I'm 13 days late, but 🎉 ReC98 is now 10 years old! 🎉 On June 26, 2014, I first tried exporting IDA's disassembly of TH05's OP.EXE and reassembling and linking the resulting file back into a binary, and was amazed that it actually yielded an identical binary. Now, this doesn't actually mean that I've spent 10 years working on this project; priorities have been shifting and continue to shift, and time-consuming mistakes were certainly made. Still, it's a good occasion to finally fully realize the good future for ReC98 that GhostPhanom invested in with the very first financial contribution back in 2018, deliver the last three of the first four reserved pushes, cross another piece of time-consuming maintenance off the list, and prepare the build process for hopefully the next 10 years.
But why did it take 8 pushes and over two months to restore feature parity with the old system? 🥲
The original plan for ReC98's good future was quite different from what I ended up shipping here. Before I started writing the code for this website in August 2019, I focused on feature-completing the experimental 16-bit DOS build system for Borland compilers that I'd been developing since 2018, and which would form the foundation of my internal development work in the following years. Eventually, I wanted to polish and publicly release this system as soon as people stopped throwing money at me. But as of November 2019, just one month after launch, the store kept selling out with everyone investing into all the flashier goals, so that release never happened.
In theory, this build system remains the optimal way of developing with old Borland compilers on a real PC-98 (or any other 32-bit single-core system) and outside of Borland's IDE, even after the changes introduced by this delivery. In practice though, you're soon going to realize that there are lots of issues I'd have to revisit in case any PC-98 homebrew developers are interested in funding me to finish and release this tool…
The main idea behind the system still has its charm: Your build script is a regular C++ program that #includes the build system as a static library and passes fixed structures with names of source files and build flags. By employing static constructors, even a 1994 Turbo C++ would let you define the whole build at compile time, although this certainly requires some dank preprocessor magic to remain anywhere near readable at ReC98 scale. 🪄 While this system does require a bootstrapping process, the resulting binary can then use the same dependency-checking mechanisms to recompile and overwrite itself if you change the C++ build code later. Since DOS just simply loads an entire binary into RAM before executing it, there is no lock to worry about, and overwriting the originating binary is something you can just do.
Later on, the system also made use of batched compilation: By passing more than one source file to TCC.EXE, you get to avoid TCC's quite noticeable startup times, thus speeding up the build proportional to the number of translation units in each batch. Of course, this requires that every passed source file is supposed to be compiled with the same set of command-line flags, but that's a generally good complexity-reducing guideline to follow in a build script. I went even further and enforced this guideline in the system itself, thus truly making per-file compiler command line switches considered harmful. Thanks to Turbo C++'s #pragma option, changing the command line isn't even necessary for the few unfortunate cases where parts of ZUN's code were compiled with inconsistent flags.
I combined all these ideas with a general approach of "targeting DOSBox": By maximizing DOS syscalls and minimizing algorithms and data structures, we spend as much time as possible in DOSBox's native-code DOS implementation, which should give us a performance advantage over DOS-native implementations of MAKE that typically follow the opposite approach.
Of course, all this only matters if the system is correct and reliable at its core. Tup teaches us that it's fundamentally impossible to have a reliable generic build system without
augmenting the build graph with all actual files read and written by each invoked build tool, which involves tracing all file-related syscalls, and
persistently serializing the full build graph every time the system runs, allowing later runs to detect every possible kind of change in the build script and rebuild or clean up accordingly.
Unfortunately, the design limitations of my system only allowed half-baked attempts at solving both of these prerequisites:
If your build system is not supposed to be generic and only intended to work with specific tools that emit reliable dependency information, you can replace syscall tracing with a parser for those specific formats. This is what my build system was doing, reading dependency information out of each .OBJ file's OMF COMENT record.
Since DOS command lines are limited to 127 bytes, DOS compilers support reading additional arguments from response files, typically indicated with an @ next to their path on the command line. If we now put every parameter passed to TCC or TLINK into a response file and leave these files on disk afterward, we've effectively serialized all command-line arguments of the entire build into a makeshift database. In later builds, the system can then detect changed command-line arguments by comparing the existing response files from the previous run with the new contents it would write based on the current build structures. This way, we still only recompile the parts of the codebase that are affected by the changed arguments, which is fundamentally impossible with Makefiles.
But this strategy only covers changes within each binary's compile or link arguments, and ignores the required deletions in "the database" when removing binaries between build runs. This is a non-issue as long as we keep decompiling on master, but as soon as we switch between master and similarly old commits on the debloated/anniversary branches, we can get very confusing errors:
The symptom is a calling convention mismatch: The two vector functions use __cdecl on master and pascal on debloated/anniversary. We've switched from anniversary (which compiles to ANNIV.EXE) back to master (which compiles to REIIDEN.EXE) here, so the .obj file on disk still uses the pascal calling convention. The build system, however, only checks the response files associated with the current target binary (REIIDEN.EXE) and therefore assumes that the .obj files still reflect the (unchanged) command-line flags in the TCC response file associated with this binary. And if none of the inputs of these .obj files changed between the two branches, they aren't rebuilt after switching, even though they would need to be.
Apparently, there's also such a thing as "too much batching", because TCC would suddenly stop applying certain compiler optimizations at very specific places if too many files were compiled within a single process? At least you quickly remember which source files you then need to manually touch and recompile to make the binaries match ZUN's original ones again…
But the final nail in the coffin was something I'd notice on every single build: 5 years down the line, even the performance argument wasn't convincing anymore. The strategy of minimizing emulated code still left me with an 𝑂(𝑛) algorithm, and with this entire thing still being single-threaded, there was no force to counteract the dependency check times as they grew linearly with the number of source files.
At P0280, each build run would perform a total of 28,130 file-related DOS syscalls to figure out which source files have changed and need to be rebuilt. At some point, this was bound to become noticeable even despite these syscalls being native, not to mention that they're still surrounded by emulator code that must convert their parameters and results to and from the DOS ABI. And with the increasing delays before TCC would do its actual work, the entire thing started feeling increasingly jankier.
While this system was waiting to be eventually finished, the public master branch kept using the Makefile that dates back to early 2015. Back then, it didn't takelong for me to abandon raw dumb batch files because Make was simply the most straightforward way of ensuring that the build process would abort on the first compile error.
The following years also proved that Makefile syntax is quite well-suited for expressing the build rules of a codebase at this scale. The built-in support for automatically turning long commands into response files was especially helpful because of how naturally it works together with batched compilation. Both of these advantages culminate in this wonderfully arcane incantation of ASCII special characters and syntactically significant linebreaks:
tcc … @&&|
$**
|
Which translates to "take the filenames of all dependents of this explicit rule, write them into a temporary file with an autogenerated name, insert this filename into the tcc … @ command line, and delete the file after the command finished executing". The @ is part of TCC's command-line interface, the rest is all MAKE syntax.
But 📝 as we all know by now, these surface-level niceties change nothing about Makefiles inherently being unreliable trash due to implementing none of the aforementioned two essential properties of a generic build system. Borland got so close to a correct and reliable implementation of autodependencies, but that would have just covered one of the two properties. Due to this unreliability, the old build16b.bat called Borland's MAKER.EXE with the -B flag, recompiling everything all the time. Not only did this leave modders with a much worse build process than I was using internally, but it also eventually got old for me to merge my internal branch onto master before every delivery. Let's finally rectify that and work towards a single good build process for everyone.
As you would expect by now, I've once again migrated to Tup's Lua syntax. Rewriting it all makes you realize once again how complex the PC-98 Touhou build process is: It has to cover 2 programming languages, 2 pipeline steps, and 3 third-party libraries, and currently generates a total of 39 executables, including the small programs I wrote for research. The final Lua code comprises over 1,300 lines – but then again, if I had written it in 📝 Zig, it would certainly be as long or even longer due to manual memory management. The Tup building blocks I constructed for Shuusou Gyoku quickly turned out to be the wrong abstraction for a project that has no debug builds, but their 📝 basic idea of a branching tree of command-line options remained at the foundation of this script as well.
This rewrite also provided an excellent opportunity for finally dumping all the intermediate compilation outputs into a separate dedicated obj/ subdirectory, finally leaving bin/ nice and clean with only the final executables. I've also merged this new system into most of the public branches of the GitHub repo.
As soon as I first tried to build it all though, I was greeted with a particularly nasty Tup bug. Due to how DOS specified file metadata mutation, MS-DOS Player has to open every file in a way that current Tup treats as a write access… but since unannotated file writes introduce the risk of a malformed build graph if these files are read by another build command later on, Tup providently deletes these files after the command finished executing. And by these files, I mean TCC.EXE as well as every one of its C library header files opened during compilation.
Due to a minor unsolved question about a failing test case, my fix has not been merged yet. But even if it was, we're now faced with a problem: If you previously chose to set up Tup for ReC98 or 📝 Shuusou Gyoku and are maybe still running 📝 my 32-bit build from September 2020, running the new build.bat would in fact delete the most important files of your Turbo C++ 4.0J installation, forcing you to reinstall it or restore it from a backup. So what do we do?
Should my custom build get a special version number so that the surrounding batch file can fail if the version number of your installed Tup is lower?
Or do I just put a message somewhere, which some people invariably won't read?
The easiest solution, however, is to just put a fixed Tup binary directly into the ReC98 repo. This not only allows me to make Tup mandatory for 64-bit builds, but also cuts out one step in the build environment setup that at least one person previously complained about. *nix users might not like this idea all too much (or do they?), but then again, TASM32 and the Windows-exclusive MS-DOS Player require Wine anyway. Running Tup through Wine as well means that there's only one PATH to worry about, and you get to take advantage of the tool checks in the surrounding batch file.
If you're one of those people who doesn't trust binaries in Git repos, the repo also links to instructions for building this binary yourself. Replicating this specific optimized binary is slightly more involved than the classic ./configure && make && make install trinity, so having these instructions is a good idea regardless of the fact that Tup's GPL license requires it.
