as well as every one of its C library header files opened during compilation.
Due to a minor unsolved question about a failing test case, my fix has not been merged yet. But even if it was, we're now faced with a problem: If you previously chose to set up Tup for ReC98 or 📝 Shuusou Gyoku and are maybe still running 📝 my 32-bit build from September 2020, running the new build.bat would in fact delete the most important files of your Turbo C++ 4.0J installation, forcing you to reinstall it or restore it from a backup. So what do we do?
Should my custom build get a special version number so that the surrounding batch file can fail if the version number of your installed Tup is lower?
Or do I just put a message somewhere, which some people invariably won't read?
The easiest solution, however, is to just put a fixed Tup binary directly into the ReC98 repo. This not only allows me to make Tup mandatory for 64-bit builds, but also cuts out one step in the build environment setup that at least one person previously complained about. *nix users might not like this idea all too much (or do they?), but then again, TASM32 and the Windows-exclusive MS-DOS Player require Wine anyway. Running Tup through Wine as well means that there's only one PATH to worry about, and you get to take advantage of the tool checks in the surrounding batch file.
If you're one of those people who doesn't trust binaries in Git repos, the repo also links to instructions for building this binary yourself. Replicating this specific optimized binary is slightly more involved than the classic ./configure && make && make install trinity, so having these instructions is a good idea regardless of the fact that Tup's GPL license requires it.
One particularly interesting aspect of the Lua code is the way it handles sprite dependencies:
If build commands read from files that were created by other build commands, Tup requires these input dependencies to be spelled out so that it can arrange the build graph and parallelize the build correctly. We could simply put every sprite into a single array and automatically pass that as an extra input to every source file, but that would effectively split the build into a "sprite convert" and "code compile" phase. Spelling out every individual dependency allows such source files to be compiled as soon as possible, before (and in parallel to) the rest of the sprites they don't depend on. Similarly, code files without sprite dependencies can compile before the first sprite got converted, or even before the sprite converter itself got compiled and linked, maximizing the throughput of the overall build process.
Running a 30-year-old DOS toolchain in a parallel build system also introduces new issues, though. The easiest and recommended way of compiling and linking a program in Turbo C++ is a single tcc invocation:
tcc … main.cpp utils.cpp master.lib
This performs a batched compilation of main.cpp and utils.cpp within a single TCC process, and then launches TLINK to link the resulting .obj files into main.exe, together with the C++ runtime library and any needed objects from master.lib. The linking step works by TCC generating a TLINK command line and writing it into a response file with the fixed name turboc.$ln… which obviously can't work in a parallel build where multiple TCC processes will want to link different executables via the same response file.
Therefore, we have to launch TLINK with a custom response file ourselves. This file is echo'd as a separate parallel build rule, and the Lua code that constructs its contents has to replicate TCC's logic for picking the correct C++ runtime .lib file for the selected memory model.
The response file for TH02's ZUN_RES.COM, consisting of the C++ standard library, two files of ZUN code, and master.lib.
While this does add more string formatting logic, not relying on TCC to launch TLINK actually removes the one possible PATH-related error case I previously documented in the README. Back in 2021 when I first stumbled over the issue, it took a few hours of RE to figure this out. I don't like these hours to go to waste, so here's a Gist, and here's the text replicated for SEO reasons:
Issue: TCC compiles, but fails to link, with Unable to execute command 'tlink.exe'
Cause: This happens when invoking TCC as a compiler+linker, without the -c flag. To locate TLINK, TCC needlessly copies the PATH environment variable into a statically allocated 128-byte buffer. It then constructs absolute tlink.exe filenames for each of the semicolon- or \0-terminated paths, writing these into a buffer that immediately follows the 128-byte PATH buffer in memory. The search is finished as soon as TCC finds an existing file, which gives precedence to earlier paths in the PATH. If the search didn't complete until a potential "final" path that runs past the 128 bytes, the final attempted filename will consist of the part that still managed to fit into the buffer, followed by the previously attempted path.
Workaround: Make sure that the BIN\ path to Turbo C++ is fully contained within the first 127 bytes of the PATH inside your DOS system. (The 128th byte must either be a separating ; or the terminating \0 of the PATH string.)
Now that DOS emulation is an integral component of the single-part build process, it even makes sense to compile our pipeline tools as 16-bit DOS executables and then emulate them as part of the build. Sure, it's technically slower, but realistically it doesn't matter: Our only current pipeline tools are 📝 the converter for hardcoded sprites and the 📝 ZUN.COM generators, both of which involve very little code and are rarely run during regular development after the initial full build. In return, we get to drop that awkward dependency on the separate Borland C++ 5.5 compiler for Windows and yet another additional manual setup step. 🗑️ Once PC-98 Touhou becomes portable, we're probably going to require a modern compiler anyway, so you can now delete that one as well.
That gives us perfect dependency tracking and minimal parallel rebuilds across the whole codebase! While MS-DOS Player is noticeably slower than DOSBox-X, it's not going to matter all too much; unless you change one of the more central header files, you're rarely if ever going to cause a full rebuild. Then again, given that I'm going to use this setup for at least a couple of years, it's worth taking a closer look at why exactly the compilation performance is so underwhelming …
On the surface, MS-DOS Player seems like the right tool for our job, with a lot of advantages over DOSBox:
It doesn't spawn a window that boots an entire emulated PC, but is instead
perfectly integrated into the Windows console. Using it in a modern developer console would allow you to click on a compile error and have your editor immediately open the relevant file and jump to that specific line! With DOSBox, this basic comfort feature was previously unthinkable.
Heck, Takeda Toshiya originally developed it to run the equally vintage LSI C-86 compiler on 64-bit Windows. Fixing any potential issues we'd run into would be well within the scope of the project.
It consists of just a single comparatively small binary that we could just drop into the ReC98 repo. No manual setup steps required.
But once I began integrating it, I quickly noticed two glaring flaws:
Back in 2009, Takeda Toshiya chose to start the project by writing a custom DOS implementation from scratch. He was aware of DOSBox, but only adapted small tricky parts of its source code rather than starting with the DOSBox codebase and ripping out everything he didn't need. This matches the more research-oriented nature that all of his projects appear to follow, where the primary goal of writing the code is a personal understanding of the problem domain rather than a widely usable piece of software. MS-DOS Player is even the outlier in this regard, with Takeda Toshiya describing it as 珍しく実用的かもしれません. I am definitely sympathetic to this mindset; heck, my old internal build system falls under this category too, being so specialized and narrow that it made little sense to use it outside of ReC98. But when you apply it to emulators for niche systems, you end up with exactly the current PC-98 emulation scene, where there's no single universally good emulator because all of them have some inaccuracy somewhere. This scene is too small for you not to eventually become part of someone else's supply chain… 🥲
Emulating DOS is a particularly poor fit for a research/NIH project because it's Hyrum's Law incarnate. With the lack of memory protection in Real Mode, programs could freely access internal DOS (and even BIOS) data structures if they only knew where to look, and frequently did. It might look as if "DOS command-line tools" just equals x86 plus INT 21h, but soon you'll also be emulating the BIOS, PIC, PIT, EMS, XMS, and probably a few more things, all with their individual quirks that some application out there relies on. DOSBox simply had much more time to grow and mature and figure out all of these details by trial and error. If you start a DOS emulator from scratch, you're bound to duplicate all this research as people want to use your emulator to run more and more programs, until you've ended up with what's effectively a clone of DOSBox's exact logic. Unless, of course, if you draw a line somewhere and limit the scope of the DOS and BIOS emulation. But given how many people have wanted to use MS-DOS Player for running DOS TUIs in arbitrarily sized terminal windows with arbitrary fonts, that's not what happened. I guess it made sense for this use case before DOSBox-X gained a TTF output mode in late 2020?
As usual, I wouldn't mention this if I didn't run into twobugs when combining MS-DOS Player with Turbo C++ and Tup. Both of these originated from workarounds for inaccuracies in the DOS emulation that date back to MS-DOS Player's initial release and were thankfully no longer necessary with the accuracy improvements implemented in the years since.
For CPU emulation, MS-DOS Player can use either MAME's or Neko Project 21/W's x86 core, both of which are interpreters and won't win any performance contests. The NP21/W core is significantly better optimized and runs ≈41% faster, but still pales in comparison to DOSBox-X's dynamic recompiler. Running the same sequential commands that the P0280 Makefile would execute, the upstream 2024-03-02 NP21/W core build of MS-DOS Player would take to compile the entire ReC98 codebase on my system, whereas DOSBox-X's dynamic core manages the same in , or 94% faster.
Granted, even the DOSBox-X performance is much slower than we would like it to be. Most of it can be blamed on the awkward time in the early-to-mid-90s when Turbo C++ 4.0J came out. This was the time when DOS applications had long grown past the limitations of the x86 Real Mode and required DOS extenders or even sillier hacks to actually use all the RAM in a typical system of that period, but Win32 didn't exist yet to put developers out of this misery. As such, this compiler not only requires at least a 386 CPU, but also brings its own DOS extender (DPMI16BI.OVL) plus a loader for said extender (RTM.EXE), both of which need to be emulated alongside the compiler, to the great annoyance of emulator maintainers 30 years later. Even MS-DOS Player's README file notes how Protected Mode adds a lot of complexity and slowdown:
8086 binaries are much faster than 80286/80386/80486/Pentium4/IA32 binaries.
If you don't need the protected mode or new mnemonics added after 80286,
I recommend i86_x86 or i86_x64 binary.
The immediate reaction to these performance numbers is obvious: Let's just put DOSBox-X's dynamic recompiler into MS-DOS Player, right?! 🙌 Except that once you look at DOSBox-X, you immediately get why Takeda Toshiya might have preferred to start from scratch. Its codebase is a historically grown tangled mess, requiring intimate familiarity and a significant engineering effort to isolate the dynamic core in the first place. I did spend a few days trying to untangle and copy it all over into MS-DOS Player… only to be greeted with an infinite loop as soon as everything compiled for the first time. 😶 Yeah, no, that's bound to turn into a budget-exceeding maintenance nightmare.
Instead, let's look at squeezing at least some additional performance out of what we already have. A generic emulator for the entire CISCy instruction set of the 80386, with complete support for Protected Mode, but it's only supposed to run the subset of instructions and features used by a specific compiler and linker as fast as possible… wait a moment, that sounds like a use case for profile-guided optimization! This is the first time I've encountered a situation that would justify the required 2-phase build process and lengthy profile collection – after all, writing into some sort of database for every function call does slow down MS-DOS Player by roughly 15×. However, profiling just the compilation of our most complex translation unit (📝 TH01 YuugenMagan) and the linking of our largest executable (TH01's REIIDEN.EXE) should be representative enough.
I'll get to the performance numbers later, but even the build output is quite intriguing. Based on this profile, Visual Studio chooses to optimize only 104 out of MS-DOS Player's 1976 functions for speed and the rest for size, shaving off a nice 109 KiB from the binary. Presumably, keeping rare code small is also considered kind of fast these days because it takes up less space in your CPU's instruction cache once it does get executed?
With PGO as our foundation, let's run a performance profile and see if there are any further code-level optimizations worth trying out:
Removing redundant memset() calls: MS-DOS Player is written in a very C-like style of C++, and initializes a bunch of its statically allocated data by memset()ing it with 00 bytes at startup. This is strictly redundant even in C; Section 6.7.9/10 of the C standard mandates that all static data is zero-initialized by default. In turn, the program loaders of modern operating systems employ all sorts of paging tricks to reduce the CPU cost (and actual RAM usage!) of this initialization as much as possible. If you manually memset() afterward, you throw all these advantages out of the window.
Of course, these calls would only ever show up among the top CPU consumers in a performance profile if a program uses a large amount of static data, but the hardcoded 32 MiB of emulated RAM in ≥i386-supporting builds definitely qualifies. Zeroing 32.8 MiB of memory makes up a significant chunk of the runtime of some of the shorter build steps and quickly adds up; a full rebuild of the ReC98 codebase currently spawns a total of 361 MS-DOS Player instances, totaling 11.5 GiB of needless memory writes.
Limiting the emulated instruction set: NP21/W's x86 core emulates everything up to the SSE3 extension from 2004, but Turbo C++ 4.0J's x86 instruction set usage doesn't stretch past the 386. It doesn't even need the x87 FPU for compiling code that involves floating-point constants. Disabling all these unneeded extensions speeds up x86's infamously annoying instruction decoding, and also reduces the size of the MS-DOS Player binary by another 149.5 KiB. The source code already had macros for this purpose, and only needed a slight fix for the code to compile with these macros disabled.
Removing x86 paging: Borland's DOS extender uses segmented memory addressing even in Protected Mode. This allows us to remove the MMU emulation and the corresponding "are we paging" check for every memory access.
Removing cycle counting: When emulating a whole system, counting the cycles of each instruction is important for accurately synchronizing the CPU with other pieces of hardware. As hinted above, MS-DOS Player does emulate and periodically update a few pieces of hardware outside the CPU, but we need none of them for a build tool.
Testing Takeda Toshiya's optimizations: In a nice turn of events, Takeda Toshiya merged every single one of my bugfixes and optimization flags into his upstream codebase. He even agreed with my memset() and cycle counting removal optimizations, which are now part of all upstream builds as of 2024-06-24. For the 2024-06-27 build, he claims to have gone even further than my more minimal optimization, so let's see how these additional changes affect our build process.
Further risky optimizations: A lot of the remaining slowness of x86 emulation comes from the segmentation and protection fault checks required for every memory access. If we assume that the emulator only ever executes correct code, we can remove these checks and implement further shortcuts based on their absence.