One particularly interesting aspect of the Lua code is the way it handles sprite dependencies:
If build commands read from files that were created by other build commands, Tup requires these input dependencies to be spelled out so that it can arrange the build graph and parallelize the build correctly. We could simply put every sprite into a single array and automatically pass that as an extra input to every source file, but that would effectively split the build into a "sprite convert" and "code compile" phase. Spelling out every individual dependency allows such source files to be compiled as soon as possible, before (and in parallel to) the rest of the sprites they don't depend on. Similarly, code files without sprite dependencies can compile before the first sprite got converted, or even before the sprite converter itself got compiled and linked, maximizing the throughput of the overall build process.
Running a 30-year-old DOS toolchain in a parallel build system also introduces new issues, though. The easiest and recommended way of compiling and linking a program in Turbo C++ is a single tcc invocation:
tcc … main.cpp utils.cpp master.lib
This performs a batched compilation of main.cpp and utils.cpp within a single TCC process, and then launches TLINK to link the resulting .obj files into main.exe, together with the C++ runtime library and any needed objects from master.lib. The linking step works by TCC generating a TLINK command line and writing it into a response file with the fixed name turboc.$ln… which obviously can't work in a parallel build where multiple TCC processes will want to link different executables via the same response file.
Therefore, we have to launch TLINK with a custom response file ourselves. This file is echo'd as a separate parallel build rule, and the Lua code that constructs its contents has to replicate TCC's logic for picking the correct C++ runtime .lib file for the selected memory model.
The response file for TH02's ZUN_RES.COM, consisting of the C++ standard library, two files of ZUN code, and master.lib.
While this does add more string formatting logic, not relying on TCC to launch TLINK actually removes the one possible PATH-related error case I previously documented in the README. Back in 2021 when I first stumbled over the issue, it took a few hours of RE to figure this out. I don't like these hours to go to waste, so here's a Gist, and here's the text replicated for SEO reasons:
Issue: TCC compiles, but fails to link, with Unable to execute command 'tlink.exe'
Cause: This happens when invoking TCC as a compiler+linker, without the -c flag. To locate TLINK, TCC needlessly copies the PATH environment variable into a statically allocated 128-byte buffer. It then constructs absolute tlink.exe filenames for each of the semicolon- or \0-terminated paths, writing these into a buffer that immediately follows the 128-byte PATH buffer in memory. The search is finished as soon as TCC finds an existing file, which gives precedence to earlier paths in the PATH. If the search didn't complete until a potential "final" path that runs past the 128 bytes, the final attempted filename will consist of the part that still managed to fit into the buffer, followed by the previously attempted path.
Workaround: Make sure that the BIN\ path to Turbo C++ is fully contained within the first 127 bytes of the PATH inside your DOS system. (The 128th byte must either be a separating ; or the terminating \0 of the PATH string.)
Now that DOS emulation is an integral component of the single-part build process, it even makes sense to compile our pipeline tools as 16-bit DOS executables and then emulate them as part of the build. Sure, it's technically slower, but realistically it doesn't matter: Our only current pipeline tools are 📝 the converter for hardcoded sprites and the 📝 ZUN.COM generators, both of which involve very little code and are rarely run during regular development after the initial full build. In return, we get to drop that awkward dependency on the separate Borland C++ 5.5 compiler for Windows and yet another additional manual setup step. 🗑️ Once PC-98 Touhou becomes portable, we're probably going to require a modern compiler anyway, so you can now delete that one as well.
That gives us perfect dependency tracking and minimal parallel rebuilds across the whole codebase! While MS-DOS Player is noticeably slower than DOSBox-X, it's not going to matter all too much; unless you change one of the more central header files, you're rarely if ever going to cause a full rebuild. Then again, given that I'm going to use this setup for at least a couple of years, it's worth taking a closer look at why exactly the compilation performance is so underwhelming …
On the surface, MS-DOS Player seems like the right tool for our job, with a lot of advantages over DOSBox:
It doesn't spawn a window that boots an entire emulated PC, but is instead
perfectly integrated into the Windows console. Using it in a modern developer console would allow you to click on a compile error and have your editor immediately open the relevant file and jump to that specific line! With DOSBox, this basic comfort feature was previously unthinkable.
Heck, Takeda Toshiya originally developed it to run the equally vintage LSI C-86 compiler on 64-bit Windows. Fixing any potential issues we'd run into would be well within the scope of the project.
It consists of just a single comparatively small binary that we could just drop into the ReC98 repo. No manual setup steps required.
But once I began integrating it, I quickly noticed two glaring flaws:
Back in 2009, Takeda Toshiya chose to start the project by writing a custom DOS implementation from scratch. He was aware of DOSBox, but only adapted small tricky parts of its source code rather than starting with the DOSBox codebase and ripping out everything he didn't need. This matches the more research-oriented nature that all of his projects appear to follow, where the primary goal of writing the code is a personal understanding of the problem domain rather than a widely usable piece of software. MS-DOS Player is even the outlier in this regard, with Takeda Toshiya describing it as 珍しく実用的かもしれません. I am definitely sympathetic to this mindset; heck, my old internal build system falls under this category too, being so specialized and narrow that it made little sense to use it outside of ReC98. But when you apply it to emulators for niche systems, you end up with exactly the current PC-98 emulation scene, where there's no single universally good emulator because all of them have some inaccuracy somewhere. This scene is too small for you not to eventually become part of someone else's supply chain… 🥲
Emulating DOS is a particularly poor fit for a research/NIH project because it's Hyrum's Law incarnate. With the lack of memory protection in Real Mode, programs could freely access internal DOS (and even BIOS) data structures if they only knew where to look, and frequently did. It might look as if "DOS command-line tools" just equals x86 plus INT 21h, but soon you'll also be emulating the BIOS, PIC, PIT, EMS, XMS, and probably a few more things, all with their individual quirks that some application out there relies on. DOSBox simply had much more time to grow and mature and figure out all of these details by trial and error. If you start a DOS emulator from scratch, you're bound to duplicate all this research as people want to use your emulator to run more and more programs, until you've ended up with what's effectively a clone of DOSBox's exact logic. Unless, of course, if you draw a line somewhere and limit the scope of the DOS and BIOS emulation. But given how many people have wanted to use MS-DOS Player for running DOS TUIs in arbitrarily sized terminal windows with arbitrary fonts, that's not what happened. I guess it made sense for this use case before DOSBox-X gained a TTF output mode in late 2020?
As usual, I wouldn't mention this if I didn't run into twobugs when combining MS-DOS Player with Turbo C++ and Tup. Both of these originated from workarounds for inaccuracies in the DOS emulation that date back to MS-DOS Player's initial release and were thankfully no longer necessary with the accuracy improvements implemented in the years since.
For CPU emulation, MS-DOS Player can use either MAME's or Neko Project 21/W's x86 core, both of which are interpreters and won't win any performance contests. The NP21/W core is significantly better optimized and runs ≈41% faster, but still pales in comparison to DOSBox-X's dynamic recompiler. Running the same sequential commands that the P0280 Makefile would execute, the upstream 2024-03-02 NP21/W core build of MS-DOS Player would take to compile the entire ReC98 codebase on my system, whereas DOSBox-X's dynamic core manages the same in , or 94% faster.
Granted, even the DOSBox-X performance is much slower than we would like it to be. Most of it can be blamed on the awkward time in the early-to-mid-90s when Turbo C++ 4.0J came out. This was the time when DOS applications had long grown past the limitations of the x86 Real Mode and required DOS extenders or even sillier hacks to actually use all the RAM in a typical system of that period, but Win32 didn't exist yet to put developers out of this misery. As such, this compiler not only requires at least a 386 CPU, but also brings its own DOS extender (DPMI16BI.OVL) plus a loader for said extender (RTM.EXE), both of which need to be emulated alongside the compiler, to the great annoyance of emulator maintainers 30 years later. Even MS-DOS Player's README file notes how Protected Mode adds a lot of complexity and slowdown:
8086 binaries are much faster than 80286/80386/80486/Pentium4/IA32 binaries.
If you don't need the protected mode or new mnemonics added after 80286,
I recommend i86_x86 or i86_x64 binary.
The immediate reaction to these performance numbers is obvious: Let's just put DOSBox-X's dynamic recompiler into MS-DOS Player, right?! 🙌 Except that once you look at DOSBox-X, you immediately get why Takeda Toshiya might have preferred to start from scratch. Its codebase is a historically grown tangled mess, requiring intimate familiarity and a significant engineering effort to isolate the dynamic core in the first place. I did spend a few days trying to untangle and copy it all over into MS-DOS Player… only to be greeted with an infinite loop as soon as everything compiled for the first time. 😶 Yeah, no, that's bound to turn into a budget-exceeding maintenance nightmare.
Instead, let's look at squeezing at least some additional performance out of what we already have. A generic emulator for the entire CISCy instruction set of the 80386, with complete support for Protected Mode, but it's only supposed to run the subset of instructions and features used by a specific compiler and linker as fast as possible… wait a moment, that sounds like a use case for profile-guided optimization! This is the first time I've encountered a situation that would justify the required 2-phase build process and lengthy profile collection – after all, writing into some sort of database for every function call does slow down MS-DOS Player by roughly 15×. However, profiling just the compilation of our most complex translation unit (📝 TH01 YuugenMagan) and the linking of our largest executable (TH01's REIIDEN.EXE) should be representative enough.
I'll get to the performance numbers later, but even the build output is quite intriguing. Based on this profile, Visual Studio chooses to optimize only 104 out of MS-DOS Player's 1976 functions for speed and the rest for size, shaving off a nice 109 KiB from the binary. Presumably, keeping rare code small is also considered kind of fast these days because it takes up less space in your CPU's instruction cache once it does get executed?
With PGO as our foundation, let's run a performance profile and see if there are any further code-level optimizations worth trying out:
Removing redundant memset() calls: MS-DOS Player is written in a very C-like style of C++, and initializes a bunch of its statically allocated data by memset()ing it with 00 bytes at startup. This is strictly redundant even in C; Section 6.7.9/10 of the C standard mandates that all static data is zero-initialized by default. In turn, the program loaders of modern operating systems employ all sorts of paging tricks to reduce the CPU cost (and actual RAM usage!) of this initialization as much as possible. If you manually memset() afterward, you throw all these advantages out of the window.
Of course, these calls would only ever show up among the top CPU consumers in a performance profile if a program uses a large amount of static data, but the hardcoded 32 MiB of emulated RAM in ≥i386-supporting builds definitely qualifies. Zeroing 32.8 MiB of memory makes up a significant chunk of the runtime of some of the shorter build steps and quickly adds up; a full rebuild of the ReC98 codebase currently spawns a total of 361 MS-DOS Player instances, totaling 11.5 GiB of needless memory writes.
Limiting the emulated instruction set: NP21/W's x86 core emulates everything up to the SSE3 extension from 2004, but Turbo C++ 4.0J's x86 instruction set usage doesn't stretch past the 386. It doesn't even need the x87 FPU for compiling code that involves floating-point constants. Disabling all these unneeded extensions speeds up x86's infamously annoying instruction decoding, and also reduces the size of the MS-DOS Player binary by another 149.5 KiB. The source code already had macros for this purpose, and only needed a slight fix for the code to compile with these macros disabled.
Removing x86 paging: Borland's DOS extender uses segmented memory addressing even in Protected Mode. This allows us to remove the MMU emulation and the corresponding "are we paging" check for every memory access.
Removing cycle counting: When emulating a whole system, counting the cycles of each instruction is important for accurately synchronizing the CPU with other pieces of hardware. As hinted above, MS-DOS Player does emulate and periodically update a few pieces of hardware outside the CPU, but we need none of them for a build tool.
Testing Takeda Toshiya's optimizations: In a nice turn of events, Takeda Toshiya merged every single one of my bugfixes and optimization flags into his upstream codebase. He even agreed with my memset() and cycle counting removal optimizations, which are now part of all upstream builds as of 2024-06-24. For the 2024-06-27 build, he claims to have gone even further than my more minimal optimization, so let's see how these additional changes affect our build process.
Further risky optimizations: A lot of the remaining slowness of x86 emulation comes from the segmentation and protection fault checks required for every memory access. If we assume that the emulator only ever executes correct code, we can remove these checks and implement further shortcuts based on their absence.
The L[DEFGS]S group of instructions that load a segment and offset register from a 32-bit far pointer, for example, are both frequently used in Turbo C++ 4.0J code and particularly expensive to emulate. Intel specified their Real Mode operation as loading the segment and offset part in two separate 16-bit reads. But if we assume that neither of those reads can fault, we can compress them into a single 32-bit read and thus only perform the costly address translation once rather than twice. Emulator authors are probably rolling their eyes at this gross violation of Intel documentation now, but it's at least worth a try to see just how much performance we could get out of it.
Measured on a 6-year-old 6-core Intel Core i5 8400T on Windows 11. The first number in each column represents the codebase before the #include cleanup explained below, and the second one corresponds to this commit. All builds are 64-bit, 32-bit builds were ≈5% slower across the board. I kept the fastest run within three attempts; as Tup parallelizes the build process across all CPU cores, it's common for the long-running full build to take up to a few seconds longer depending on what else is running on your system. Tup's standard output is also redirected to a file here; its regular terminal output and nice progress bar will add more slowdown on top.
The key takeaways:
By merely disabling certain x86 features from MS-DOS Player and retaining the accuracy of the remaining emulation, we get speedups of ≈60% (full build), ≈70% (median TU), and ≈80% (largest TU).
≈25% (full build), ≈29% (median TU), and ≈41% (largest TU) of this speedup came from Visual Studio's profile-guided optimization, with no changes to the MS-DOS Player codebase.
The effects of removing cycle counting are the biggest surprise. Between ≈17% and ≈23%, just for removing one subtraction per emulated instruction? Turns out that in the absence of a "target cycle amount" setting, the x86 emulation loop previously ran for only a single cycle. This caused the PIC check to run after every instruction, followed by PIT, serial I/O, keyboard, mouse, and CRTC update code every millisecond. Without cycle counting, the x86 loop actually keeps running until a CPU exception is raised or the emulated process terminates, skipping the hardware code during the vast majority of the program's execution time.
While Takeda Toshiya's changes in the 2024-06-27 build completely throw out the cycle counter and clean up process termination, they also reintroduce the hardware updates that made up the majority of the cycle removal speedup. This explains the results we're getting: The small speedup for full rebuilds is too insignificant to bother with and might even fall within a statistical margin of error, but the build slows down more and more the longer the emulated process runs. Compiling and linking YuugenMagan takes a whole 14% longer on generic builds, and ≈9-12% longer on PGO builds. I did another in-between test that just removed the x86 loop from the cycle removal version, and got exactly the same numbers. This just goes to show how much removing two writes to a fixed memory address per emulated instruction actually matters. Let's not merge back this one, and stay on top of 2024-06-24 for the time being.
The risky optimizations of ignoring segment limits and speeding up 32-bit segment+offset pointer load instructions could yield a further speedup. However, most of these changes boil down to removing branches that would never be taken when emulating correct x86 code. Consequently, these branches get recorded as unlikely during PGO training, which then causes the profile-guided rebuild to rearrange the instructions on these branches in a way that favors the common case, leaving the rest of their effective removal to your CPU's branch predictor. As such, the 10%-15% speedup we can observe in generic builds collapses down to 2%-6% in PGO builds. At this rate and with these absolute durations, it's not worth it to maintain what's strictly a more inaccurate fork of Neko Project 21/W's x86 core.
The redundant header inclusions afforded by #include guards do in fact have a measurable performance cost on Turbo C++ 4.0J, slowing down compile times by 5%.
But how does this compare to DOSBox-X's dynamic core? Dynamic recompilers need some kind of cache to ensure that every block of original ASM gets recompiled only once, which gives them an advantage in long-running processes after the initial warmup. As a result, DOSBox-X compiles and links YuugenMagan in , ≈92% faster than even our optimized MS-DOS Player build. That percentage resembles the slowdown we were initially getting when comparing full rebuilds between DOSBox-X and MS-DOS Player, as if we hadn't optimized anything.
On paper, this would mean that DOSBox-X barely lost any of its huge advantage when it comes to single-threaded compile+link performance. In practice, though, this metric is supposed to measure a typical decompilation or modding workflow that focuses on repeatedly editing a single file. Thus, a more appropriate comparison would also have to add the aforementioned constant 28,130 syscalls that my old build system required to detect that this is the one file/binary that needs to be recompiled/relinked. The video at the top of this blog post happens to capture the best time () I got for the detection process on DOSBox-X. This is almost as slow as the compilation and linking itself, and would have only gotten slower as we continue decompiling the rest of the games. Tup, on the other hand, performs its filesystem scan in a near-constant , matching the claim in Section 4.7 of its paper, and thus shrinking the performance difference to ≈14% after all. Sure, merging the dynamic core would have been even better (contribution-ideas, anyone?), but this is good enough for now.
Just like with Tup, I've also placed this optimized binary directly into the ReC98 repo and added the specific build instructions to the GitHub release page.
I do have more far-reaching ideas for further optimizing Neko Project 21/W's x86 core for this specific case of repeated switches between Real Mode and Protected Mode while still retaining the interpreted nature of this core, but these already strained the budget enough.
The perhaps more important remaining bottleneck, however, is hiding in the actual DOS emulation. Right now, a Tup-driven full rebuild spawns a total of 361 MS-DOS Player processes, which means that we're booting an emulated DOS 361 times. This isn't as bad as it sounds, as "booting DOS" basically just involves initializing a bunch of internal DOS structures in conventional memory to meaningful values. However, these structures also include a few environment variables like PATH, APPEND, or TEMP/TMP, which MS-DOS Player seamlessly integrates by translating them from their value on the Windows host system to the DOS 8.3 format. This could be one of the main reasons why MS-DOS Player is a native Windows program rather than being cross-platform:
On Windows, this path translation is as simple as calling GetShortPathNameA(), which returns a unique 8.3 name for every component along the path.
Also, drive letters are an integralpart of the DOS INT 21h API, and Windows still uses them as well.
However, the NT kernel doesn't actually use drive letters either, and views them as just a legacy abstraction over its reality of volume GUIDs. Converting paths back and forth between these two views therefore requires it to communicate with a
mount point manager service, which can coincidentally also be observed in debug builds of Tup.
As a result, calling any path-retrieving API is a surprisingly expensive operation on modern Windows. When running a small sprite through our 📝 sprite converter, MS-DOS Player's boot process makes up 56% of the runtime, with 64% of that boot time (or 36% of the entire runtime) being spent on path translation. The actual x86 emulation to run the program only takes up 6.5% of the runtime, with the remaining 37.5% spent on initializing the multithreaded C++ runtime.
But then again, the truly optimal solution would not involve MS-DOS Player at all. If you followed general video game hacking news in May, you'll probably remember the N64 community putting the concept of statically recompiled game ports on the map. In case you're wondering where this seemingly sudden innovation came from and whether a reverse-engineered decompilation project like ReC98 is obsolete now, I wrote a new FAQ entry about why this hype, although justified, is at least in part misguided. tl;dr: None of this can be meaningfully applied to PC-98 games at the moment.