The L[DEFGS]S group of instructions that load a segment and offset register from a 32-bit far pointer, for example, are both frequently used in Turbo C++ 4.0J code and particularly expensive to emulate. Intel specified their Real Mode operation as loading the segment and offset part in two separate 16-bit reads. But if we assume that neither of those reads can fault, we can compress them into a single 32-bit read and thus only perform the costly address translation once rather than twice. Emulator authors are probably rolling their eyes at this gross violation of Intel documentation now, but it's at least worth a try to see just how much performance we could get out of it.
Measured on a 6-year-old 6-core Intel Core i5 8400T on Windows 11. The first number in each column represents the codebase before the #include cleanup explained below, and the second one corresponds to this commit. All builds are 64-bit, 32-bit builds were ≈5% slower across the board. I kept the fastest run within three attempts; as Tup parallelizes the build process across all CPU cores, it's common for the long-running full build to take up to a few seconds longer depending on what else is running on your system. Tup's standard output is also redirected to a file here; its regular terminal output and nice progress bar will add more slowdown on top.
The key takeaways:
By merely disabling certain x86 features from MS-DOS Player and retaining the accuracy of the remaining emulation, we get speedups of ≈60% (full build), ≈70% (median TU), and ≈80% (largest TU).
≈25% (full build), ≈29% (median TU), and ≈41% (largest TU) of this speedup came from Visual Studio's profile-guided optimization, with no changes to the MS-DOS Player codebase.
The effects of removing cycle counting are the biggest surprise. Between ≈17% and ≈23%, just for removing one subtraction per emulated instruction? Turns out that in the absence of a "target cycle amount" setting, the x86 emulation loop previously ran for only a single cycle. This caused the PIC check to run after every instruction, followed by PIT, serial I/O, keyboard, mouse, and CRTC update code every millisecond. Without cycle counting, the x86 loop actually keeps running until a CPU exception is raised or the emulated process terminates, skipping the hardware code during the vast majority of the program's execution time.
While Takeda Toshiya's changes in the 2024-06-27 build completely throw out the cycle counter and clean up process termination, they also reintroduce the hardware updates that made up the majority of the cycle removal speedup. This explains the results we're getting: The small speedup for full rebuilds is too insignificant to bother with and might even fall within a statistical margin of error, but the build slows down more and more the longer the emulated process runs. Compiling and linking YuugenMagan takes a whole 14% longer on generic builds, and ≈9-12% longer on PGO builds. I did another in-between test that just removed the x86 loop from the cycle removal version, and got exactly the same numbers. This just goes to show how much removing two writes to a fixed memory address per emulated instruction actually matters. Let's not merge back this one, and stay on top of 2024-06-24 for the time being.
The risky optimizations of ignoring segment limits and speeding up 32-bit segment+offset pointer load instructions could yield a further speedup. However, most of these changes boil down to removing branches that would never be taken when emulating correct x86 code. Consequently, these branches get recorded as unlikely during PGO training, which then causes the profile-guided rebuild to rearrange the instructions on these branches in a way that favors the common case, leaving the rest of their effective removal to your CPU's branch predictor. As such, the 10%-15% speedup we can observe in generic builds collapses down to 2%-6% in PGO builds. At this rate and with these absolute durations, it's not worth it to maintain what's strictly a more inaccurate fork of Neko Project 21/W's x86 core.
The redundant header inclusions afforded by #include guards do in fact have a measurable performance cost on Turbo C++ 4.0J, slowing down compile times by 5%.
But how does this compare to DOSBox-X's dynamic core? Dynamic recompilers need some kind of cache to ensure that every block of original ASM gets recompiled only once, which gives them an advantage in long-running processes after the initial warmup. As a result, DOSBox-X compiles and links YuugenMagan in , ≈92% faster than even our optimized MS-DOS Player build. That percentage resembles the slowdown we were initially getting when comparing full rebuilds between DOSBox-X and MS-DOS Player, as if we hadn't optimized anything.
On paper, this would mean that DOSBox-X barely lost any of its huge advantage when it comes to single-threaded compile+link performance. In practice, though, this metric is supposed to measure a typical decompilation or modding workflow that focuses on repeatedly editing a single file. Thus, a more appropriate comparison would also have to add the aforementioned constant 28,130 syscalls that my old build system required to detect that this is the one file/binary that needs to be recompiled/relinked. The video at the top of this blog post happens to capture the best time () I got for the detection process on DOSBox-X. This is almost as slow as the compilation and linking itself, and would have only gotten slower as we continue decompiling the rest of the games. Tup, on the other hand, performs its filesystem scan in a near-constant , matching the claim in Section 4.7 of its paper, and thus shrinking the performance difference to ≈14% after all. Sure, merging the dynamic core would have been even better (contribution-ideas, anyone?), but this is good enough for now.
Just like with Tup, I've also placed this optimized binary directly into the ReC98 repo and added the specific build instructions to the GitHub release page.
I do have more far-reaching ideas for further optimizing Neko Project 21/W's x86 core for this specific case of repeated switches between Real Mode and Protected Mode while still retaining the interpreted nature of this core, but these already strained the budget enough.
The perhaps more important remaining bottleneck, however, is hiding in the actual DOS emulation. Right now, a Tup-driven full rebuild spawns a total of 361 MS-DOS Player processes, which means that we're booting an emulated DOS 361 times. This isn't as bad as it sounds, as "booting DOS" basically just involves initializing a bunch of internal DOS structures in conventional memory to meaningful values. However, these structures also include a few environment variables like PATH, APPEND, or TEMP/TMP, which MS-DOS Player seamlessly integrates by translating them from their value on the Windows host system to the DOS 8.3 format. This could be one of the main reasons why MS-DOS Player is a native Windows program rather than being cross-platform:
On Windows, this path translation is as simple as calling GetShortPathNameA(), which returns a unique 8.3 name for every component along the path.
Also, drive letters are an integralpart of the DOS INT 21h API, and Windows still uses them as well.
However, the NT kernel doesn't actually use drive letters either, and views them as just a legacy abstraction over its reality of volume GUIDs. Converting paths back and forth between these two views therefore requires it to communicate with a
mount point manager service, which can coincidentally also be observed in debug builds of Tup.
As a result, calling any path-retrieving API is a surprisingly expensive operation on modern Windows. When running a small sprite through our 📝 sprite converter, MS-DOS Player's boot process makes up 56% of the runtime, with 64% of that boot time (or 36% of the entire runtime) being spent on path translation. The actual x86 emulation to run the program only takes up 6.5% of the runtime, with the remaining 37.5% spent on initializing the multithreaded C++ runtime.
But then again, the truly optimal solution would not involve MS-DOS Player at all. If you followed general video game hacking news in May, you'll probably remember the N64 community putting the concept of statically recompiled game ports on the map. In case you're wondering where this seemingly sudden innovation came from and whether a reverse-engineered decompilation project like ReC98 is obsolete now, I wrote a new FAQ entry about why this hype, although justified, is at least in part misguided. tl;dr: None of this can be meaningfully applied to PC-98 games at the moment.
On the other hand, recompiling our compiler would not only be a reasonable thing to attempt, but exactly the kind of problem that recompilation solves best. A 16-bit command-line tool has none of the pesky hardware factors that drag down the usefulness of recompilations when it comes to game ports, and a recompiled port could run even faster than it would on 32-bit Windows. Sure, it's not as flashy as a recompiled game, but if we got a few generous backers, it would still be a great investment into improving the state of static x86 recompilation by simply having another open-source project in that space. Not to mention that it would be a great foundation for improving Turbo C++ 4.0J's code generation and optimizations, which would allow us to simplify lots of awkward pieces of ZUN code… 🤩
That takes care of building ReC98 on 64-bit platforms, but what about the 32-bit ones we used to support? The previous split of the build process into a Tup-driven 32-bit part and a Makefile-driven 16-bit part sure was awkward and I'm glad it's gone, but it did give you the choice between 1) emulating the 16-bit part or 2) running both parts natively on 32-bit Windows. While Tup's upstream Windows builds are 64-bit-only, it made sense to 📝 compile a custom 32-bit version and thus turn any 32-bit Windows ≥Vista into the perfect build platform for ReC98. Older Windows versions that can't run Tup had to build the 32-bit part using a separately maintained dumb batch script created by tup generate, but again, due to Make being trash, they were fully rebuilding the entire codebase every time anyway.
Driving the entire build via Tup changes all of that. Now, it makes little sense to continue using 32-bit Tup:
We need to DLL-inject into a 64-bit MS-DOS Player. Sure, we could compile a 32-bit build of MS-DOS Player, but why would we? If we look at current marketshares, nobody runs 32-bit Windows anymore, not even by accident. If you run 32-bit Windows in 2024, it's because you know what you're doing and made a conscious choice for the niche use case of natively running DOS programs. Emulating them defeats the whole point of setting up this environment to begin with.
It would make sense if Tup could inject into DOS programs, but it can't.
Also, as we're going to see later, requiring Windows ≥Vista goes in the opposite direction of what we want for a 32-bit build. The earlier the Windows version, the better it is at running native DOS tools.
This means that we could now only support 32-bit Windows via an even larger tup generated batch file. We'd have to move the MS-DOS Player prefix of the respective command lines into an environment variable to make Tup use the same rules for both itself and the batch file, but the result seems to work…
…but it's really slow, especially on Windows 9x. 🐌 If we look back at the theory behind my previous custom build system, we can already tell why: Efficiently building ReC98 requires a completely different approach depending on whether you're running a typical modern multi-core 64-bit system or a vintage single-core 32-bit system. On the former, you'd want to parallelize the slow emulation as much as you can, so you maximize the amount of TCC processes to keep all CPU cores as busy as possible. But on the latter, you'd want the exact opposite – there, the biggest annoyance is the repeated startup and shutdown of the VDM, TCC, and its DOS extender, so you want to continue batching translation units into as few TCC processes as possible.
CMake fans will probably feel vindicated now, thinking "that sounds exactly like you need a meta build system 🤪". Leaving aside the fact that the output vomited by all of CMake's Makefile generators is a disgusting monstrosity that's far removed from addressing any performance concerns, we sure could solve this problem by adding another layer of abstraction. But then, I'd have to rewrite my working Lua script into either C++ or (heaven forbid) Batch, which are the only options we'd have for bootstrapping without adding any further dependencies, and I really wouldn't want to do that. Alternatively, we could fork Tup and modify tup generate to rewrite the low-level build rules that end up in Tup's database.
But why should we go for any of these if the Lua script already describes the build in a high-level declarative way? The most appropriate place for transforming the build rules is the Lua script itself…
… if there wasn't the slight problem of Tup forbidding file writes from Lua. 🥲 Presumably, this limitation exists because there is no way of replicating these writes in a tup generated dumb shell script, and it does make sense from that point of view.
But wait, printing to stdout or stderr works, and we always invoke Tup from a batch file anyway. You can now tell where this is going. Hey, exfiltrating commands from a build script to the build system via standard I/O streams works for Rust's Cargo too!
Just like Cargo, we want to add a sufficiently unique prefix to every line of the generated batch script to distinguish it from Tup's other output. Since Tup only reruns the Lua script – and would therefore print the batch file – if the script changed between the previous and current build run, we only want to overwrite the batch file if we got one or more lines. Getting all of this to work wasn't all too easy; we're once again entering the more awful parts of Batch syntax here, which apparently are so terrible that Wine doesn't even bother to correctly implement parts of it. 😩
Most importantly, we don't really want to redirect any of Tup's standard I/O streams. Redirecting stdout disables console output coloring and the pretty progress bar at the bottom, and looping over stderr instead of stdout in Batch is incredibly awkward. Ideally, we'd run a second Tup process with a sub-command that would just evaluate the Lua script if it changed - and fortunately, tup parse does exactly that. 😌
In the end, the optimally fast and ERRORLEVEL-preserving solution involves two temporary files. But since creating files between two Tup runs causes it to reparse the Lua code, which would print the batch file to the unfiltered stdout, we have to hide these temporary files from Tup by placing them into its .tup/ database directory. 🤪
On a more positive note, programmatically generating batches from single-file TCC rules turned out to be a great idea. Since the Lua code maps command-line flags to arrays of input files, it can also batch across binaries, surpassing my old system in this regard. This works especially well on the debloated and anniversary branches, which replace ZUN's little command-line flag inconsistencies with a single set of good optimization flags that every translation unit is compiled with.
Time to fire up some VMs then… only to see the build failing on Windows 9x with multiple unhelpful Bad command or file name errors. Clearly, the long echo lines that write our response files run up against some length limit in command.com and need to be split into multiple ones. Windows 9x's limit is larger than the 127 characters of DOS, that's for sure, and the exact number should just be one search away…
…except that it's not the 1024 characters recounted in a surviving newsgroup post. Sure, lines are truncated to 1023 bytes and that off-by-one error is no big deal in this context, but that's not the whole story:
: This not unrealistic command line is 137 bytes long and fails on Windows 9x?!
> echo -DA=1 2 3 a/b/c/d/1 a/b/c/d/2 a/b/c/d/3 a/b/c/d/4 a/b/c/d/5 a/b/c/d/6 a/b/c/d/7 a/b/c/d/8 a/b/c/d/9 a/b/c/d/10 a/b/c/d/11 a/b/c/d/12
Bad command or file name
Wait, what, something about / being the SWITCHAR? And not even just that…
: Down to 132 bytes… and 32 "assignments"?
> echo a=0 b=1 c=2 d=3 e=4 f=5 g=6 h=7 i=8 j=9 k=0 l=1 m=2 n=3 o=4 p=5 q=6 r=7 s=8 t=9 u=0 v=1 w=2 x=3 y=4 z=5 a=0 b=1 c=2 d=3 e=4 f=5
Bad command or file name
And what's perhaps the worst example:
: 64 slashes. Works on DOS, works on `cmd.exe`, fails on 9x.