On the other hand, recompiling our compiler would not only be a reasonable thing to attempt, but exactly the kind of problem that recompilation solves best. A 16-bit command-line tool has none of the pesky hardware factors that drag down the usefulness of recompilations when it comes to game ports, and a recompiled port could run even faster than it would on 32-bit Windows. Sure, it's not as flashy as a recompiled game, but if we got a few generous backers, it would still be a great investment into improving the state of static x86 recompilation by simply having another open-source project in that space. Not to mention that it would be a great foundation for improving Turbo C++ 4.0J's code generation and optimizations, which would allow us to simplify lots of awkward pieces of ZUN code… 🤩
That takes care of building ReC98 on 64-bit platforms, but what about the 32-bit ones we used to support? The previous split of the build process into a Tup-driven 32-bit part and a Makefile-driven 16-bit part sure was awkward and I'm glad it's gone, but it did give you the choice between 1) emulating the 16-bit part or 2) running both parts natively on 32-bit Windows. While Tup's upstream Windows builds are 64-bit-only, it made sense to 📝 compile a custom 32-bit version and thus turn any 32-bit Windows ≥Vista into the perfect build platform for ReC98. Older Windows versions that can't run Tup had to build the 32-bit part using a separately maintained dumb batch script created by tup generate, but again, due to Make being trash, they were fully rebuilding the entire codebase every time anyway.
Driving the entire build via Tup changes all of that. Now, it makes little sense to continue using 32-bit Tup:
We need to DLL-inject into a 64-bit MS-DOS Player. Sure, we could compile a 32-bit build of MS-DOS Player, but why would we? If we look at current marketshares, nobody runs 32-bit Windows anymore, not even by accident. If you run 32-bit Windows in 2024, it's because you know what you're doing and made a conscious choice for the niche use case of natively running DOS programs. Emulating them defeats the whole point of setting up this environment to begin with.
It would make sense if Tup could inject into DOS programs, but it can't.
Also, as we're going to see later, requiring Windows ≥Vista goes in the opposite direction of what we want for a 32-bit build. The earlier the Windows version, the better it is at running native DOS tools.
This means that we could now only support 32-bit Windows via an even larger tup generated batch file. We'd have to move the MS-DOS Player prefix of the respective command lines into an environment variable to make Tup use the same rules for both itself and the batch file, but the result seems to work…
…but it's really slow, especially on Windows 9x. 🐌 If we look back at the theory behind my previous custom build system, we can already tell why: Efficiently building ReC98 requires a completely different approach depending on whether you're running a typical modern multi-core 64-bit system or a vintage single-core 32-bit system. On the former, you'd want to parallelize the slow emulation as much as you can, so you maximize the amount of TCC processes to keep all CPU cores as busy as possible. But on the latter, you'd want the exact opposite – there, the biggest annoyance is the repeated startup and shutdown of the VDM, TCC, and its DOS extender, so you want to continue batching translation units into as few TCC processes as possible.
CMake fans will probably feel vindicated now, thinking "that sounds exactly like you need a meta build system 🤪". Leaving aside the fact that the output vomited by all of CMake's Makefile generators is a disgusting monstrosity that's far removed from addressing any performance concerns, we sure could solve this problem by adding another layer of abstraction. But then, I'd have to rewrite my working Lua script into either C++ or (heaven forbid) Batch, which are the only options we'd have for bootstrapping without adding any further dependencies, and I really wouldn't want to do that. Alternatively, we could fork Tup and modify tup generate to rewrite the low-level build rules that end up in Tup's database.
But why should we go for any of these if the Lua script already describes the build in a high-level declarative way? The most appropriate place for transforming the build rules is the Lua script itself…
… if there wasn't the slight problem of Tup forbidding file writes from Lua. 🥲 Presumably, this limitation exists because there is no way of replicating these writes in a tup generated dumb shell script, and it does make sense from that point of view.
But wait, printing to stdout or stderr works, and we always invoke Tup from a batch file anyway. You can now tell where this is going. Hey, exfiltrating commands from a build script to the build system via standard I/O streams works for Rust's Cargo too!
Just like Cargo, we want to add a sufficiently unique prefix to every line of the generated batch script to distinguish it from Tup's other output. Since Tup only reruns the Lua script – and would therefore print the batch file – if the script changed between the previous and current build run, we only want to overwrite the batch file if we got one or more lines. Getting all of this to work wasn't all too easy; we're once again entering the more awful parts of Batch syntax here, which apparently are so terrible that Wine doesn't even bother to correctly implement parts of it. 😩
Most importantly, we don't really want to redirect any of Tup's standard I/O streams. Redirecting stdout disables console output coloring and the pretty progress bar at the bottom, and looping over stderr instead of stdout in Batch is incredibly awkward. Ideally, we'd run a second Tup process with a sub-command that would just evaluate the Lua script if it changed - and fortunately, tup parse does exactly that. 😌
In the end, the optimally fast and ERRORLEVEL-preserving solution involves two temporary files. But since creating files between two Tup runs causes it to reparse the Lua code, which would print the batch file to the unfiltered stdout, we have to hide these temporary files from Tup by placing them into its .tup/ database directory. 🤪
On a more positive note, programmatically generating batches from single-file TCC rules turned out to be a great idea. Since the Lua code maps command-line flags to arrays of input files, it can also batch across binaries, surpassing my old system in this regard. This works especially well on the debloated and anniversary branches, which replace ZUN's little command-line flag inconsistencies with a single set of good optimization flags that every translation unit is compiled with.
Time to fire up some VMs then… only to see the build failing on Windows 9x with multiple unhelpful Bad command or file name errors. Clearly, the long echo lines that write our response files run up against some length limit in command.com and need to be split into multiple ones. Windows 9x's limit is larger than the 127 characters of DOS, that's for sure, and the exact number should just be one search away…
…except that it's not the 1024 characters recounted in a surviving newsgroup post. Sure, lines are truncated to 1023 bytes and that off-by-one error is no big deal in this context, but that's not the whole story:
: This not unrealistic command line is 137 bytes long and fails on Windows 9x?!
> echo -DA=1 2 3 a/b/c/d/1 a/b/c/d/2 a/b/c/d/3 a/b/c/d/4 a/b/c/d/5 a/b/c/d/6 a/b/c/d/7 a/b/c/d/8 a/b/c/d/9 a/b/c/d/10 a/b/c/d/11 a/b/c/d/12
Bad command or file name
Wait, what, something about / being the SWITCHAR? And not even just that…
: Down to 132 bytes… and 32 "assignments"?
> echo a=0 b=1 c=2 d=3 e=4 f=5 g=6 h=7 i=8 j=9 k=0 l=1 m=2 n=3 o=4 p=5 q=6 r=7 s=8 t=9 u=0 v=1 w=2 x=3 y=4 z=5 a=0 b=1 c=2 d=3 e=4 f=5
Bad command or file name
And what's perhaps the worst example:
: 64 slashes. Works on DOS, works on `cmd.exe`, fails on 9x.
> echo ////////////////////////////////////////////////////////////////
Bad command or file name
My complete set of test cases: 2024-07-09-Win9x-batch-tokenizer-tests.bat
So, time to load command.com into DOSBox-X's debugger and step through some code. 🤷 The earliest NT-based Windows versions were ported to a variety of CPUs and therefore received the then-all-new cmd.exe shell written in C, whereas Windows 9x's command.com was still built on top of the dense hand-written ASM code that originated in the very first DOS versions. Fortunately though, Microsoft open-sourced one of the later DOS versions in April. This made it somewhat easier to cross-reference the disassembly even though the Windows 9x version significantly diverged in the parts we're interested in.
And indeed: After truncating to 1023 bytes and parsing out any redirectors, each line is split into tokens around whitespace and = signs and before every occurrence of the SWITCHAR. These tokens are written into a statically allocated 64-element array, and once the code tries to write the 65th element, we get the Bad command or file name error instead.
#
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
String
echo
-DA
1
2
3
a
/B
/C
/D
/1
a
/B
/C
/D
/2
Switch flag
🚩
🚩
🚩
🚩
🚩
🚩
🚩
🚩
The first few elements of command.com's internal argument array after calling the Windows 9x equivalent of parseline with my initial example string. Note how all the "switches" got capitalized and annotated with a flag, whereas the = sign no longer appears in either string or flag form.
Needless to say, this makes no sense. Both DOS and Windows pass command lines as a single string to newly created processes, and since this tokenization is lossy, command.com will just have to pass the original string anyway. If your shell wants to handle tokenization at a central place, it should happen after it decided that the command matches a builtin that can actually make use of a pointer to the resulting token array – or better yet, as the first call of each builtin's code. Doing it before is patently ridiculous.
I don't know what's worse – the fact that Windows 9x blindly grinds each batch line through this tokenizer, or the fact that no documentation of this behavior has survived on today's Internet, if any even ever existed. The closest thing I found was this page that doesn't exist anymore, and it also just contains a mere hint rather than a clear description of the issue. Even the usual Batch experts who document everything else seem to have a blind spot when it comes to this specific issue. As do emulators: DOSBox and FreeDOS only reimplement the sane DOS versions of command.com, and Wine only reimplements cmd.exe.
Oh well. 71 lines of Lua later, the resulting batch file does in fact work everywhere:
The clear performance winner at 11.15 seconds after the initial tool check, though sadly bottlenecked by strangely long TASM32 startup times. As for TCC though, even this performance is the slowest a recompiled port would be. Modern compiler optimizations are probably going to shave off another second or two, and implementing support for #pragma once into the recompiled code will get us the aforementioned 5% on top.
If you run this on VirtualBox on modern Windows, make sure to disable Hyper-V to avoid the slower snail execution mode. 🐢
Building in Windows XP under Hyper-V exchanges Windows 98's slow TASM32 startup times for slightly slower DOS performance, resulting in a still decent 13.4 seconds.
29.5 seconds?! Surely something is getting emulated here. And this is the best time I randomly got; my initial preview recording took 55 seconds which is closer to DOSBox-X's dynamic core than it is to Windows 9x. Given how poorly 32-bit Windows 10 performs, Microsoft should have probably discontinued 32-bit Windows after 8 already. If any 16-bit program you could possibly want to run is either too slow or likely to exhibit other compatibility issues (📝 Shuusou Gyoku, anyone?), the existence of 32-bit Windows 10 is nothing but a maintenance burden. Especially because Windows 10 simultaneously overhauled the console subsystem, which is bound to cause compatibility issues anyway. It sure did for me back in 2019 when I tried to get my build system to work…
But wait, there's more! The codebase now compiles on all 32-bit Windows systems I've tested, and yields binaries that are equivalent to ZUN's… except on 32-bit Windows 10. 🙄 Suddenly, we're facing the exact same batched compilation bug from my custom build system again, with REIIDEN.EXE being 16 bytes larger than it's supposed to be.
Looks like I have to look into that issue after all, but figuring out the exact cause by debugging TCC would take ages again. Thankfully, trial and error quickly revealed a functioning workaround: Separating translation unit filenames in the response file with two spaces rather than one. Really, I couldn't make this up. This is the most ridiculous workaround for a bug I've encountered in a long time.
The TCC response file generation code for all current decompiled TH04 code, split into multiple echo calls based on the Windows 9x batch tokenizer rules and with double spaces between each parameter for added "safety". Would this also have been the solution for the batched compilation bugs I was experiencing with my old build system in DOSBox? I suddenly was unable to reproduce these bugs, so we won't know for the time being…
Hopefully, you've now got the impression that supporting any kind of 32-bit Windows build is way more of a liability than an asset these days, at least for this specific project. "Real hardware", "motivating a TCC recompilation", and "not dropping previous features" really were the only reasons for putting up with the sheer jank and testing effort I had to go through. And I wouldn't even be surprised if real-hardware developers told me that the first reason doesn't actually hold up because compiling ReC98 on actual PC-98 hardware is slow enough that they'd rather compile it on their main machine and then transfer the binaries over some kind of network connection.
I guess it also made for some mildly interesting blog content, but this was definitely the last time I bothered with such a wide variety of Windows versions without being explicitly funded to do so. If I ever get to recompile TCC, it will be 64-bit only by default as well.
Instead, let's have a tier list of supported build platforms that clearly defines what I am maintaining, with just the most convincing 32-bit Windows version in Tier 1. Initially, that was supposed to be Windows 98 SE due to its superior performance, but that's just unreasonable if key parts of the OS remain undocumented and make no sense. So, XP it is.
*nix fans will probably once again be disappointed to see their preferred OS in Tier 2. But at least, all we'd need for that to move up to Tier 1 is a CI configuration, contributed either via funding me or sending a PR. (Look, even more contribution-ideas!)
Getting rid of the Wine requirement for a fully cross-platform build process wouldn't be too unrealistic either, but would require us to make a few quality decisions, as usual:
Do we run the DOS tools by creating a cross-platform MS-DOS Player fork, or do we statically recompile them?
Do we replace 32-bit Windows TASM with the 16-bit DOS TASM.EXE or TASMX.EXE, which we then either run through our forked MS-DOS Player or recompile? This would further slow down the build and require us to get rid of these nice long non-8.3 filenames… 😕 I'd only recommend this after the looming librarization of ZUN's master.lib fork is completed.
Or do we try migrating to JWasm again? As an open-source assembler that aims for MASM compatibility, it's the closest we can get to TASM, but it's not a drop-in replacement by any means. I already tried in late 2014, but encountered too many issues and quickly abandoned the idea. Maybe it works better now that we have less ASM? In any case, this migration would only get easier the less ASM code we have remaining in the codebase as we get closer to the 100% finalization mark.
Y'know what I think would be the best idea for right now, though? Savoring this new build system and spending an extended amount of time doing actual decompilation or modding for a change.
Now that even full rebuilds are decently fast, let's make use of that productivity boost by doing some urgent and far-reaching code cleanup that touches almost every single C++ source file. The most immediately annoying quirk of this codebase was the silly way each translation unit #included the headers it needed. Many years ago, I measured that repeatedly including the same header did significantly impact Turbo C++ 4.0J's compilation times, regardless of any include guards inside. As a consequence of this discovery, I slightly overreacted and decided to just not use any include guards, ever. After all, this emulated build process is slow enough, and we don't want it to needlessly slow down even more! This way, redundantly including any file that adds more than just a few #define macros won't even compile, throwing lots of Multiple definition errors.
Consequently, the headers themselves #included almost nothing. Starting a new translation unit therefore always involved figuring and spelling out the transitive dependencies of the headers the new unit actually wants to use, in a short trial-and-error process. While not too bad by itself, this was bound to become quite counterproductive once we get closer to porting these games: If some inlined function in a header needed access to, let's say, PC-98-specific I/O ports as an implementation detail, the header would have externalized this dependency to the top-level translation unit, which in turn made that that unit appear to contain PC-98-native code even if the unit's code itself was perfectly portable.
But once we start making some of these implicit transitive dependencies optional, it all stops being justifiable. Sometimes, a.hpp declared things that required declarations from b.hpp but these things are used so rarely that it didn't justify adding #include "b.hpp" to all translation units that #include "a.hpp". So how about conditionally declaring these things based on previously #included headers?
#if (defined(SUBPIXEL_HPP) && defined(PLANAR_H))
// Sets the [tile_ring] tile at (x, y) to the given VRAM offset.
void tile_ring_set_vo(subpixel_t x, subpixel_t y, vram_offset_t image_vo);
#endif
You can maybe do this in a project that consistently sorts the #include lists in every translation unit… err, no, don't do this, ever, it's awful. Just separate that declaration out into another header.
Now that we've measured that the sane alternative of include guards comes with a performance cost of just 5% and we've further reduced its effective impact by parallelizing the build, it's worth it to take that cost in exchange for a tidy codebase without such surprises. From now on, every header file will #include its own dependencies and be a valid translation unit that must compile on its own without errors. In turn, this allows us to remove at least 1,000 #include of transitive dependencies from .cpp files. 🗑️
However, that 5% number was only measured after I reduced these redundant #includes to their absolute minimum. So it still makes sense to only add include guards where they are absolutely necessary – i.e., transitively dependent headers included from more than one other file – and continue to (ab)use the Multiple definition compiler errors as a way of communicating "you're probably #including too many headers, try removing a few". Certainly a less annoying error than Undefined symbol.
Since all of this went way over the 7-push mark, we've got some small bits of RE and PI work to round it all out. The .REC loader in TH04 and TH05 is completely unremarkable, but I've got at least a bit to say about TH02's High Score menu. I already decompiled MAINE.EXE's post-Staff Roll variant in 2015, so we were only missing the almost identical MAIN.EXE variant shown after a Game Over or when quitting out of the game. The two variants are similar enough that it mostly needed just a small bit of work to bring my old 2015 code up to current standards, and allowed me to quickly push TH02 over the 40% RE mark.
Functionally, the two variants only differ in two assignments, but ZUN once again chose to copy-paste the entire code to handle them. This was one of ZUN's better copy-pasting jobs though – and honestly, I can't even imagine how you would mess up a menu that's entirely rendered on the PC-98's text RAM. It almost makes you wonder whether ZUN actually used the same #if ENDING preprocessor branching that my decompilation uses… until the visual inconsistencies in the alignment of the place numbers and the and labels clearly give it away as copy-pasted:
Next up: Starting the big Seihou summer! Fortunately, waiting two more months was worth it: In mid-June, Microsoft released a preview version of Visual Studio that, in response to my bug report, finally, finally makes C++ standard library modules fully usable. Let's clean up that codebase for real, and put this game into a window.
📝 Over two years since the previous largest delivery, we've now got a new record in every regard: 12 pushes across 5 repos, 215 commits, and a blog post with over 14,000 words and 48 pieces of media. 😱 Who would have thought that the superficially simple task of putting SC-88Pro recordings into Shuusou Gyoku would actually mainly focus on deep research into the underlying MIDI files? I don't typically cover much music-related content because it's a non-issue as far as PC-98 Touhou code is concerned, so it's quite fitting how extensive this one turned out. So here we go, the result of virtually unlimited funding and patience:
So where's the controversy? Romantique Tp obviously made the best and most careful real-hardware SC-88Pro recordings of all of ZUN's old MIDIs, including the original (OST) and arranged (AST) soundtrack of Shuusou Gyoku, right? Surely all I have to do now is to cut them into seamless loops to save a bit of disk space, and then put them into the game? Let's start at the end of the track list with the name registration theme, since it's light on instruments and has an obvious loop point that will be easy to spot in the waveform. But, um… wait a moment, that very first drum note comes a bit late, doesn't it?
At a notated tempo of 96 BPM, these first four beats should take exactly 2.5 seconds, which they do in this seamlessly looping softsynth rendering.
That's… not quite the accuracy and perfection I was expecting. But I think I know what we're seeing and hearing there. Let's look at the first few MIDI events on the drum channel:
Delta Pulse Beat Channel Event
+540 960 2:000 1 Controller { CC 0, value 0 }
+0 960 2:000 1 Controller { CC 32, value 0 }
+0 960 2:000 1 ProgramChange { 37 }
[…]
+0 960 2:000 2 Controller { CC 0, value 0 }
+0 960 2:000 2 Controller { CC 32, value 0 }
+0 960 2:000 2 ProgramChange { 19 }
[…]
+0 960 2:000 3 Controller { CC 0, value 0 }
+0 960 2:000 3 Controller { CC 32, value 0 }
+0 960 2:000 3 ProgramChange { 6 }
[…]
+0 960 2:000 4 Controller { CC 0, value 0 }
+0 960 2:000 4 Controller { CC 32, value 0 }
+0 960 2:000 4 ProgramChange { 2 }
[…]
Also, the fact that GS doesn't put its drums on a non-general voice bank and instead relies on external channel configuration to differentiate drums from pitched instruments is making this Yamaha kid uncontrollably furious. 🤬
Yup. That's the sound of a vintage hardware synth being slow and taking a two-digit number of milliseconds to process a barrage of simultaneous Program Change messages, playing a MIDI file that doesn't take this reality into account and expects program changes to happen instantly.