> echo ////////////////////////////////////////////////////////////////
Bad command or file name
My complete set of test cases: 2024-07-09-Win9x-batch-tokenizer-tests.bat
So, time to load command.com into DOSBox-X's debugger and step through some code. 🤷 The earliest NT-based Windows versions were ported to a variety of CPUs and therefore received the then-all-new cmd.exe shell written in C, whereas Windows 9x's command.com was still built on top of the dense hand-written ASM code that originated in the very first DOS versions. Fortunately though, Microsoft open-sourced one of the later DOS versions in April. This made it somewhat easier to cross-reference the disassembly even though the Windows 9x version significantly diverged in the parts we're interested in.
And indeed: After truncating to 1023 bytes and parsing out any redirectors, each line is split into tokens around whitespace and = signs and before every occurrence of the SWITCHAR. These tokens are written into a statically allocated 64-element array, and once the code tries to write the 65th element, we get the Bad command or file name error instead.
#
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
String
echo
-DA
1
2
3
a
/B
/C
/D
/1
a
/B
/C
/D
/2
Switch flag
🚩
🚩
🚩
🚩
🚩
🚩
🚩
🚩
The first few elements of command.com's internal argument array after calling the Windows 9x equivalent of parseline with my initial example string. Note how all the "switches" got capitalized and annotated with a flag, whereas the = sign no longer appears in either string or flag form.
Needless to say, this makes no sense. Both DOS and Windows pass command lines as a single string to newly created processes, and since this tokenization is lossy, command.com will just have to pass the original string anyway. If your shell wants to handle tokenization at a central place, it should happen after it decided that the command matches a builtin that can actually make use of a pointer to the resulting token array – or better yet, as the first call of each builtin's code. Doing it before is patently ridiculous.
I don't know what's worse – the fact that Windows 9x blindly grinds each batch line through this tokenizer, or the fact that no documentation of this behavior has survived on today's Internet, if any even ever existed. The closest thing I found was this page that doesn't exist anymore, and it also just contains a mere hint rather than a clear description of the issue. Even the usual Batch experts who document everything else seem to have a blind spot when it comes to this specific issue. As do emulators: DOSBox and FreeDOS only reimplement the sane DOS versions of command.com, and Wine only reimplements cmd.exe.
Oh well. 71 lines of Lua later, the resulting batch file does in fact work everywhere:
The clear performance winner at 11.15 seconds after the initial tool check, though sadly bottlenecked by strangely long TASM32 startup times. As for TCC though, even this performance is the slowest a recompiled port would be. Modern compiler optimizations are probably going to shave off another second or two, and implementing support for #pragma once into the recompiled code will get us the aforementioned 5% on top.
If you run this on VirtualBox on modern Windows, make sure to disable Hyper-V to avoid the slower snail execution mode. 🐢
Building in Windows XP under Hyper-V exchanges Windows 98's slow TASM32 startup times for slightly slower DOS performance, resulting in a still decent 13.4 seconds.
29.5 seconds?! Surely something is getting emulated here. And this is the best time I randomly got; my initial preview recording took 55 seconds which is closer to DOSBox-X's dynamic core than it is to Windows 9x. Given how poorly 32-bit Windows 10 performs, Microsoft should have probably discontinued 32-bit Windows after 8 already. If any 16-bit program you could possibly want to run is either too slow or likely to exhibit other compatibility issues (📝 Shuusou Gyoku, anyone?), the existence of 32-bit Windows 10 is nothing but a maintenance burden. Especially because Windows 10 simultaneously overhauled the console subsystem, which is bound to cause compatibility issues anyway. It sure did for me back in 2019 when I tried to get my build system to work…
But wait, there's more! The codebase now compiles on all 32-bit Windows systems I've tested, and yields binaries that are equivalent to ZUN's… except on 32-bit Windows 10. 🙄 Suddenly, we're facing the exact same batched compilation bug from my custom build system again, with REIIDEN.EXE being 16 bytes larger than it's supposed to be.
Looks like I have to look into that issue after all, but figuring out the exact cause by debugging TCC would take ages again. Thankfully, trial and error quickly revealed a functioning workaround: Separating translation unit filenames in the response file with two spaces rather than one. Really, I couldn't make this up. This is the most ridiculous workaround for a bug I've encountered in a long time.
The TCC response file generation code for all current decompiled TH04 code, split into multiple echo calls based on the Windows 9x batch tokenizer rules and with double spaces between each parameter for added "safety". Would this also have been the solution for the batched compilation bugs I was experiencing with my old build system in DOSBox? I suddenly was unable to reproduce these bugs, so we won't know for the time being…
Hopefully, you've now got the impression that supporting any kind of 32-bit Windows build is way more of a liability than an asset these days, at least for this specific project. "Real hardware", "motivating a TCC recompilation", and "not dropping previous features" really were the only reasons for putting up with the sheer jank and testing effort I had to go through. And I wouldn't even be surprised if real-hardware developers told me that the first reason doesn't actually hold up because compiling ReC98 on actual PC-98 hardware is slow enough that they'd rather compile it on their main machine and then transfer the binaries over some kind of network connection.
I guess it also made for some mildly interesting blog content, but this was definitely the last time I bothered with such a wide variety of Windows versions without being explicitly funded to do so. If I ever get to recompile TCC, it will be 64-bit only by default as well.
Instead, let's have a tier list of supported build platforms that clearly defines what I am maintaining, with just the most convincing 32-bit Windows version in Tier 1. Initially, that was supposed to be Windows 98 SE due to its superior performance, but that's just unreasonable if key parts of the OS remain undocumented and make no sense. So, XP it is.
*nix fans will probably once again be disappointed to see their preferred OS in Tier 2. But at least, all we'd need for that to move up to Tier 1 is a CI configuration, contributed either via funding me or sending a PR. (Look, even more contribution-ideas!)
Getting rid of the Wine requirement for a fully cross-platform build process wouldn't be too unrealistic either, but would require us to make a few quality decisions, as usual:
Do we run the DOS tools by creating a cross-platform MS-DOS Player fork, or do we statically recompile them?
Do we replace 32-bit Windows TASM with the 16-bit DOS TASM.EXE or TASMX.EXE, which we then either run through our forked MS-DOS Player or recompile? This would further slow down the build and require us to get rid of these nice long non-8.3 filenames… 😕 I'd only recommend this after the looming librarization of ZUN's master.lib fork is completed.
Or do we try migrating to JWasm again? As an open-source assembler that aims for MASM compatibility, it's the closest we can get to TASM, but it's not a drop-in replacement by any means. I already tried in late 2014, but encountered too many issues and quickly abandoned the idea. Maybe it works better now that we have less ASM? In any case, this migration would only get easier the less ASM code we have remaining in the codebase as we get closer to the 100% finalization mark.
Y'know what I think would be the best idea for right now, though? Savoring this new build system and spending an extended amount of time doing actual decompilation or modding for a change.
Now that even full rebuilds are decently fast, let's make use of that productivity boost by doing some urgent and far-reaching code cleanup that touches almost every single C++ source file. The most immediately annoying quirk of this codebase was the silly way each translation unit #included the headers it needed. Many years ago, I measured that repeatedly including the same header did significantly impact Turbo C++ 4.0J's compilation times, regardless of any include guards inside. As a consequence of this discovery, I slightly overreacted and decided to just not use any include guards, ever. After all, this emulated build process is slow enough, and we don't want it to needlessly slow down even more! This way, redundantly including any file that adds more than just a few #define macros won't even compile, throwing lots of Multiple definition errors.
Consequently, the headers themselves #included almost nothing. Starting a new translation unit therefore always involved figuring and spelling out the transitive dependencies of the headers the new unit actually wants to use, in a short trial-and-error process. While not too bad by itself, this was bound to become quite counterproductive once we get closer to porting these games: If some inlined function in a header needed access to, let's say, PC-98-specific I/O ports as an implementation detail, the header would have externalized this dependency to the top-level translation unit, which in turn made that that unit appear to contain PC-98-native code even if the unit's code itself was perfectly portable.
But once we start making some of these implicit transitive dependencies optional, it all stops being justifiable. Sometimes, a.hpp declared things that required declarations from b.hpp but these things are used so rarely that it didn't justify adding #include "b.hpp" to all translation units that #include "a.hpp". So how about conditionally declaring these things based on previously #included headers?
#if (defined(SUBPIXEL_HPP) && defined(PLANAR_H))
// Sets the [tile_ring] tile at (x, y) to the given VRAM offset.
void tile_ring_set_vo(subpixel_t x, subpixel_t y, vram_offset_t image_vo);
#endif
You can maybe do this in a project that consistently sorts the #include lists in every translation unit… err, no, don't do this, ever, it's awful. Just separate that declaration out into another header.
Now that we've measured that the sane alternative of include guards comes with a performance cost of just 5% and we've further reduced its effective impact by parallelizing the build, it's worth it to take that cost in exchange for a tidy codebase without such surprises. From now on, every header file will #include its own dependencies and be a valid translation unit that must compile on its own without errors. In turn, this allows us to remove at least 1,000 #include of transitive dependencies from .cpp files. 🗑️
However, that 5% number was only measured after I reduced these redundant #includes to their absolute minimum. So it still makes sense to only add include guards where they are absolutely necessary – i.e., transitively dependent headers included from more than one other file – and continue to (ab)use the Multiple definition compiler errors as a way of communicating "you're probably #including too many headers, try removing a few". Certainly a less annoying error than Undefined symbol.
Since all of this went way over the 7-push mark, we've got some small bits of RE and PI work to round it all out. The .REC loader in TH04 and TH05 is completely unremarkable, but I've got at least a bit to say about TH02's High Score menu. I already decompiled MAINE.EXE's post-Staff Roll variant in 2015, so we were only missing the almost identical MAIN.EXE variant shown after a Game Over or when quitting out of the game. The two variants are similar enough that it mostly needed just a small bit of work to bring my old 2015 code up to current standards, and allowed me to quickly push TH02 over the 40% RE mark.
Functionally, the two variants only differ in two assignments, but ZUN once again chose to copy-paste the entire code to handle them. This was one of ZUN's better copy-pasting jobs though – and honestly, I can't even imagine how you would mess up a menu that's entirely rendered on the PC-98's text RAM. It almost makes you wonder whether ZUN actually used the same #if ENDING preprocessor branching that my decompilation uses… until the visual inconsistencies in the alignment of the place numbers and the and labels clearly give it away as copy-pasted:
Next up: Starting the big Seihou summer! Fortunately, waiting two more months was worth it: In mid-June, Microsoft released a preview version of Visual Studio that, in response to my bug report, finally, finally makes C++ standard library modules fully usable. Let's clean up that codebase for real, and put this game into a window.
TH03 gameplay! 📝 It's been over two years. People have been investing some decent money with the intention of eventually getting netplay, so let's cover some more foundations around player movement… and quickly notice that there's almost no overlap between gameplay RE and netplay preparations? That makes for a fitting opportunity to think about what TH03 netplay would look like:
You'd want UDP rather than TCP for both its low latency and its NAT hole-punching ability
However, raw UDP does not guarantee that the packets arrive in order, or that they even arrive at all
WebRTC implements these reliability guarantees on top of UDP in a modern package, providing the best of both worlds
NAT traversal via public or self-hosted STUN/TURN servers is built into the connection establishment protocol and APIs, so you don't even have to understand the underlying issue
I'm not too deep into networking to argue here, and it clearly works for Ju.N.Owen. If we do explore other options, it would mainly be because I can't easily get something as modern as WebRTC to natively run on Windows 9x or DOS, if we decide to go for that route.
Matchmaking: I like Ju.N.Owen's initial way of copy-pasting signaling codes into chat clients to establish a peer-to-peer connection without a dedicated matchmaking server. progre eventually implemented rooms on the AWS cloud, but signaling codes are still used for spectating and the Pure P2P mode. We'll probably copy the same evolution, with a slight preference for Pure P2P – if only because you would have to check a GDPR consent box before I can put the combination of your room name and IP address into a database. Server costs shouldn't be an issue at the scale I expect this to have.
Rollback: In emulators, rollback netcode can be and has been implemented by keeping savestates of the last few frames together with the local player's inputs and then replaying the emulation with updated inputs of the remote player if a prediction turned out to be incorrect. This technique is a great fit for TH03 for two reasons:
All game state is contained within a relatively small bit of memory. The only heap allocations done in MAIN.EXE are the 📝 .MRS images for gauge attack portraits and bomb backgrounds, and the enemy scripts and formations, both of which remain constant throughout a round. All other state is statically allocated, which can reduce per-frame snapshots from the naive 640 KiB of conventional DOS memory to just the 37 KiB of MAIN.EXE's data segment. And that's the upper bound – this number is only going to go down as we move towards 100% PI, figure out how TH03 uses all its static data, and get to consolidate all mutated data into an even smaller block of memory.
For input prediction, we could even let the game's existing AI play the remote player until the actual inputs come in, guaranteeing perfect play until the remote inputs prove otherwise. Then again… probably only while the remote player is not moving, because the chance for a human to replicate the AI's infamous erratic dodging is fairly low.
The only issue with rollback in specifically a PC-98 emulator is its implications for performance. Rendering is way more computationally expensive on PC-98 than it is on consoles with hardware sprites, involving lots of memory writes to the disjointed 4 bitplane segments that make up the 128 KB framebuffer, and equally as many reads and bitshift operations on sprite data. TH03 lessens the impact somewhat thanks to most of its rendering being EGC-accelerated and thus running inside the emulator as optimized native code, but we'd still be emulating all the x86 code surrounding the EGC accesses – from the emulator's point of view, it looks no different than game logic. Let's take my aging i5 system for example:
With the Screen → No wait option, Neko Project 21/W can emulate TH03 gameplay at 260 FPS, or 4.6× its regular speed.