I can only speak from my own experience of writing MIDIs for hardware synths here, but having the first note displaced by 50 ms is very much not the way a composer would have intended the music to be heard if the note is clearly notated to occur on the beat. If you had told me about such an issue when playing one of my MIDIs on a certain synth, I would have thanked you for the bug report! And I would have promptly released a fixed version of the MIDI with the Program Change events moved back by a beat or two. In the case of Shuusou Gyoku's MIDIs, this wouldn't even have added any additional delay in-game, as all of these files already start with at least one beat of leading silence to make room for setting Roland-specific synth parameters.
OK, but that's just a single isolated bass drum hit. If we wanted to, we could even fix this issue ourselves by splicing the same note from around the loop end point. Maybe this is just an isolated case and the rest of Romantique Tp's recordings are fine? Well…
By the way, this seamless audio player is what consumed most of the two website pushes this time. The rest went to the slightly redesigned main page, whose progress bars now use the cap bar style and the GitHub badge colors.
This one is even worse. Here, the delay is so long relative to the tempo of the piece that the intended five drum hits pretty much turn into four.
This type of issue doesn't even have to be isolated to the very beginning of a piece. A few of the tracks in both the OST and AST start with an anacrusis on just one or two channels and leave the Program Change event barrage at the beginning of the first full measure. In 幻想科学 ~ Doll's Phantom for example, this creates a flam-like glitch where the bass on channel 2 is pretty much on time, but the crash hit on channel 10 only follows 50 ms later, after the SC-88Pro took its sweet time to process all the Program Change events on the channels between:
This is from the arranged soundtrack for a change. In that one, ZUN at least fixed the issue in the final three MIDIs (シルクロードアリス, 魔女達の舞踏会, and 二色蓮花蝶 ~ Ancients) that closed out this rearranging project in May 2001, which spread out their per-channel setup events over at least a single measure before playing any note.
Sure, all of this is barely noticeable in casual listening, but very noticeable if you're the one who now has to cut these recordings into seamless loops. And these are just the most obvious timing issues that can be easily pinpointed and documented – the actual worst aspects are all the minor tempo and timing fluctuations throughout most of the pieces. With recordings that deviate ever so slightly from the tempo defined in the MIDI files, you can no longer rely on mathematically exact sample positions when cutting loops. Even if those positions do work out from time to time, there'd pretty much always be a discontinuity in the waveform at both ends of the loop, manifesting as a clearly audible click. In the end, the only way of finding good loop points in existing recordings involves straining your ears and listening very, very closely to avoid any audible glitches. 😩
But if you've taken a look at the second tabs in the clips above, you will have noticed that we don't necessarily have to be stuck with recordings from real hardware. In late 2015, Roland released Sound Canvas VA, a VST plugin that emulates the classic core of Roland's old Sound Canvas lineup, including the SC-88Pro. As long as we run such a software synthesizer through a quality VST host, a purely software-based solution should be way superior for recording looped BGM:
By moving from real-time recording to an offline rendering paradigm, we get perfectly accurate note timing, as it no longer matters how long the synth takes to produce each output sample.
We stay entirely in the digital realm instead of going from digital (SC-88Pro) to analog (RCA cable) to digital (line-in recording) again, removing any chance for noise or distortion to ruin audio quality.
We get to directly render at 44,100 Hz instead of being limited to the 32,000 Hz signal coming out of the SC-88Pro's DAC. This can be easily noticed in the half-speed video above, whose SCVA version retains significantly more sibilant high-frequency content compared to the more muffled sound of Romantique Tp's recording.
Doing that also makes it feasible to preserve loudness differences between the pieces of a soundtrack instead of eradicating them by normalizing the volume of each individual track to the digital maximum.
Finally, it's much more time-efficient. We simply hit foobar2000's Convert button and get all MIDIs rendered within a few seconds each, instead of having to wait the entire length of a piece.
Any drawbacks? For our use case, all of them are found in the abysmal software quality of everything around the synth engine. As it's typical for the VST industry, Sound Canvas VA is excessively DRM'd – it takes multiple seconds to start up, and even then only allows a single process to run at any given time, immediately quitting every process beyond the first one with a misleading Parameter File1 Read Error message box. I totally believe anyone who claims that this makes SCVA more annoying than real hardware when composing new music. Retro gamers also dislike how Roland themselves no longer sells the 32-bit builds they used to offer for the first few versions. These old versions are now exclusively available through resellers, or on the seven seas.
But as far as the SC-88Pro emulation is concerned, there don't seem to be any technical reasons against it. There is a long thread over at VOGONS discussing all sorts of issues, but you have to dig quite deep to find any clear descriptions of bugs in SCVA's synth engine. Everything I found either only applies to the SC-55 emulation and not the SC-88Pro, was fixed by Roland in the meantime, or turned out to be a fixable bug in a MIDI file.
But wait, we've already heard one obvious difference between the real SC-88Pro and Sound Canvas VA. Let's listen to the very first clip again:
Ha! You can clearly hear a panning echo in the real-hardware recording that is missing from the Sound Canvas VA rendering. That's an obvious case of a core system effect not being reproduced correctly. If even that's undeniably broken, who knows which other subtle bugs SCVA suffers from, right? Case closed, Romantique Tp was right all along, SCVA is trash, real hardware reigns supreme
Actually, let's look closer into this one. Panning delay effects like this are typically reverb-related, but General MIDI only specifies a single controller to specify the per-channel reverb level from 0 to 127. Any specific characteristics of the reverb therefore have to be configured using vendor-specific system-exclusive messages, or SysEx for short.
So it's down to one of the four SysEx messages at the beginning of the MIDI file:
Since these byte strings represent Roland-specific instructions, we can't learn anything from a raw MIDI event dump alone here. No problem though, let's just load these files into some old MIDI sequencer that targeted Roland synths, open its MIDI event list, and then they will be automatically decoded into a human-readable representation…
…or at least that's what I expected. In Yamaha land, XGworks has done that for Yamaha's own XG SysEx messages ever since 1997:
No configuration required. You can even edit the textual Value1 representation and XGworks parses it back into the closest supported value!
But for Roland synths, there's… nothing similar? Seriously? 😶 Roland fanboys, how do you even live?! I mean, they are quick to recommend the typical bloated and sluggish big-name DAWs that take up multiple gigabytes of disk space, but none of the ones I tried seemed to have this feature. They can't have possibly been flinging around raw byte strings for the past 33 years?!
But once you look more into today's MIDI community, it becomes clear that this is exactly what they've been doing. Why else would so many people use the word complicated to describe Roland SysEx, or call it an old school/cryptic communication protocol in hexadecimal format? The latter is particularly hilarious because if you removed the word cryptic, this might as well describe all of MIDI, not just SysEx. Everything about this is a tooling issue, and Yamaha showed how easily it could have been solved. Instead, we get Sound Canvas experts, who should know more about the ecosystem than I do, making the incredible mental leap from "my DAW doesn't decode or easily generate SysEx" to "SysEx is antiquated" to "please just lift up these settings to the VST level and into my proprietary DAW's proprietary project format, that would be so much better"…
Thankfully that's not entirely true. After some more digging and configuration, I found a somewhat workable solution involving a comparatively modern sequencer called Domino:
Open the File → Preferences menu and associate your MIDI output device with a module map. This makes sense for SysEx encoding/generation since it can limit the options in the UI to what's actually available on your target hardware, but is also required for selecting the respective SysEx map into Domino's SysEx decoder. There is no technical reason for this because SC-88Pro SysEx messages can be uniquely identified by the three vendor, device, and model ID bytes that every message starts with, but would be too easy and user-friendly. The perception of SysEx being a black art must be upheld at all costs.
I've kept the garbled text of the partial translation to emphasize the sheer amount of jank involved in this entire process.
Load a MIDI file and let Domino "analyze" it:
Strangely enough, this will take quite a while – on my system, this analysis step runs at a speed of roughly 4.25 KB/s of MIDI data. Yes, kilobytes.
Unfortunately, "control change macro restoration" also seems to mean that you don't get to see any raw bytes when selecting the respective MIDI track in the UI, but at least we get what we were looking for:
…for the most part?
Alright, that's something we can work with. The GS Reset message is something that every Roland GS MIDI should start with, but it's immediately followed by a message that Domino failed to decode? The two subsequent reverb parameters make sense, but panning delays typically have more parameters than just a reverb level and time.
That unknown SysEx message shares much of the same bytes with the decoded ones though. So let's do what we maybe should have done all along, return to caveman, and check the SC-88Pro manual:
The relevant section from page 194. We can see how the address and value correspond to bytes 5-7 and 8 in the SysEx messages. Byte 9 is a checksum and byte 10 signals the end of the message.
And that's where we find what this particular issue boils down to. The missing SysEx message is clearly intended to be a Reverb Macro command, whose value can range from 0 to 7 inclusive on the SC-88Pro, but ZUN tries to specify Reverb Macro #14h, or 20 in decimal. The SC-88Pro manual does not specify what happens if a SysEx message wants to write an invalid value to a valid address, which means that we've firmly entered the territory of undefined behavior. Edit (2024-03-10):Romantique Tp confirmed that the real SC-88Pro clamps these Reverb Macro IDs to the supported range of 0-7. Therefore, the appropriate course of action for guaranteeing the same sound on other Roland synths would be to fix the MIDI file and specify Reverb Macro #7 instead. But since this behavior remains technically undefined, we can still argue about ZUN's intention behind specifying the Reverb Macro like this:
Clearly, ZUN did want to specify a valid Reverb Macro, but made a typo when manually entering the SysEx byte string, as he was forced to do thanks to terrible tooling. He clearly liked the resulting sound though, so the track should still be preserved with the panning reverb intact.
Clearly, the typical behavior for MIDI synths is to ignore invalid and unsupported SysEx messages, because validating user input is an important characteristic of quality software. This is what SCVA does, and what we hear in its rendering is the default hall reverb with ZUN's level and time adjustments. Therefore, SCVA is right, and the fact that we get a panning delay on the real SC-88Pro is a bug in real hardware.
Clearly, ZUN did not care enough about the reverb to specify a valid Reverb Macro. Whether we get the default reverb or a panning delay is an irrelevant performance detail, and does intentionally not matter when it comes to the intended sound of this track – especially since these four SysEx messages are the full extent of Roland GS-specific sound design in this piece, and the rest of it only uses standard MIDI features.
In fact, 32 out of the 39 MIDIs across both of Shuusou Gyoku's soundtrack use this invalid Reverb Macro. The only ones that don't are
both versions of Gates' theme (天空アーミー), which use the equally invalid Reverb Macro #11,
both versions of Milia's theme (プリムローズシヴァ), which use Reverb Macro #0 (Room 1),
and, again, the three arranged MIDIs that ZUN released last (シルクロードアリス, 魔女達の舞踏会, and 二色蓮花蝶 ~ Ancients), which feature a more detailed effect setup with custom chorus and EQ settings. In the case of Reimu's theme, these settings are even commented within the MIDI file.
And that's where this quest seemed to end, until Romantique Tp themselves came in and suggested that I take a closer look at the GS Advanced Editor, or GSAE for short.
Make sure to connect a MIDI input device before starting GSAE, or it will silently crash immediately after this splash screen. At least it accepts any controller, so this might just be a bug instead of the typical user-hostile kind of hardware dongle DRM that is pervasive in today's synth industry. 1999 would seem a bit too early for that, thankfully.
I was aware of this tool, but hadn't initially considered it because it's always described as just a SysEx generator/encoder. In fact, the very existence of such a tool made no sense to me at first, and seemed to prove my point that the usability of GS SysEx was wholly inferior to what I was used to in Yamaha land. Like, why not build at least a tiny and stripped-down MIDI sequencer around this functionality that would allow you to insert SC-88Pro-specific messages at any point within a sequence, and not just the beginning? I can see the need for such a tool in today's world of closed-source DAWs where hardware MIDI modules are niche and retro and are only kept alive by a small community of enthusiasts. But why would its developers guarantee that MIDI composers would have to hop between programs even back in 1997? I can only imagine that they saw how every just slightly advanced MIDI sequencer or DAW back then already used its own project format instead of raw Standard MIDI Files, and assumed that composers would therefore be program-hopping anyway?
However, GSAE does support the import of settings from a MIDI file and features a SysEx history window that decodes every newly processed Roland SysEx byte string, which is all I was looking for. So let's throw in that same MIDI and…
That's the result of sending just the single F0 41 10 42 12 40 01 30 14 7B F7 message at the top.
Now that's some wild numbers. An equally invalid Reverb Character, and Reverb Level and Time values that even exceed their defined range of 0-127? Could it be that GSAE emulates the real-hardware response to invalid Reverb Macros here, and gives us the exact reverb setting we can hear in Romantique Tp's recording? This could even be the reason why GSAE is still used and recommended within today's Roland MIDI sequencing scene, and hasn't been supplanted by some more modern open-source tool written by the community.
In any case, these values have to come from somewhere, so let's reverse-engineer GSAE and figure out the logic behind them. Shoutout to IDR for being a great help with its automatic generation of IDC debug symbols for the Delphi standard library, and even including a few names of application-level widget class methods by reading Delphi-specific type information from the binary. This little sub-project made me also come around to appreciating Ghidra, whose decompiler and data type manager helped a lot and allowed me to find the relevant code section within just a few hours.
A~nd it turns out that the values all come from out-of-bounds accesses into arrays on the stack. If we combine 25, 235, and 132 back into a 32-bit value, we get 0x19EB84, which is the virtual address of the relevant function's stack frame base pointer.
But it gets even more hilarious: If you enable debug text output via Option → Other Options → SMF → Insert text events to setup measures and export these imported settings back into a MIDI file, GSAE not only retains these invalid Reverb Macro IDs, but stringifies them via a simple lookup into a hardcoded string pointer array, again without any bounds checks. The effects of this are roughly what you would expect:
Reverb Macro IDs between 8 and 27 simply insert wrong strings from adjacent string pointer arrays
Reverb Macro 28 crashes GSAE
Reverb Macro 64 causes GSAE to vomit 65,512 bytes of garbage into the MIDI file
In the end, we have Domino not decoding the Reverb Macro message, and GSAE, the premier SysEx tool for Roland synths, responding to it in even more undefined and clearly bugged ways than real hardware apparently does. That's two programs confirming that whatever ZUN intended was never supposed to work reliably. And while we still don't know exactly what these reverb parameters are supposed to be, these observations solve the mystery as far as I'm concerned, and solidify my personal opinion on the matter.
So what do we do now, and which version do we go with? Optimally, I'd offer both versions and turn this controversy into a personal choice so that everybody wins… and Ember2528 agreed and generously provided all the funding to make it happen. 💸
If you haven't picked your favorite yet, here are some final arguments:
The Romantique Tp recordings certainly have something going for them with their provenance of coming from real hardware, and the care that Romantique Tp put into manually recording every single track, warts and all. I wholeheartedly agree that preserving the raw sound of playing the MIDI files into the hardware without thinking about bugs or quirks is an important angle to take when it comes to preservation. It's good that these recordings exist – after all, you wouldn't know which musical elements you'd possibly be missing in an emulation if you have nothing to compare it to. Even the muffled sound in the half-speed clip above can be an argument in their favor, as the SC-88Pro's DAC operates at 32 kHz and you wouldn't expect any meaningful frequency content between 16,000 and 22,050 Hz to begin with. Any frequency content in that range that does remain in Romantique Tp's recording is simply 📝 rolled-off imaging noise added during the ADC's resampling process.
All this is why they are a definite improvement over kaorin's 2007 recordings of only the AST, which used to be the previous reference recordings within the community. Those had all of the same timing issues and more, in addition to being so excessively volume-boosted that 0.15% of the samples across the entire soundtrack ended up clipped. That's 6.25 seconds out of 68:39m being lost to pure digital noise.
Most importantly though: ZUN himself said that only the real SC-88Pro will play back these files as he intended them to sound. This quote is likely where the tagline of Romantique Tp's entire recording project came from in the first place:
> 全てのデエタはSC-88ProもしくはSC-8850(ロオランド社)にて最適に聴けるように調整してあります
> それ以外の音源でも、作者の意図した音ではない場合があります。
— ZUN on 東方幻想的音楽, his old MIDI page
However. ZUN is not exactly known for accurately and carefully preserving the legacy of his series, or really doing anything beyond parading his old games as unobtainable showpieces at conventions. With all the issues we've seen, preferring real hardware is ultimately just that: an angle, and a preference. This is why I disagree with the heavy and uncritical advertising that is mainly responsible for elevating the Romantique Tp recordings to their current reference status within the community, especially if at least half of the alleged superiority of real hardware is founded on undefined behavior that can easily be fixed in the MIDI files themselves if people only bothered to look.
Here's where I stand: MIDI files are digital sheet music first and foremost, not an inferior version of tracker modules where the samples are sold separately. As such, the specific synth a MIDI file was written for is merely a secondary property of the composition – and even more so if the MIDI file contains little to nothing in terms of sound design and mostly restricts itself to the basic feature set of General MIDI. In turn, synth quirks and bugs are not a defined part of the composition either, unless they are clearly annotated and documented in the file itself. And most importantly: If the MIDI file specifies a certain timing and a recording fails to reproduce that timing, then that recording is not an accurate representation of the MIDI file.
In that regard, Sound Canvas VA is not only the closest alternative to the real thing, as a few people in the MIDI and retrogaming scene do have to admit, but superior to the real thing. I'll gladly take clarity and perfect timing accuracy in exchange for minor differences in effects, especially if the MIDI file does not explicitly and correctly define said effects to begin with. If I want a panning delay as part of the reverb, I add the respective and correct SysEx message to define one – and if I don't, I do not care about the reverb. You might still get a panning delay on a certain synth, and you might even prefer how it sounds, but it's ultimately a rendering artifact and not a consciously intended part of the composition. In that way, it's similar to the individual flavor a musician adds to a performance of a piece of classical music.
And as far as the differences in frequency response and resonant filters are concerned: In Yamaha land, these are exactly the main distinguishing factors between vintage WF-192XG sound cards (resembling the real SC-88Pro in these characteristics) and the S-YXG50 softsynth (resembling SCVA). Once I found out about that softsynth and how much clearer it sounded in comparison, I sold that old PCI sound card soon after.
In the interest of preservation though, there's still one more unexplored solution that could be the ideal middle ground between the two approaches:
Play the MIDIs through a real-hardware SC-88Pro again
Capture the actually observed system-exclusive settings that fall within the synth's supported and documented ranges
Insert them back into the MIDI file, creating a new bugfixed version
Re-record that bugfixed version through Sound Canvas VA
Edit (2024-03-10): And since Romantique Tp has confirmed what exactly happens on real hardware, I'm going to do exactly that. These bugfixed Sound Canvas VA renderings will be a free bonus of the single next Shuusou Gyoku push, and will add another angle to the preservation of these soundtracks. In the meantime though, the Sound Canvas VA packs will sound like they do in the preview videos above.
Just to be clear: I'm not suggesting that Romantique Tp should have been the one to cut their recordings into loops, or even just the one who defined where the loop points are supposed to be. On the surface, this seems to be a non-issue, and you'd just pick a point wherever each track appears to loop, right? But with 39 MIDIs to cut and all the financial support from Ember2528, it made sense to also solve this problem more thoroughly, and algorithmically detect provably correct loop points for all of these files. Who knows, maybe we even find some surprises that make it all worth it?
This is the algorithm I came up with:
At a basic level, we loop over the list of MIDI events and return the earliest and longest subrange that is immediately followed by an identical copy.
MIDI players, however, need loop point definitions that use MIDI pulse units rather than event list indices. This is especially necessary for multi-track/SMF Type 1 sequences, which would otherwise require one loop start/end index pair per track, and then it still wouldn't work because some of the tracks might not even have an event at the loop start/end point. This requires the detection algorithm and the player to agree on how to map event indices to time points and back, and simply going for the first event of each pulse (i.e., any event with a nonzero delta time) makes the most sense here. In turn, we can skip any potential start or end events that have a delta time of 0, speeding up the algorithm significantly for typical compositions with a high degree of polyphony.