This leaves room for each frame to contain 3.6 frames of rollback in addition to the frame that's supposed to be displayed,
which results in a maximum safe network latency of ≈63 ms, or a ping of ≈126 ms. According to this site, that's enough for a smooth connection from Germany to any other place in Europe and even out to the US Midwest. At this ping, my system could still run the game without slowdown even if every single frame required a rollback, which is highly unlikely.
Any higher ping, however, could occasionally lead to a rollback queue that's too large for my system to process within a single frame at the intended 56.4 FPS rate. As a result, me playing anyone in the western US is highly likely to involve at least occasional slowdowns. Delaying inputs on purpose is the usual workaround, but isn't Touhou that kind of game series where people use vpatch to get rid of even the default input delay in the Windows games?
So we'd ideally want to put TH03 into an update-only mode that skips all rendering calls during re-simulation of rolled-back frames. Ironically, this means that netplay-focused RE would actually focus on the game's rendering code and ensure that it doesn't mutate any statically allocated data, allowing it to be freely skipped without affecting the game. Imagine palette-based flashing animations that are implemented by gradually mutating statically allocated values – these would cause wrong colors for the rest of the game if the animation doesn't run on every frame.
Implementing all of this into TH03 can be done in one, a few, or all of the following 6 ways, depending on what the backers prefer. Sorted from the most generic to the most specialized solution (and, coincidentally, from least to most total effort required):
Generic PC-98 netcode for one or more emulators
This is the most basic and puristic variant that implements generic netplay for PC-98 games in general by effectively providing remote control of the emulated keyboard and joypad. The emulator will be unaware of the game, and the game will be unaware of being netplayed, which makes this solution particularly interesting for the non-Touhou PC-98 scene, or competitive players who absolutely insist on using ZUN's original binaries and won't trust any of my modded game builds.
Applied to TH03, this means that players would select the regular hot-seat 1P vs 2P mode and then initiate a match through a new menu in the emulator UI. The same UI must then provide an option to manually remap incoming key and button presses to the 2P controls (newly introducing remapping to the emulator if necessary), as well as blocking any non-2P keys. The host then sends an initial savestate to the guest to ensure an identical starting state, and starts synchronizing and rolling back inputs at VSync boundaries.
This generic nature means that we don't get to include any of the TH03-specific rollback optimizations mentioned above, leading to the highest CPU and memory requirements out of all the variants. It sure is the easiest to implement though, as we get to freely use modern C++ WebRTC libraries that are designed to work with the network stack of the underlying OS.
I can try to build this netcode as a generic library that can work with any PC-98 emulator, but it would ultimately be up to the respective upstream developers to integrate it into official releases. Therefore, expect this variant to require separate funding and custom builds for each individual emulator codebase that we'd like to support.
Emulator-level netcode with optional game integration
Takes the generic netcode developed in 1) and adds the possibility for the game to control it via a special interrupt API. This enables several improvements:
Online matches could be initiated through new options in TH03's main menu rather than the emulator's UI.
The game could communicate the memory region that should be backed up every frame, cutting down memory usage as described above.
The exchanged input data could use the game's internal format instead of keyboard or joypad inputs. This removes the need for key remapping at the emulator level and naturally prevents the inherent issue of remote control where players could mess with each other's controls.
The game could be aware of the rollbacks, allowing it to jump over its rendering code while processing the queue of remote inputs and thus gain some performance as explained above.
The game could add synchronization points that block gameplay until both players have reached them, preventing the rollback queue from growing infinitely. This solves the issue of 1) not having any inherent way of working around desyncs and the resulting growth of the rollback queue. As an example, if one of the two emulators in 1) took, say, 2 seconds longer to load the game due to a random CPU spike caused by some bloatware on their system, the two players would be out of sync by 2 seconds for the rest of the session, forcing the faster system to render 113 frames every time an input prediction turned out to be incorrect.
Good places for synchronization points include the beginning of each round, the WARNING!! You are forced to evade / Your life is in peril popups that pause the game for a few frames anyway, and whenever the game is paused via the ESC key.
During such pauses, the game could then also block the resuming ESC key of the player who didn't pause the game.
Edit (2024-04-30): Emulated serial port communicating over named pipes with a standalone netplay tool
This approach would take the netcode developed in 2) out of the emulator and into a separate application running on the (modern) host OS, just like Ju.N.Owen or Adonis. The previous interrupt API would then be turned into binary protocol communicated over the PC-98's serial port, while the rollback snapshots would be stored inside the emulated PC-98 in EMS or XMS/Protected Mode memory. Netplay data would then move through these stages:
🖥️ PC-98 game logic ⇄ Serial port ⇄ Emulator ⇄ Named pipe ⇄ Netcode logic ⇄ WebRTC Data Channel ⇄ Internet 🛜
All green steps run natively on the host OS.
Sending serial port data over named pipes is only a semi-common feature in PC-98 emulators, and would currently restrict netplay to Neko Project 21/W and NP2kai on Windows. This is a pretty clean and generally useful feature to have in an emulator though, and emulator maintainers will be much more likely to include this than the custom netplay code I proposed in 1) and 2). DOSBox-X has an open issue that we could help implement, and the NP2kai Linux port would probably also appreciate a mkfifo(3) implementation.
This could even work with emulators that only implement PC-98 serial ports in terms of, well, native Windows serial ports. This group currently includes Neko Project II fmgen, SL9821, T98-Next, and rare bundles of Anex86 that replace MIDI support with COM port emulation. These would require separately installed and configured virtual serial port software in place of the named pipe connection, as well as support for actual serial ports in the netplay tool itself. In fact, this is the only way that die-hard Anex86 and T98-Next fans could enjoy any kind of netplay on these two ancient emulators.
If it works though, it's the optimal solution for the emulated use case if we don't want to fork the emulator. From the point of view of the PC-98, the serial port is the cheapest way to send a couple of bytes to some external thing, and named pipes are one of many native ways for two Windows/Linux applications to efficiently communicate.
The only slight drawback of this approach is the expected high DOS memory requirement for rollback. Unless we find a way to really compress game state snapshots to just a few KB, this approach will require a more modern DOS setup with EMS/XMS support instead of the pre-installed MS-DOS 3.30C on a certain widely circulated .HDI copy. But apart from that, all you'd need to do is run the separate netplay tool, pick the same pipe name in both the tool and the emulator, and you're good to go.
It could even work for real hardware, but would require the PC-98 to be linked to the separately running modern system via a null modem cable.
Native PC-98 Windows 9x netcode (only for real PC-98 hardware equipped with an Ethernet card)
Equivalent in features to 2), but pulls the netcode into the PC-98 system itself. The tool developed in 3) would then as a separate 32-bit or 16-bit Windows application that somehow communicates with the game running in a DOS window. The handful of real-hardware owners who have actually equipped their PC-98 with a network card such as the LGY-98 would then no longer require the modern PC from 3) as a bridge in the middle.
This specific card also happens to be low-level-emulated by the 21/W fork of Neko Project. However, it makes little sense to use this technique in an emulator when compared to 3), as NP21/W requires a separately installed and configured TAP driver to actually be able to access your native Windows Internet connection. While the setup is well-documented and I did manage to get a working Internet connection inside an emulated Windows 95, it's definitely not foolproof. Not to mention DOSBox-X, which currently emulates the apparently hardware-compatible NE2000 card, but disables its emulation in PC-98 mode, most likely because its I/O ports clash with the typical peripherals of a PC-98 system.
And that's not the end of the drawbacks:
Netplay would depend on the PC-98 versions of Windows 9x and its full network stack, nothing of which is required for the game itself.
Porting libdatachannel (and especially the required transport encryption) to Windows 95 will probably involve a bit of effort as well.
As would actually finding a way to access V86 mode memory from a 32-bit or 16-bit Windows process, particularly due to how isolated DOS processes are from the rest of the system and even each other. A quick investigation revealed three potential approaches:
A 32-bit process could read the memory out of the address space of the console host process (WINOA32.MOD). There seems to be no way of locating the specific base address of a DOS process, but you could always do a brute-force search through the memory map.
If started before Windows, TSRs will share their resident memory with both DOS and Win16 processes. The segment pointer would then be retrieved through a typical interrupt API.
Writing a VxD driver 😩
Correctly setting up TH03 to run within Windows 95 to begin with can be rather tricky. The GDC clock speed check needs to be either patched out or overridden using mode-setting tools, Windows needs to be blocked from accessing the FM chip, and even then, MAIN.EXE might still immediately crash during the first frame and leave all of VRAM corrupted:
This is probably a bug in the latest ver0.86 rev92β3 version of Neko Project 21/W; I got it to work fine on real hardware. 📝 StormySpace did run on the same emulated Windows 95 system without any issues, though. Regardless, it's still worth mentioning as a symbol of everything that can go wrong.
A matchmaking server would be much more of a requirement than in any of the emulator variants. Players are unlikely to run their favorite chat client on the same PC-98 system, and the signaling codes are way too unwieldy to type them in manually. (Then again, IRC is always an option, and the people who would fund this variant are probably the exact same people who are already running IRC clients on their PC-98.)
Native PC-98 DOS netcode (only for real PC-98 hardware equipped with an Ethernet card)
Conceptually the same as 4), but going yet another level deeper, replacing the Windows 9x network stack with a DOS-based one. This might look even more intimidating and error-prone, but after I got pingand even Telnet working, I was pleasantly surprised at how much simpler it is when compared to the Windows variant. The whole stack consists of just one LGY-98 hardware information tool, a LGY-98 packet driver TSR, and a TSR that implements TCP/IP/UDP/DNS/ICMP and is configured with a plaintext file. I don't have any deep experience with these protocols, so I was quite surprised that you can implement all of them in a single 40 KiB binary. Installed as TSRs, the entire stack takes up an acceptable 82 KiB of conventional memory, leaving more than enough space for the game itself. And since both of the TSRs are open-source, we can even legally bundle them with the future modified game binaries.
The matchmaking issue from the Windows 9x approach remains though, along with the following issues:
Porting libdatachannel and the required transport encryption to the TEEN stack seems even more time-consuming than a Windows 95 port.
The TEEN stack has no UI for specifying the system's or gateway's IP addresses outside of its plaintext configuration file. This provides a nice opportunity for adding a new Internet settings menu with great error feedback to the game itself. Great for UX, but it's another thing I'd have to write.
As always, this is the premium option. If the entire game already runs as a standalone executable on a modern system, we can just put all the netcode into the same binary and have the most seamless integration possible.
That leaves us with these prerequisites:
1), by definition, needs nothing from ReC98, and I could theoretically start implementing it right now. If you're interested in funding it, just tell me via the usual Twitter or Discord channels.
2) through 5) require at least 100% RE of TH03's OP.EXE to facilitate the new menu code. Reverse-engineering all rendering-related code in MAIN.EXE would be nice for performance, but we don't strictly need all of it before we start. Re-simulated frames can just skip over the few pieces of rendering code we do know, and we can gradually increase the skipped area of code in future pushes.
100% PI won't be a requirement either, as I expect the MAIN.EXE part of the interfacing netcode layer to be thin enough that it can easily fit within the original game's code layout.
6), obviously, requires all of TH03 to be RE'd, decompiled, cleaned up, and ported to modern systems. Currently, TH03 appears to be the second-easiest game to port behind TH02:
Although TH03 already has more needlessly micro-optimized ASM code than TH02 and there's even more to come, it still appears to have way less than TH04 or TH05.
Its game logic and rendering code seem to be somewhat neatly separated from each other, unlike TH01 which deeply intertwines them.
Its graphics seem free of obvious bugs, unlike – again — the flicker-fest that is TH01.
But still, it's the game with the least amount of RE%. Decompilation might get easier once I've worked myself up to the higher levels of game code, and even more so if we're lucky and all of the 9 characters are coded in a similar way, but I can't promise anything at this point.
Once we've reached any of these prerequisites, I'll set up a separate campaign funding method that runs parallel to the cap. As netplay is one of those big features where incremental progress makes little sense and we can expect wide community support for the idea, I'll go for a more classic crowdfunding model with a fixed goal for the minimum feature set and stretch goals for optional quality-of-life features. Since I've still got two other big projects waiting to be finished, I'd like to at least complete the Shuusou Gyoku Linux port before I start working on TH03 netplay, even if we manage to hit any of the funding goals before that.
For the first time in a long while, the actual content of this push can be listed fairly quickly. I've now RE'd:
conversions from playfield-relative coordinates to screen coordinates and back (a first in PC-98 Touhou; even TH02 uses screen space for every coordinate I've seen so far),
the low-level code that moves the player entity across the screen,
a copy of the per-round frame counter that, for some reason, resets to 0 at the start of the Win/Lose animation, resetting a bunch of animations with it,
a global hitbox with one variable that sometimes stores the center of an entity, and sometimes its top-left corner,
and the 48×48 hit circles from EN2.PI.
It's also the third TH03 gameplay push in a row that features inappropriate ASM code in places that really, really didn't need any. As usual, the code is worse than what Turbo C++ 4.0J would generate for idiomatic C code, and the surrounding code remains full of untapped and quick optimization opportunities anyway. This time, the biggest joke is the sprite offset calculation in the hit circle rendering code:
A multiplication with 6 would have compiled into a single IMUL instruction. This compiles into 4 MOVs, one IMUL (with 2), and two ADDs. This surely must have been left in on purpose for us to laugh about it one day?
But while we've all come to expect the usual share of ZUN bloat by now, this is also the first push without either a ZUN bug or a landmine since I started using these terms! 🎉 It does contain a single ZUN quirk though, which can also be found in the hit circles. This animation comes in two types with different caps: 12 animation slots across both playfields for the enemy circles shown in alternating bright/dark yellow colors, whereas the white animation for the player characters has a cap of… 1? P2 takes precedence over P1 because its update code always runs last, which explains what happens when both players get hit within the 16 frames of the animation:
If they both get hit on the exact same frame, the animation for P1 never plays, as P2 takes precedence.
If the other player gets hit within 16 frames of an active white circle animation, the animation is reinitialized for the other player as there's only a single slot to hold it. Is this supposed to telegraph that the other player got hit without them having to look over to the other playfield? After all, they're drawn on top of most other entities, but below the player.
SPRITE16 uses the PC-98's EGC to draw these single-color sprites. If the EGC is already set up, it can be set into a GRCG-equivalent RMW mode using the pattern/read plane register (0x4A2) and foreground color register (0x4A6), together with setting the mode register (0x4A4) to 0x0CAC. Unlike the typical blitting operations that involve its 16-dot pattern register, the EGC even supports 8- or 32-bit writes in this mode, just like the GRCG. 📝 As expected for EGC features beyond the most ordinary ones though, T98-Next simply sets every written pixel to black on a 32-bit write. Comparing the actual performance of such writes to the GRCG would be 📝 yet another interesting question to benchmark.
Next up: I think it's time for ReC98's build system to reach its final form.
For almost 5 years, I've been using an unreleased sane build system on a parallel private branch that was just missing some final polish and bugfixes. Meanwhile, the public repo is still using the project's initial Makefile that, 📝 as typical for Makefiles, is so unreliable that BUILD16B.BAT force-rebuilds everything by default anyway. While my build system has scaled decently over the years, something even better happened in the meantime: MS-DOS Player, a DOS emulator exclusively meant for seamless integration of CLI programs into the Windows console, has been forked and enhanced enough to finally run Turbo C++ 4.0J at an acceptable speed. So let's remove DOSBox from the equation, merge the 32-bit and 16-bit build steps into a single 32-bit one, set all of this up in a user-friendly way, and maybe squeeze even more performance out of MS-DOS Player specifically for this use case.
More than three months without any reverse-engineering progress! It's been
way too long. Coincidentally, we're at least back with a surprising 1.25% of
overall RE, achieved within just 3 pushes. The ending script system is not
only more or less the same in TH04 and TH05, but actually originated in
TH03, where it's also used for the cutscenes before stages 8 and 9. This
means that it was one of the final pieces of code shared between three of
the four remaining games, which I got to decompile at roughly 3× the usual
speed, or ⅓ of the price.
The only other bargains of this nature remain in OP.EXE. The
Music Room is largely equivalent in all three remaining games as well, and
the sound device selection, ZUN Soft logo screens, and main/option menus are
the same in TH04 and TH05. A lot of that code is in the "technically RE'd
but not yet decompiled" ASM form though, so it would shift Finalized% more
significantly than RE%. Therefore, make sure to order the new
Finalization option rather than Reverse-engineering if you
want to make number go up.
So, cutscenes. On the surface, the .TXT files look simple enough: You
directly write the text that should appear on the screen into the file
without any special markup, and add commands to define visuals, music, and
other effects at any place within the script. Let's start with the basics of
how text is rendered, which are the same in all three games:
First off, the text area has a size of 480×64 pixels. This means that it
does not correspond to the tiled area painted into TH05's
EDBK?.PI images:
The yellow area is designated for character names.
Since the font weight can be customized, all text is rendered to VRAM.
This also includes gaiji, despite them ignoring the font weight
setting.
The system supports automatic line breaks on a per-glyph basis, which
move the text cursor to the beginning of the red text area. This might seem like a piece of long-forgotten
ancient wisdom at first, considering the absence of automatic line breaks in
Windows Touhou. However, ZUN probably implemented it more out of pure
necessity: Text in VRAM needs to be unblitted when starting a new box, which
is way more straightforward and performant if you only need to worry
about a fixed area.
The system also automatically starts a new (key press-separated) text
box after the end of the 4th line. However, the text cursor is
also unconditionally moved to the top-left corner of the yellow name
area when this happens, which is almost certainly not what you expect, given
that automatic line breaks stay within the red area. A script author might
as well add the necessary text box change commands manually, if you're
forced to anticipate the automatic ones anyway…
Due to ZUN forgetting an unblitting call during the TH05 refactoring of the
box background buffer, this feature is even completely broken in that game,
as any new text will simply be blitted on top of the old one:
Wait, why are we already talking about game-specific differences after
all? Also, note how the ⏎ animation appears one line below where you'd
expect it.
Overall, the system is geared toward exclusively full-width text. As
exemplified by the 2014 static English patches and the screenshots in this
blog post, half-width text is possible, but comes with a lot of
asterisks attached:
Each loop of the script interpreter starts by looking at the next
byte to distinguish commands from text. However, this step also skips
over every ASCII space and control character, i.e., every byte
≤ 32. If you only intend to display full-width glyphs anyway, this
sort of makes sense: You gain complete freedom when it comes to the
physical layout of these script files, and it especially allows commands
to be freely separated with spaces and line breaks for improved
readability. Still, enforcing commands to be separated exclusively by
line breaks might have been even better for readability, and would have
freed up ASCII spaces for regular text…
Non-command text is blindly processed and rendered two bytes at a
time. The rendering function interprets these bytes as a Shift-JIS
string, so you can use half-width characters here. While the
second byte can even be an ASCII 0x20 space due to the
parser's blindness, all half-width characters must still occur in pairs
that can't be interrupted by commands:
As a workaround for at least the ASCII space issue, you can replace
them with any of the unassigned
Shift-JIS lead bytes – 0x80, 0xA0, or
anything between 0xF0 and 0xFF inclusive.
That's what you see in all screenshots of this post that display
half-width spaces.
Finally, did you know that you can hold ESC to fast-forward
through these cutscenes, which skips most frame delays and reduces the rest?
Due to the blocking nature of all commands, the ESC key state is
only updated between commands or 2-byte text groups though, so it can't
interrupt an ongoing delay.
Superficially, the list of game-specific differences doesn't look too long,
and can be summarized in a rather short table:
It's when you get into the implementation that the combined three systems
reveal themselves as a giant mess, with more like 56 differences between the
games. Every single new weird line of code opened up
another can of worms, which ultimately made all of this end up with 24
pieces of bloat and 14 bugs. The worst of these should be quite interesting
for the general PC-98 homebrew developers among my audience:
The final official 0.23 release of master.lib has a bug in
graph_gaiji_put*(). To calculate the JIS X 0208 code point for
a gaiji, it is enough to ADD 5680h onto the gaiji ID. However,
these functions accidentally use ADC instead, which incorrectly
adds the x86 carry flag on top, causing weird off-by-one errors based on the
previous program state. ZUN did fix this bug directly inside master.lib for
TH04 and TH05, but still needed to work around it in TH03 by subtracting 1
from the intended gaiji ID. Anyone up for maintaining a bug-fixed master.lib
repository?
The worst piece of bloat comes from TH03 and TH04 needlessly
switching the visibility of VRAM pages while blitting a new 320×200 picture.
This makes it much harder to understand the code, as the mere existence of
these page switches is enough to suggest a more complex interplay between
the two VRAM pages which doesn't actually exist. Outside this visibility
switch, page 0 is always supposed to be shown, and page 1 is always used
for temporarily storing pixels that are later crossfaded onto page 0. This
is also the only reason why TH03 has to render text and gaiji onto both VRAM
pages to begin with… and because TH04 doesn't, changing the picture in the
middle of a string of text is technically bugged in that game, even though
you only get to temporarily see the new text on very underclocked PC-98
systems.
These performance implications made me wonder why cutscenes even bother with
writing to the second VRAM page anyway, before copying each crossfade step
to the visible one.
📝 We learned in June how costly EGC-"accelerated" inter-page copies are;
shouldn't it be faster to just blit the image once rather than twice?
Well, master.lib decodes .PI images into a packed-pixel format, and
unpacking such a representation into bitplanes on the fly is just about the
worst way of blitting you could possibly imagine on a PC-98. EGC inter-page
copies are already fairly disappointing at 42 cycles for every 16 pixels, if
we look at the i486 and ignore VRAM latencies. But under the same
conditions, packed-pixel unpacking comes in at 81 cycles for every 8
pixels, or almost 4× slower. On lower-end systems, that can easily sum up to
more than one frame for a 320×200 image. While I'd argue that the resulting
tearing could have been an acceptable part of the transition between two
images, it's understandable why you'd want to avoid it in favor of the
pure effect on a slower framerate.
Really makes me wonder why master.lib didn't just directly decode .PI images
into bitplanes. The performance impact on load times should have been
negligible? It's such a good format for
the often dithered 16-color artwork you typically see on PC-98, and
deserves better than master.lib's implementation which is both slow to
decode and slow to blit.
That brings us to the individual script commands… and yes, I'm going to
document every single one of them. Some of their interactions and edge cases
are not clear at all from just looking at the code.
Almost all commands are preceded by… well, a 0x5C lead byte.
Which raises the question of whether we should
document it as an ASCII-encoded \ backslash, or a Shift-JIS-encoded
¥ yen sign. From a gaijin perspective, it seems obvious that it's a
backslash, as it's consistently displayed as one in most of the editors you
would actually use nowadays. But interestingly, iconv
-f shift-jis -t utf-8 does convert any 0x5C
lead bytes to actual ¥ U+00A5 YEN SIGN code points
.
Ultimately, the distinction comes down to the font. There are fonts
that still render 0x5C as ¥, but mainly do so out
of an obvious concern about backward compatibility to JIS X 0201, where this
mapping originated. Unsurprisingly, this group includes MS Gothic/Mincho,
the old Japanese fonts from Windows 3.1, but even Meiryo and Yu
Gothic/Mincho, Microsoft's modern Japanese fonts. Meanwhile, pretty much
every other modern font, and freely licensed ones in particular, render this
code point as \, even if you set your editor to Shift-JIS. And
while ZUN most definitely saw it as a ¥, documenting this code
point as \ is less ambiguous in the long run. It can only
possibly correspond to one specific code point in either Shift-JIS or UTF-8,
and will remain correct even if we later mod the cutscene system to support
full-blown Unicode.
Now we've only got to clarify the parameter syntax, and then we can look at
the big table of commands:
Numeric parameters are read as sequences of up to 3 ASCII digits. This
limits them to a range from 0 to 999 inclusive, with 000 and
0 being equivalent. Because there's no further sentinel
character, any further digit from the 4th one onwards is
interpreted as regular text.
Filename parameters must be terminated with a space or newline and are
limited to 12 characters, which translates to 8.3 basenames without any
directory component. Any further characters are ignored and displayed as
text as well.
Each .PI image can contain up to four 320×200 pictures ("quarters") for
the cutscene picture area. In the script commands, they are numbered like
this:
0
1
2
3
\@
Clears both VRAM pages by filling them with VRAM color 0. 🐞
In TH03 and TH04, this command does not update the internal text area
background used for unblitting. This bug effectively restricts usage of
this command to either the beginning of a script (before the first
background image is shown) or its end (after no more new text boxes are
started). See the image below for an
example of using it anywhere else.
\b2
Sets the font weight to a value between 0 (raw font ROM glyphs) to 3
(very thicc). Specifying any other value has no effect.
🐞 In TH04 and TH05, \b3 leads to glitched pixels when
rendering half-width glyphs due to a bug in the newly micro-optimized
ASM version of
📝 graph_putsa_fx(); see the image below for an example.
In these games, the parameter also directly corresponds to the
graph_putsa_fx() effect function, removing the sanity check
that was present in TH03. In exchange, you can also access the four
dissolve masks for the bold font (\b2) by specifying a
parameter between 4 (fewest pixels) to 7 (most
pixels). Demo video below.
\c15
Changes the text color to VRAM color 15.
\c=字,15
Adds a color map entry: If 字 is the first code point
inside the name area on a new line, the text color is automatically set
to 15. Up to 8 such entries can be registered
before overflowing the statically allocated buffer.
🐞 The comma is assumed to be present even if the color parameter is omitted.
\e0
Plays the sound effect with the given ID.
\f
(no-op)
\fi1
\fo1
Calls master.lib's palette_black_in() or
palette_black_out() to play a hardware palette fade
animation from or to black, spending roughly 1 frame on each of the 16 fade steps.
\fm1
Fades out BGM volume via PMD's AH=02h interrupt call,
in a non-blocking way. The fade speed can range from 1 (slowest) to 127 (fastest).
Values from 128 to 255 technically correspond to
AH=02h's fade-in feature, which can't be used from cutscene
scripts because it requires BGM volume to first be lowered via
AH=19h, and there is no command to do that.
\g8
Plays a blocking 8-frame screen shake
animation.
\ga0
Shows the gaiji with the given ID from 0 to 255
at the current cursor position. Even in TH03, gaiji always ignore the
text delay interval configured with \v.
@3
TH05's replacement for the \ga command from TH03 and
TH04. The default ID of 3 corresponds to the
gaiji. Not to be confused with \@, which starts with a backslash,
unlike this command.
@h
Shows the gaiji.
@t
Shows the gaiji.
@!
Shows the gaiji.
@?
Shows the gaiji.
@!!
Shows the gaiji.
@!?
Shows the gaiji.
\k0
Waits 0 frames (0 = forever) for an advance key to be pressed before
continuing script execution. Before waiting, TH05 crossfades in any new
text that was previously rendered to the invisible VRAM page…
🐞 …but TH04 doesn't, leaving the text invisible during the wait time.
As a workaround, \vp1 can be
used before \k to immediately display that text without a
fade-in animation.
\m$
Stops the currently playing BGM.
\m*
Restarts playback of the currently loaded BGM from the
beginning.
\m,filename
Stops the currently playing BGM, loads a new one from the given
file, and starts playback.
\n
Starts a new line at the leftmost X coordinate of the box, i.e., the
start of the name area. This is how scripts can "change" the name of the
currently speaking character, or use the entire 480×64 pixels without
being restricted to the non-name area.
Note that automatic line breaks already move the cursor into a new line.
Using this command at the "end" of a line with the maximum number of 30
full-width glyphs would therefore start a second new line and leave the
previously started line empty.
If this command moved the cursor into the 5th line of a box,
\s is executed afterward, with
any of \n's parameters passed to \s.
\p
(no-op)
\p-
Deallocates the loaded .PI image.
\p,filename
Loads the .PI image with the given file into the single .PI slot
available to cutscenes. TH04 and TH05 automatically deallocate any
previous image, 🐞 TH03 would leak memory without a manual prior call to
\p-.
\pp
Sets the hardware palette to the one of the loaded .PI image.
\p@
Sets the loaded .PI image as the full-screen 640×400 background
image and overwrites both VRAM pages with its pixels, retaining the
current hardware palette.
\p=
Runs \pp followed by \p@.
\s0
\s-
Ends a text box and starts a new one. Fades in any text rendered to
the invisible VRAM page, then waits 0 frames
(0 = forever) for an advance key to be
pressed. Afterward, the new text box is started with the cursor moved to
the top-left corner of the name area. \s- skips the wait time and starts the new box
immediately.
\t100
Sets palette brightness via master.lib's
palette_settone() to any value from 0 (fully black) to 200
(fully white). 100 corresponds to the palette's original colors.
Preceded by a 1-frame delay unless ESC is held.
\v1
Sets the number of frames to wait between every 2 bytes of rendered
text.
Sets the number of frames to spend on each of the 4 fade
steps when crossfading between old and new text. The game-specific
default value is also used before the first use of this command.
\v2
\vp0
Shows VRAM page 0. Completely useless in
TH03 (this game always synchronizes both VRAM pages at a command
boundary), only of dubious use in TH04 (for working around a bug in \k), and the games always return to
their intended shown page before every blitting operation anyway. A
debloated mod of this game would just remove this command, as it exposes
an implementation detail that script authors should not need to worry
about. None of the original scripts use it anyway.
\w64
\w and \wk wait for the given number
of frames
\wm and \wmk wait until PMD has played
back the current BGM for the total number of measures, including
loops, given in the first parameter, and fall back on calling
\w and \wk with the second parameter as
the frame number if BGM is disabled.
🐞 Neither PMD nor MMD reset the internal measure when stopping
playback. If no BGM is playing and the previous BGM hasn't been
played back for at least the given number of measures, this command
will deadlock.
Since both TH04 and TH05 fade in any new text from the invisible VRAM
page, these commands can be used to simulate TH03's typing effect in
those games. Demo video below.
Contrary to \k and \s, specifying 0 frames would
simply remove any frame delay instead of waiting forever.
The TH03-exclusive k variants allow the delay to be
interrupted if ⏎ Return or Shot are held down.
TH04 and TH05 recognize the k as well, but removed its
functionality.
All of these commands have no effect if ESC is held.
\wm64,64
\wk64
\wmk64,64
\wi1
\wo1
Calls master.lib's palette_white_in() or
palette_white_out() to play a hardware palette fade
animation from or to white, spending roughly 1 frame on each of the 16 fade steps.
\=4
Immediately displays the given quarter of the loaded .PI image in
the picture area, with no fade effect. Any value ≥ 4 resets the picture area to black.
\==4,1
Crossfades the picture area between its current content and quarter
#4 of the loaded .PI image, spending 1 frame on each of the 4 fade steps unless
ESC is held. Any value ≥ 4 is
replaced with quarter #0.
\$
Stops script execution. Must be called at the end of each file;
otherwise, execution continues into whatever lies after the script
buffer in memory.
TH05 automatically deallocates the loaded .PI image, TH03 and TH04
require a separate manual call to \p- to not leak its memory.
Bold values signify the default if the parameter
is omitted; \c is therefore
equivalent to \c15.
The \@ bug. Yes, the ¥ is fake. It
was easier to GIMP it than to reword the sentences so that the backslashes
landed on the second byte of a 2-byte half-width character pair.
The font weights and effects available through \b, including the glitch with
\b3 in TH04 and TH05.
Font weight 3 is technically not rendered correctly in TH03 either; if
you compare 1️⃣ with 4️⃣, you notice a single missing column of pixels
at the left side of each glyph, which would extend into the previous
VRAM byte. Ironically, the TH04/TH05 version is more correct in
this regard: For half-width glyphs, it preserves any further pixel
columns generated by the weight functions in the high byte of the 16-dot
glyph variable. Unlike TH03, which still cuts them off when rendering
text to unaligned X positions (3️⃣), TH04 and TH05 do bit-rotate them
towards their correct place (4️⃣). It's only at byte-aligned X positions
(2️⃣) where they remain at their internally calculated place, and appear
on screen as these glitched pixel columns, 15 pixels away from the glyph
they belong to. It's easy to blame bugs like these on micro-optimized
ASM code, but in this instance, you really can't argue against it if the
original C++ version was equally incorrect.
Combining \b and s- into a partial dissolve
animation. The speed can be controlled with \v.
Simulating TH03's typing effect in TH04 and TH05 via \w. Even prettier in TH05 where we
also get an additional fade animation
after the box ends.
So yeah, that's the cutscene system. I'm dreading the moment I will have to
deal with the other command interpreter in these games, i.e., the
stage enemy system. Luckily, that one is completely disconnected from any
other system, so I won't have to deal with it until we're close to finishing
MAIN.EXE… that is, unless someone requests it before. And it
won't involve text encodings or unblitting…
The cutscene system got me thinking in greater detail about how I would
implement translations, being one of the main dependencies behind them. This
goal has been on the order form for a while and could soon be implemented
for these cutscenes, with 100% PI being right around the corner for the TH03
and TH04 cutscene executables.
Once we're there, the "Virgin" old-school way of static translation patching
for Latin-script languages could be implemented fairly quickly:
Establish basic UTF-8 parsing for less painful manual editing of the
source files
Procedurally generate glyphs for the few required additional letters
based on existing font ROM glyphs. For example, we'd generate ä
by painting two short lines on top of the font ROM's a glyph,
or generate ¿ by vertically flipping the question mark. This
way, the text retains a consistent look regardless of whether the translated
game is run with an NEC or EPSON font ROM, or the that Neko Project II auto-generates if you
don't provide either.
(Optional) Change automatic line breaks to work on a per-word
basis, rather than per-glyph
That's it – script editing and distribution would be handled by your local
translation group. It might seem as if this would also work for Greek and
Cyrillic scripts due to their presence in the PC-98 font ROM, but I'm not
sure if I want to attempt procedurally shrinking these glyphs from 16×16 to
8×16… For any more thorough solution, we'd need to go for a more "Chad" kind
of full-blown translation support:
Implement text subdivisions at a sensible granularity while retaining
automatic line and box breaks
Compile translatable text into a Japanese→target language dictionary
(I'm too old to develop any further translation systems that would overwrite
modded source text with translations of the original text)
Implement a custom Unicode font system (glyphs would be taken from GNU
Unifont unless translators provide a different 8×16 font for their
language)
Combine the text compiler with the font compiler to only store needed
glyphs as part of the translation's font file (dealing with a multi-MB font
file would be rather ugly in a Real Mode game)
Write a simple install/update/patch stacking tool that supports both
.HDI and raw-file DOSBox-X scenarios (it's different enough from thcrap to
warrant a separate tool – each patch stack would be statically compiled into
a single package file in the game's directory)
Add a nice language selection option to the main menu
(Optional) Support proportional fonts
Which sounds more like a separate project to be commissioned from
Touhou Patch Center's Open Collective funds, separate from the ReC98 cap.
This way, we can make sure that the feature is completely implemented, and I
can talk with every interested translator to make sure that their language
works.
It's still cheaper overall to do this on PC-98 than to first port the games
to a modern system and then translate them. On the other hand, most
of the tasks in the Chad variant (3, 4, 5, and half of 2) purely deal with
the difficulty of getting arbitrary Unicode characters to work natively in a
PC-98 DOS game at all, and would be either unnecessary or trivial if we had
already ported the game. Depending on where the patrons' interests lie, it
may not be worth it. So let's see what all of you think about which
way we should go, or whether it's worth doing at all. (Edit
(2022-12-01): With Splashman's
order towards the stage dialogue system, we've pretty much confirmed that it
is.) Maybe we want to meet in the middle – using e.g. procedural glyph
generation for dynamic translations to keep text rendering consistent with
the rest of the PC-98 system, and just not support non-Latin-script
languages in the beginning? In any case, I've added both options to the
order form. Edit (2023-07-28):Touhou Patch Center has agreed to fund
a basic feature set somewhere between the Virgin and Chad level. Check the
📝 dedicated announcement blog post for more
details and ideas, and to find out how you can support this goal!
Surprisingly, there was still a bit of RE work left in the third push after
all of this, which I filled with some small rendering boilerplate. Since I
also wanted to include TH02's playfield overlay functions,
1/15 of that last push went towards getting a
TH02-exclusive function out of the way, which also ended up including that
game in this delivery.
The other small function pointed out how TH05's Stage 5 midboss pops into
the playfield quite suddenly, since its clipping test thinks it's only 32
pixels tall rather than 64:
Good chance that the pop-in might have been intended. Edit (2023-06-30): Actually, it's a
📝 systematic consequence of ZUN having to work around the lack of clipping in master.lib's sprite functions.
There's even another quirk here: The white flash during its first frame
is actually carried over from the previous midboss, which the
game still considers as actively getting hit by the player shot that
defeated it. It's the regular boilerplate code for rendering a
midboss that resets the responsible damage variable, and that code
doesn't run during the defeat explosion animation.
Next up: Staying with TH05 and looking at more of the pattern code of its
boss fights. Given the remaining TH05 budget, it makes the most sense to
continue in in-game order, with Sara and the Stage 2 midboss. If more money
comes in towards this goal, I could alternatively go for the Mai & Yuki
fight and immediately develop a pretty fix for the cheeto storage
glitch. Also, there's a rather intricate
pull request for direct ZMBV decoding on the website that I've still got
to review…
Wow, it's been 3 days and I'm already back with an unexpectedly long post
about TH01's bonus point screens? 3 days used to take much longer in my
previous projects…
Before I talk about graphics for the rest of this post, let's start with the
exact calculations for both bonuses. Touhou Wiki already got these right,
but it still makes sense to provide them here, in a format that allows you
to cross-reference them with the source code more easily. For the
card-flipping stage bonus:
Time
min((Stage timer * 3), 6553)
Continuous
min((Highest card combo * 100), 6553)
Bomb&Player
min(((Lives * 200) + (Bombs * 100)), 6553)
STAGE
min(((Stage number - 1) * 200), 6553)
BONUS Point
Sum of all above values * 10
The boss stage bonus is calculated from the exact same metrics, despite half
of them being labeled differently. The only actual differences are in the
higher multipliers and in the cap for the stage number bonus. Why remove it
if raising it high enough also effectively disables it?
Time
min((Stage timer * 5), 6553)
Continuous
min((Highest card combo * 200), 6553)
MIKOsan
min(((Lives * 500) + (Bombs * 200)), 6553)
Clear
min((Stage number * 1000), 65530)
TOTLE
Sum of all above values * 10
The transition between the gameplay and TOTLE screens is one of the more
impressive effects showcased in this game, especially due to how wavy it
often tends to look. Aside from the palette interpolation (which is, by the
way, the first time ZUN wrote a correct interpolation algorithm between two
4-bit palettes), the core of the effect is quite simple. With the TOTLE
image blitted to VRAM page 1:
Shift the contents of a line on VRAM page 0 by 32 pixels, alternating
the shift direction between right edge → left edge (even Y
values) and the other way round (odd Y values)
Keep a cursor for the destination pixels on VRAM page 1 for every line,
starting at the respective opposite edge
Blit the 32 pixels at the VRAM page 1 cursor to the newly freed 32
pixels on VRAM page 0, and advance the cursor towards the other edge
Successive line shifts will then include these newly blitted 32 pixels
as well
Repeat (640 / 32) = 20 times, after which all new pixels
will be in their intended place
So it's really more like two interlaced shift effects with opposite
directions, starting on different scanlines. No trigonometry involved at
all.
Horizontally scrolling pixels on a single VRAM page remains one of the few
📝 appropriate uses of the EGC in a fullscreen 640×400 PC-98 game,
regardless of the copied block size. The few inter-page copies in this
effect are also reasonable: With 8 new lines starting on each effect frame,
up to (8 × 20) = 160 lines are transferred at any given time, resulting
in a maximum of (160 × 2 × 2) = 640 VRAM page switches per frame for the newly
transferred pixels. Not that frame rate matters in this situation to begin
with though, as the game is doing nothing else while playing this effect.
What does sort of matter: Why 32 pixels every 2 frames, instead of 16
pixels on every frame? There's no performance difference between doing one
half of the work in one frame, or two halves of the work in two frames. It's
not like the overhead of another loop has a serious impact here,
especially with the PC-98 VRAM being said to have rather high
latencies. 32 pixels over 2 frames is also harder to code, so ZUN
must have done it on purpose. Guess he really wanted to go for that 📽
cinematic 30 FPS look 📽 here…
Removing the palette interpolation and transitioning from a black screen
to CLEAR3.GRP makes it a lot clearer how the effect works.
Once all the metrics have been calculated, ZUN animates each value with a
rather fancy left-to-right typing effect. As 16×16 images that use a single
bright-red color, these numbers would be
perfect candidates for gaiji… except that ZUN wanted to render them at the
more natural Y positions of the labels inside CLEAR3.GRP that
are far from aligned to the 8×16 text RAM grid. Not having been in the mood
for hardcoding another set of monochrome sprites as C arrays that day, ZUN
made the still reasonable choice of storing the image data for these numbers
in the single-color .GRC form– yeah, no, of course he once again
chose the .PTN hammer, and its
📝 16×16 "quarter" wrapper functions around nominal 32×32 sprites.
The three 32×32 TOTLE metric digit sprites inside
NUMB.PTN.
Why do I bring up such a detail? What's actually going on there is that ZUN
loops through and blits each digit from 0 to 9, and then continues the loop
with "digit" numbers from 10 to 19, stopping before the number whose ones
digit equals the one that should stay on screen. No problem with that in
theory, and the .PTN sprite selection is correct… but the .PTN
quarter selection isn't, as ZUN wrote (digit % 4)
instead of the correct ((digit % 10) % 4).
Since .PTN quarters are indexed in a row-major
way, the 10-19 part of the loop thus ends up blitting
2 →
3 →
0 →
1 →
6 →
7 →
4 →
5 →
(nothing):
This footage was slowed down to show one sprite blitting operation per
frame. The actual game waits a hardcoded 4 milliseconds between each
sprite, so even theoretically, you would only see roughly every
4th digit. And yes, we can also observe the empty quarter
here, only blitted if one of the digits is a 9.
Seriously though? If the deadline is looming and you've got to rush
some part of your game, a standalone screen that doesn't affect
anything is the best place to pick. At 4 milliseconds per digit, the
animation goes by so fast that this quirk might even add to its
perceived fanciness. It's exactly the reason why I've always been rather
careful with labeling such quirks as "bugs". And in the end, the code does
perform one more blitting call after the loop to make sure that the correct
digit remains on screen.
The remaining ¾ of the second push went towards transferring the final data
definitions from ASM to C land. Most of the details there paint a rather
depressing picture about ZUN's original code layout and the bloat that came
with it, but it did end on a real highlight. There was some unused data
between ZUN's non-master.lib VSync and text RAM code that I just moved away
in September 2015 without taking a closer look at it. Those bytes kind of
look like another hardcoded 1bpp image though… wait, what?!
Lovely! With no mouse-related code left in the game otherwise, this cursor
sprite provides some great fuel for wild fan theories about TH01's
development history:
Could ZUN have 📝 stolen the basic PC-98
VSync or text RAM function code from a source that also implemented mouse
support?
Or was this game actually meant to have mouse-controllable portions at
some point during development? Even if it would have just been the
menus.
… Actually, you know what, with all shared data moved to C land, I might as
well finish FUUIN.EXE right now. The last secret hidden in its
main() function: Just like GAME.BAT supports
launching the game in various debug modes from the DOS command line,
FUUIN.EXE can directly launch one of the game's endings. As
long as the MDRV2 driver is installed, you can enter
fuuin t1 for the 魔界/Makai Good Ending, or
fuuin t for 地獄/Jigoku Good Ending.
Unfortunately, the command-line parameter can only control the route.
Choosing between a Good or Bad Ending is still done exclusively through
TH01's resident structure, and the continues_per_scene array in
particular. But if you pre-allocate that structure somehow and set one of
the members to a nonzero value, it would work. Trainers, anyone?
Alright, gotta get back to the code if I want to have any chance of
finishing this game before the 15th… Next up: The final 17
functions in REIIDEN.EXE that tie everything together and add
some more debug features on top.
Oh look, it's another rather short and straightforward boss with a rather
small number of bugs and quirks. Yup, contrary to the character's
popularity, Mima's premiere is really not all that special in terms of code,
and continues the trend established with
📝 Kikuri and
📝 SinGyoku. I've already covered
📝 the initial sprite-related bugs last November,
so this post focuses on the main code of the fight itself. The overview:
The TH01 Mima fight consists of 3 phases, with phases 1 and 3 each
corresponding to one half of the 12-HP bar.
📝 Just like with SinGyoku, the distinction
between the red-white and red parts is purely visual once again, and doesn't
reflect anything about the boss script. As usual, all of the phases have to
be completed in order.
Phases 1 and 3 cycle through 4 danmaku patterns each, for a total of 8.
The cycles always start on a fixed pattern.
3 of the patterns in each phase feature rotating white squares, thus
introducing a new sprite in need of being unblitted.
Phase 1 additionally features the "hop pattern" as the last one in its
cycle. This is the only pattern where Mima leaves the seal in the center of
the playfield to hop from one edge of the playfield towards the other, while
also moving slightly higher up on the Y axis, and staying on the final
position for the next pattern cycle. For the first time, Mima selects a
random starting edge, which is then alternated on successive cycles.
Since the square entities are local to the respective pattern function,
Phase 1 can only end once the current pattern is done, even if Mima's HP are
already below 6. This makes Mima susceptible to the
📝 test/debug mode HP bar heap corruption bug.
Phase 2 simply consists of a spread-in teleport back to Mima's initial
position in the center of the playfield. This would only have been strictly
necessary if phase 1 ended on the hop pattern, but is done regardless of the
previous pattern, and does provide a nice visual separation between the two
main phases.
That's it – nothing special in Phase 3.
And there aren't even any weird hitboxes this time. What is maybe
special about Mima, however, is how there's something to cover about all of
her patterns. Since this is TH01, it's won't surprise anyone that the
rotating square patterns are one giant copy-pasta of unblitting, updating,
and rendering code. At least ZUN placed the core polar→Cartesian
transformation in a separate function for creating regular polygons
with an arbitrary number of sides, which might hint toward some more varied
shapes having been planned at one point?
5 of the 6 patterns even follow the exact same steps during square update
frames:
Calculate square corner coordinates
Unblit the square
Update the square angle and radius
Use the square corner coordinates for spawning pellets or missiles
Recalculate square corner coordinates
Render the square
Notice something? Bullets are spawned before the corner coordinates
are updated. That's why their initial positions seem to be a bit off – they
are spawned exactly in the corners of the square, it's just that it's
the square from 8 frames ago.
Mima's first pattern on Normal difficulty.
Once ZUN reached the final laser pattern though, he must have noticed that
there's something wrong there… or maybe he just wanted to fire those
lasers independently from the square unblit/update/render timer for a
change. Spending an additional 16 bytes of the data segment for conveniently
remembering the square corner coordinates across frames was definitely a
decent investment.
When Mima isn't shooting bullets from the corners of a square or hopping
across the playfield, she's raising flame pillars from the bottom of the playfield within very specifically calculated
random ranges… which are then rendered at byte-aligned VRAM positions, while
collision detection still uses their actual pixel position. Since I don't
want to sound like a broken record all too much, I'll just direct you to
📝 Kikuri, where we've seen the exact same issue with the teardrop ripple sprites.
The conclusions are identical as well.
Mima's flame pillar pattern. This video was recorded on a particularly
unlucky seed that resulted in great disparities between a pillar's
internal X coordinate and its byte-aligned on-screen appearance, leading
to lots of right-shifted hitboxes.
Also note how the change from the meteor animation to the three-arm 🚫
casting sprite doesn't unblit the meteor, and leaves that job to
any sprite that happens to fly over those pixels.
However, I'd say that the saddest part about this pattern is how choppy it
is, with the circle/pillar entities updating and rendering at a meager 7
FPS. Why go that low on purpose when you can just make the game render ✨
smoothly ✨ instead?
So smooth it's almost uncanny.
The reason quickly becomes obvious: With TH01's lack of optimization, going
for the full 56.4 FPS would have significantly slowed down the game on its
intended 33 MHz CPUs, requiring more than cheap surface-level ASM
optimization for a stable frame rate. That might very well have been ZUN's
reason for only ever rendering one circle per frame to VRAM, and designing
the pattern with these time offsets in mind. It's always been typical for
PC-98 developers to target the lowest-spec models that could possibly still
run a game, and implementing dynamic frame rates into such an engine-less
game is nothing I would wish on anybody. And it's not like TH01 is
particularly unique in its choppiness anyway; low frame rates are actually a
rather typical part of the PC-98 game aesthetic.
The final piece of weirdness in this fight can be found in phase 1's hop
pattern, and specifically its palette manipulation. Just from looking at the
pattern code itself, each of the 4 hops is supposed to darken the hardware
palette by subtracting #444 from every color. At the last hop,
every color should have therefore been reduced to a pitch-black
#000, leaving the player completely blind to the movement of
the chasing pellets for 30 frames and making the pattern quite ghostly
indeed. However, that's not what we see in the actual game:
Nothing in the pattern's code would cause the hardware palette to get
brighter before the end of the pattern, and yet…
The expected version doesn't look all too unfair, even on Lunatic…
well, at least at the default rank pellet speed shown in this
video. At maximum pellet speed, it is in fact rather brutal.
Looking at the frame counter, it appears that something outside the
pattern resets the palette every 40 frames. The only known constant with a
value of 40 would be the invincibility frames after hitting a boss with the
Orb, but we're not hitting Mima here…
But as it turns out, that's exactly where the palette reset comes from: The
hop animation darkens the hardware palette directly, while the
📝 infamous 12-parameter boss collision handler function
unconditionally resets the hardware palette to the "default boss palette"
every 40 frames, regardless of whether the boss was hit or not. I'd classify
this as a bug: That function has no business doing periodic hardware palette
resets outside the invincibility flash effect, and it completely defies
common sense that it does.
That explains one unexpected palette change, but could this function
possibly also explain the other infamous one, namely, the temporary green
discoloration in the Konngara fight? That glitch comes down to how the game
actually uses two global "default" palettes: a default boss
palette for undoing the invincibility flash effect, and a default
stage palette for returning the colors back to normal at the end of
the bomb animation or when leaving the Pause menu. And sure enough, the
stage palette is the one with the green color, while the boss
palette contains the intended colors used throughout the fight. Sending the
latter palette to the graphics chip every 40 frames is what corrects
the discoloration, which would otherwise be permanent.
The green color comes from BOSS7_D1.GRP, the scrolling
background of the entrance animation. That's what turns this into a clear
bug: The stage palette is only set a single time in the entire fight,
at the beginning of the entrance animation, to the palette of this image.
Apart from consistency reasons, it doesn't even make sense to set the stage
palette there, as you can't enter the Pause menu or bomb during a blocking
animation function.
And just 3 lines of code later, ZUN loads BOSS8_A1.GRP, the
main background image of the fight. Moving the stage palette assignment
there would have easily prevented the discoloration.
But yeah, as you can tell, palette manipulation is complete jank in this
game. Why differentiate between a stage and a boss palette to begin with?
The blocking Pause menu function could have easily copied the original
palette to a local variable before darkening it, and then restored it after
closing the menu. It's not so easy for bombs as the intended palette could
change between the start and end of the animation, but the code could have
still been simplified a lot if there was just one global "default palette"
variable instead of two. Heck, even the other bosses who manipulate their
palettes correctly only do so because they manually synchronize the two
after every change. The proper defense against bugs that result from wild
mutation of global state is to get rid of global state, and not to put up
safety nets hidden in the middle of existing effect code.
The easiest way of reproducing the green discoloration bug in
the TH01 Konngara fight, timed to show the maximum amount of time the
discoloration can possibly last.
In any case, that's Mima done! 7th PC-98 Touhou boss fully
decompiled, 24 bosses remaining, and 59 functions left in all of TH01.
In other thrilling news, my call for secondary funding priorities in new
TH01 contributions has given us three different priorities so far. This
raises an interesting question though: Which of these contributions should I
now put towards TH01 immediately, and which ones should I leave in the
backlog for the time being? Since I've never liked deciding on priorities,
let's turn this into a popularity contest instead: The contributions with
the least popular secondary priorities will go towards TH01 first, giving
the most popular priorities a higher chance to still be left over after TH01
is done. As of this delivery, we'd have the following popularity order:
TH05 (1.67 pushes), from T0182
Seihou (1 push), from T0184
TH03 (0.67 pushes), from T0146
Which means that T0146 will be consumed for TH01 next, followed by T0184 and
then T0182. I only assign transactions immediately before a delivery though,
so you all still have the chance to change up these priorities before the
next one.
Next up: The final boss of TH01 decompilation, YuugenMagan… if the current
or newly incoming TH01 funds happen to be enough to cover the entire fight.
If they don't turn out to be, I will have to pass the time with some Seihou
work instead, missing the TH01 anniversary deadline as a result.Edit (2022-07-18): Thanks to Yanga for
securing the funding for YuugenMagan after all! That fight will feature
slightly more than half of all remaining code in TH01's
REIIDEN.EXE and the single biggest function in all of PC-98
Touhou, let's go!
What's this? A simple, straightforward, easy-to-decompile TH01 boss with
just a few minor quirks and only two rendering-related ZUN bugs? Yup, 2½
pushes, and Kikuri was done. Let's get right into the overview:
Just like 📝 Elis, Kikuri's fight consists
of 5 phases, excluding the entrance animation. For some reason though, they
are numbered from 2 to 6 this time, skipping phase 1? For consistency, I'll
use the original phase numbers from the source code in this blog post.
The main phases (2, 5, and 6) also share Elis' HP boundaries of 10, 6,
and 0, respectively, and are once again indicated by different colors in the
HP bar. They immediately end upon reaching the given number of HP, making
Kikuri immune to the
📝 heap corruption in test or debug mode that can happen with Elis and Konngara.
Phase 2 solely consists of the infamous big symmetric spiral
pattern.
Phase 3 fades Kikuri's ball of light from its default bluish color to bronze over 100 frames. Collision detection is deactivated
during this phase.
In Phase 4, Kikuri activates her two souls while shooting the spinning
8-pellet circles from the previously activated ball. The phase ends shortly
after the souls fired their third spread pellet group.
Note that this is a timed phase without an HP boundary, which makes
it possible to reduce Kikuri's HP below the boundaries of the next
phases, effectively skipping them. Take this video for example,
where Kikuri has 6 HP by the end of Phase 4, and therefore directly
starts Phase 6.
(Obviously, Kikuri's HP can also be reduced to 0 or below, which will
end the fight immediately after this phase.)
Phase 5 combines the teardrop/ripple "pattern" from the souls with the
"two crossed eye laser" pattern, on independent cycles.
Finally, Kikuri cycles through her remaining 4 patterns in Phase 6,
while the souls contribute single aimed pellets every 200 frames.
Interestingly, all HP-bounded phases come with an additional hidden
timeout condition:
Phase 2 automatically ends after 6 cycles of the spiral pattern, or
5,400 frames in total.
Phase 5 ends after 1,600 frames, or the first frame of the
7th cycle of the two crossed red lasers.
If you manage to keep Kikuri alive for 29 of her Phase 6 patterns,
her HP are automatically set to 1. The HP bar isn't redrawn when this
happens, so there is no visual indication of this timeout condition even
existing – apart from the next Orb hit ending the fight regardless of
the displayed HP. Due to the deterministic order of patterns, this
always happens on the 8th cycle of the "symmetric gravity
pellet lines from both souls" pattern, or 11,800 frames. If dodging and
avoiding orb hits for 3½ minutes sounds tiring, you can always watch the
byte at DS:0x1376 in your emulator's memory viewer. Once
it's at 0x1E, you've reached this timeout.
So yeah, there's your new timeout challenge.
The few issues in this fight all relate to hitboxes, starting with the main
one of Kikuri against the Orb. The coordinates in the code clearly describe
a hitbox in the upper center of the disc, but then ZUN wrote a < sign
instead of a > sign, resulting in an in-game hitbox that's not
quite where it was intended to be…
Kikuri's actual hitbox.
Since the Orb sprite doesn't change its shape, we can visualize the
hitbox in a pixel-perfect way here. The Orb must be completely within
the red area for a hit to be registered.
Much worse, however, are the teardrop ripples. It already starts with their
rendering routine, which places the sprites from TAMAYEN.PTN at byte-aligned VRAM positions in the ultimate piece of if(…) {…}
else if(…) {…} else if(…) {…} meme code. Rather than
tracking the position of each of the five ripple sprites, ZUN suddenly went
purely functional and manually hardcoded the exact rendering and collision
detection calls for each frame of the animation, based on nothing but its
total frame counter.
Each of the (up to) 5 columns is also unblitted and blitted individually
before moving to the next column, starting at the center and then
symmetrically moving out to the left and right edges. This wouldn't be a
problem if ZUN's EGC-powered unblitting function didn't word-align its X
coordinates to a 16×1 grid. If the ripple sprites happen to start at an
odd VRAM byte position, their unblitting coordinates get rounded both down
and up to the nearest 16 pixels, thus touching the adjacent 8 pixels of the
previously blitted columns and leaving the well-known black vertical bars in
their place.
OK, so where's the hitbox issue here? If you just look at the raw
calculation, it's a slightly confusingly expressed, but perfectly logical 17
pixels. But this is where byte-aligned blitting has a direct effect on
gameplay: These ripples can be spawned at any arbitrary, non-byte-aligned
VRAM position, and collisions are calculated relative to this internal
position. Therefore, the actual hitbox is shifted up to 7 pixels to the
right, compared to where you would expect it from a ripple sprite's
on-screen position:
Due to the deterministic nature of this part of the fight, it's
always 5 pixels for this first set of ripples. These visualizations are
obviously not pixel-perfect due to the different potential shapes of
Reimu's sprite, so they instead relate to her 32×32 bounding box, which
needs to be entirely inside the red
area.
We've previously seen the same issue with the
📝 shot hitbox of Elis' bat form, where
pixel-perfect collision detection against a byte-aligned sprite was merely a
sidenote compared to the more serious X=Y coordinate bug. So why do I
elevate it to bug status here? Because it directly affects dodging: Reimu's
regular movement speed is 4 pixels per frame, and with the internal position
of an on-screen ripple sprite varying by up to 7 pixels, any micrododging
(or "grazing") attempt turns into a coin flip. It's sort of mitigated
by the fact that Reimu is also only ever rendered at byte-aligned
VRAM positions, but I wouldn't say that these two bugs cancel out each
other.
Oh well, another set of rendering issues to be fixed in the hypothetical
Anniversary Edition – obviously, the hitboxes should remain unchanged. Until
then, you can always memorize the exact internal positions. The sequence of
teardrop spawn points is completely deterministic and only controlled by the
fixed per-difficulty spawn interval.
Aside from more minor coordinate inaccuracies, there's not much of interest
in the rest of the pattern code. In another parallel to Elis though, the
first soul pattern in phase 4 is aimed on every difficulty except
Lunatic, where the pellets are once again statically fired downwards. This
time, however, the pattern's difficulty is much more appropriately
distributed across the four levels, with the simultaneous spinning circle
pellets adding a constant aimed component to every difficulty level.
Kikuri's phase 4 patterns, on every difficulty.
That brings us to 5 fully decompiled PC-98 Touhou bosses, with 26 remaining…
and another ½ of a push going to the cutscene code in
FUUIN.EXE.
You wouldn't expect something as mundane as the boss slideshow code to
contain anything interesting, but there is in fact a slight bit of
speculation fuel there. The text typing functions take explicit string
lengths, which precisely match the corresponding strings… for the most part.
For the "Gatekeeper 'SinGyoku'" string though, ZUN passed 23
characters, not 22. Could that have been the "h" from the Hepburn
romanization of 神玉?!
Also, come on, if this text is already blitted to VRAM for no reason,
you could have gone for perfect centering at unaligned byte positions; the
rendering function would have perfectly supported it. Instead, the X
coordinates are still rounded up to the nearest byte.
The hardcoded ending cutscene functions should be even less interesting –
don't they just show a bunch of images followed by frame delays? Until they
don't, and we reach the 地獄/Jigoku Bad Ending with
its special shake/"boom" effect, and this picture:
Picture #2 from ED2A.GRP.
Which is rendered by the following code:
for(int i = 0; i <= boom_duration; i++) { // (yes, off-by-one)
if((i & 3) == 0) {
graph_scrollup(8);
} else {
graph_scrollup(0);
}
end_pic_show(1); // ← different picture is rendered
frame_delay(2); // ← blocks until 2 VSync interrupts have occurred
if(i & 1) {
end_pic_show(2); // ← picture above is rendered
} else {
end_pic_show(1);
}
}
Notice something? You should never see this picture because it's
immediately overwritten before the frame is supposed to end. And yet
it's clearly flickering up for about one frame with common emulation
settings as well as on my real PC-9821 Nw133, clocked at 133 MHz.
master.lib's graph_scrollup() doesn't block until VSync either,
and removing these calls doesn't change anything about the blitted images.
end_pic_show() uses the EGC to blit the given 320×200 quarter
of VRAM from page 1 to the visible page 0, so the bottleneck shouldn't be
there either…
…or should it? After setting it up via a few I/O port writes, the common
method of EGC-powered blitting works like this:
Read 16 bits from the source VRAM position on any single
bitplane. This fills the EGC's 4 16-bit tile registers with the VRAM
contents at that specific position on every bitplane. You do not care
about the value the CPU returns from the read – in optimized code, you would
make sure to just read into a register to avoid useless additional stores
into local variables.
Write any 16 bits
to the target VRAM position on any single bitplane. This copies the
contents of the EGC's tile registers to that specific position on
every bitplane.
To transfer pixels from one VRAM page to another, you insert an additional
write to I/O port 0xA6 before 1) and 2) to set your source and
destination page… and that's where we find the bottleneck. Taking a look at
the i486 CPU and its cycle
counts, a single one of these page switches costs 17 cycles – 1 for
MOVing the page number into AL, and 16 for the
OUT instruction itself. Therefore, the 8,000 page switches
required for EGC-copying a 320×200-pixel image require 136,000 cycles in
total.
And that's the optimal case of using only those two
instructions. 📝 As I implied last time, TH01
uses a function call for VRAM page switches, complete with creating
and destroying a useless stack frame and unnecessarily updating a global
variable in main memory. I tried optimizing ZUN's code by throwing out
unnecessary code and using 📝 pseudo-registers
to generate probably optimal assembly code, and that did speed up the
blitting to almost exactly 50% of the original version's run time. However,
it did little about the flickering itself. Here's a comparison of the first
loop with boom_duration = 16, recorded in DOSBox-X with
cputype=auto and cycles=max, and with
i overlaid using the text chip. Caution, flashing lights:
The original animation, completing in 50 frames instead of the expected
34, thanks to slow blitting. Combined with the lack of
double-buffering, this results in noticeable tearing as the screen
refreshes while blitting is still in progress.
(Note how the background of the ドカーン image is shifted 1 pixel to the left compared to pic
#1.)
This optimized version completes in the expected 34 frames. No tearing
happens to be visible in this recording, but the ドカーン image is still visible on every
second loop iteration. (Note how the background of the ドカーン image is shifted 1 pixel to the left compared to pic
#1.)
I pushed the optimized code to the th01_end_pic_optimize
branch, to also serve as an example of how to get close to optimal code out
of Turbo C++ 4.0J without writing a single ASM instruction.
And if you really want to use the EGC for this, that's the best you can do.
It really sucks that it merely expanded the GRCG's 4×8-bit tile register to
4×16 bits. With 32 bits, ≥386 CPUs could have taken advantage of their wider
registers and instructions to double the blitting performance. Instead, we
now know the reason why
📝 Promisence Soft's EGC-powered sprite driver that ZUN later stole for TH03
is called SPRITE16 and not SPRITE32. What a massive disappointment.
But what's perhaps a bigger surprise: Blitting planar
images from main memory is much faster than EGC-powered inter-page
VRAM copies, despite the required manual access to all 4 bitplanes. In
fact, the blitting functions for the .CDG/.CD2 format, used from TH03
onwards, would later demonstrate the optimal method of using REP
MOVSD for blitting every line in 32-pixel chunks. If that was also
used for these ending images, the core blitting operation would have taken
((12 + (3 × (320 / 32))) × 200 × 4) =
33,600 cycles, with not much more overhead for the surrounding row
and bitplane loops. Sure, this doesn't factor in the whole infamous issue of
VRAM being slow on PC-98, but the aforementioned 136,000 cycles don't even
include any actual blitting either. And as you move up to later PC-98
models with Pentium CPUs, the gap between OUT and REP
MOVSD only becomes larger. (Note that the page I linked above has a
typo in the cycle count of REP MOVSD on Pentium CPUs: According
to the original Intel Architecture and Programming Manual, it's
13+𝑛, not 3+𝑛.)
This difference explains why later games rarely use EGC-"accelerated"
inter-page VRAM copies, and keep all of their larger images in main memory.
It especially explains why TH04 and TH05 can get away with naively redrawing
boss backdrop images on every frame.
In the end, the whole fact that ZUN did not define how long this image
should be visible is enough for me to increment the game's overall bug
counter. Who would have thought that looking at endings of all things
would teach us a PC-98 performance lesson… Sure, optimizing TH01 already
seemed promising just by looking at its bloated code, but I had no idea that
its performance issues extended so far past that level.
That only leaves the common beginning part of all endings and a short
main() function before we're done with FUUIN.EXE,
and 98 functions until all of TH01 is decompiled! Next up: SinGyoku, who not
only is the quickest boss to defeat in-game, but also comes with the least
amount of code. See you very soon!


 and
and  labels clearly give it away as copy-pasted:
labels clearly give it away as copy-pasted:


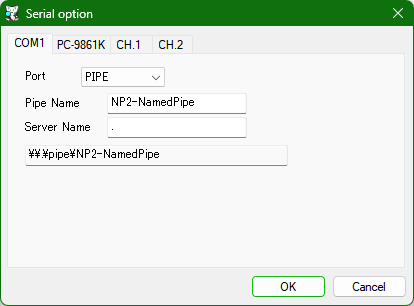

 This surely must have been left in on purpose for us to laugh about it one day?
This surely must have been left in on purpose for us to laugh about it one day?



 , past right edge of current row
, past right edge of current row gaiji. Not to be confused with
gaiji. Not to be confused with  gaiji.
gaiji. gaiji.
gaiji. gaiji.
gaiji. gaiji.
gaiji. gaiji.
gaiji. gaiji.
gaiji.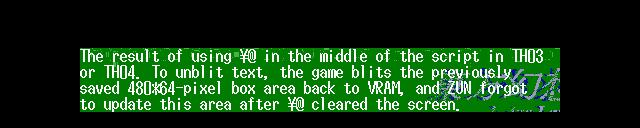
 that Neko Project II auto-generates if you
don't provide either.
that Neko Project II auto-generates if you
don't provide either.



 from the bottom of the playfield within very specifically calculated
random ranges… which are then rendered at byte-aligned VRAM positions, while
collision detection still uses their actual pixel position. Since I don't
want to sound like a broken record all too much, I'll just direct you to
from the bottom of the playfield within very specifically calculated
random ranges… which are then rendered at byte-aligned VRAM positions, while
collision detection still uses their actual pixel position. Since I don't
want to sound like a broken record all too much, I'll just direct you to



 at byte-aligned VRAM positions in the ultimate piece of
at byte-aligned VRAM positions in the ultimate piece of 