Naively considering just the raw MIDI events works for MIDI playback. But as soon as we want to cut a recording based on the detected loop points, we need to account for the fact that MIDI playback is inherently stateful. Each of the 16 channels at the protocol level features at least the 128 continuous controllers (CCs) with a 7-bit state, the 14-bit pitch bend controller, and the 7-bit instrument program value, in addition to the global tempo of the piece. As a result, two ranges of events might look identical, but can still sound differently if the events before the first range changed one piece of state which is then only touched again near the end of that range. This requires us to track the full MIDI state at both the start and end of a loop, and reject any potential loop that differs in these states:
In this example, a naive event-level scan would detect a loop between beats 3 and 6 as the same events are immediately repeated between beats 6 and 9. However, the piece starts with the first four notes at a channel volume of 50, which is only set to its later value of 100 on beat 5. Therefore, the actual loop ranges from beat 5 to 8. In turn, the piece needed to be at least 11 beats long to include the full second copy of the looped events and prove the loop as such.
This check can be a bit too strict in some cases, though. A channel might start with one of its CCs at a specific value but then change the same CC to a different value at a later point before playing the first note. In such a case, the detected loop would be delayed to the second CC change even though the initial CC value has no impact on the sound. By filtering these redundant CC changes, we get to move the loop start point of a few tracks (original 夢機械 ~ Innocent Power and arranged 魔法少女十字軍) back by a few seconds, to the position you'd expect.
Finally, we reject any overlong loops that themselves fully consist of multiple successive copies of the first N events.
Shuusou Gyoku's original MIDI files hide the original game's lack of MIDI looping by simply duplicating the looping sections enough times so that a typical player won't notice. The algorithm we have so far, however, would return a much longer loop if a MIDI file contains more than three successive copies of a looping section. The original version of ハーセルヴズ in particular repeats its 8 looping bars a total of 15 times before the MIDI ends, and this condition is necessary to detect the actual 8-bar loop instead of a 56-bar one.
Of course, this algorithm isn't perfect and won't work for every MIDI file out there. It doesn't consider things like differently ordered events within the same MIDI pulse, (non-)registered parameter numbers, or the effect that SysEx messages can have on the state of individual channels. The latter would require the general SysEx decoding logic that I would have liked to have for the research above… actually, let's add an issue and add the project to the order form. I'd really like to see a comprehensive open-source cross-vendor SysEx decoder library in my lifetime.
As for the implementation, I was happy to write some Rust again for a change, as it's a great fit for these standalone greenfield command-line tools that don't have to directly interact with the legacy C++ code bases that this project usually deals with. It's even better if the foundational functionality is not just available in a crate, but in four, with the community already having gone through multiple iterations to arrive at a tried and tested winner. Who knows, maybe I even get to rewrite this website in it one day? Just for the sheer meme value of doing so, of course.
I also enjoyed this a lot from a technical point of view:
You might think that Rust's typical safety guarantees don't matter for the problem at hand. But then you accidentally write -= instead of += for a u32 that starts out at 0, and Rust immediately panics instead of silently underflowing to u32::MAX. This must have saved me at least 5 minutes of debugging the resulting logic error.
As it turns out, my loop detection algorithm is embarrassingly parallel. You might initially think about it in a sequential way because we always want the earliest occurrence of the longest repeating section of MIDI events, which means that each new loop candidate further into the track has to be longer than the previous one. But since we always iterate over the entire MIDI, it makes perfect sense to divide and conquer the problem. Let's split the list of possible loop end points into equal chunks, scan them all in parallel for the earliest and longest loop within that chunk, and then pick the earliest and longest loop among those intermediate results as the final one. In Rust, you don't even have to think much about the chunks, as all of that can be easily done by replacing the iteration with Rayon's parallel fold and adding a reduce() with the same condition for the final step. This sped up the algorithm by exactly the number of cores in my system.
This algorithm works well for the long MIDI files of Shuusou Gyoku's OST that all contain multiple duplicates of their loop section, but it quickly reaches its limit with the AST. Following the classic two-loop + fade-out format, that soundtrack was meant to be played back in generic MIDI players, and not to actually be put back into the game in looped form. Since the loop algorithm did, in fact, find inconsistencies even in the OST, two copies of the apparent loop are sometimes not enough to prove cases where the actual loop ends much later than you think it does. In a few cases, it would be enough to simply remove all volume change events from the fade-out to prove the actual loop, but in others, the algorithm would need MIDI event data far past the end of the fade-out.
However, just giving up and not looping any of these tracks would be equally unfortunate. So how about shifting the question, from what's the best loop in this MIDI file to what's the best loop if the MIDI didn't fade out and instead repeated its apparent second loop a third time? As long as the detected loop in such a pre-processed file ends before the repeated range, it's still a valid loop in terms of the unmodified original.
Ideally, we want to do this pre-processing programmatically with the same Rust library instead of manually editing the MIDI. Many sequencers (and especially XGworks) apply significant changes to a MIDI file's internal structure when saving its internal representation back to a MIDI file, which might even mess with our loop algorithm. So it would be very nice to have a more trustworthy tool that applies only the edit we actually want, and perfectly retains the rest of the MIDI.
And that's how this sub-project turned into a small suite of command-line MIDI operations in the classic Unix filter/pipeline style: Each command reads a MIDI file from stdin, transforms it, and outputs text or the resulting MIDI file on stdout. This way, we gain maximum transparency and reproducibility as I can document the unique pre-processing steps for each AST track by simply providing the command lines. And sure, we're re-encoding and re-decoding the full MIDI sequence at every step along such a pipeline, but computers are fast, Rust and the midly library in particular are ⚡ blazingly fast ⚡, and the usability benefits of this pipeline model far outweigh any theoretical performance drops.
Here's the full list of commands that made it into the resulting mly tool:
cut: Extremely basic removal of MIDI events within a certain range.
dump: Dumps all MIDI events into a textual table. All event lists in this blog post are based on this output.
duration: Shows the duration of a MIDI file in pulses, beats, seconds, and PCM samples.
filter-note: Removes all Note On events within a certain range, retaining all other events. This allows us to generate separate intro and loop MIDIs, whose renderings we can then splice back into a single loopable waveform with no discontinuities, which is not guaranteed when rendering a single MIDI file. This provides the last missing piece needed for rendering perfect, sample-accurate loops through Sound Canvas VA.
loop-find: The loop detection algorithm described above.
loop-unfold: Duplicates MIDI events from a given point to the end of the track. A budget solution for the problem of creating synthetic loops – arbitrary copying of arbitrary subranges to arbitrary destinations would have been undeniably nicer, but also much more complex, and I didn't need that full flexibility for the task at hand.
smf0: Flattening multi-track/SMF Type 1 MIDI sequences into single-track/SMF Type 0 ones. Having this conversion as a distinct operation in our toolset allows other operations to exclusively support SMF Type 0 if a Type 1 implementation would either take significant additional effort or just duplicate the Type 0 flattening algorithm. This group of operations includes loop-find, cut, and even the real-time output for duration because tempo events can theoretically occur on any track.
This feature set should strike a good balance between not spending too much of the Shuusou Gyoku budget on tangential problems, but still offering a decent solution for the problem at hand. As a counterexample, the obvious killer feature – deserializing a dump back into a Standard MIDI File – would have gone way past the budget. While there are crates that free you from the need to write manual parsing code for basic data structures, they would instead require a lot of attribute boilerplate – and if the library that provided the structures doesn't already come with these attributes, you now have to duplicate all the structures, and convert back and forth between the original structures and your copies. Not to mention that we'd still have to write code for the high-level structure of the dump output…
If we put it all together, this is what we can do:
The best loop found in the raw MIDI file spans 4 events and 200 milliseconds. Clearly, this is not the loop we're looking for.
Let's cut off all events from the start of the fade-out to the end, do a loop-unfold copy of all events from the position during the apparent second loop that corresponds to where the fade-out started, and try looking for a loop in that modified MIDI.
The resulting loop is 1:31m long, which is exactly what we were hoping to find.
The note space loop represents the earliest possible event range with equivalent per-channel controller and pitch bend state at both ends. This loop is only appropriate for MIDI players, as its bounds can fall into the middle of notes that are played with a different channel state at the start and end of the loop. This is why it doesn't show any sample positions.
The recording space loop ensures that this doesn't happen. It's also always placed on a Note On event with non-zero velocity, which eases the splicing of separate filter-note recordings. This way, it's enough to remove leading silence from the loop part and mix it exactly at the indicated sample position.
The detected loop is also nowhere close to the cut point at beat 466, matching our condition for validity. All events within the loop came from ZUN's original composition, and the cut/loop-unfold combo merely provided the remaining 63% of events necessary to prove this loop as such.
So, where are these loop quirks that justify why some of these audio files are longer than you'd think they should be? Just listing them as text wouldn't really communicate just how minor these are. It would be much nicer to visualize them in a way that highlights the exact inconsistencies within a fixed range of MIDI measures. Screenshots of MIDI sequencer or DAW windows won't capture these aspects all too well because these programs are geared toward fine-grained editing of single tracks, not visualization of details across all channels.
REAPER's piano roll nicely snaps to a certain range, but good luck picking out the individual lines from the single volume lane at the bottom of the screen, or spotting a 7-point difference. Not to mention that CC #11 (Expression) makes up an equal part of a channel's final perceived volume, which is the metric we'd actually want to visualize.
Typical MIDI visualizers, however, are on the complete opposite end of the spectrum. In recent years, MIDI visualization has become synonymous with the typical Synthesia style of YouTube videos with a big keyboard at the bottom, note bars flying in from the top, and optional fancy effects once those notes hit the top of the keyboard. The Black MIDI community has been churning out tons of identically looking MIDI visualizers in recent years that mainly seem to differ in the programming language they're written in, and in how well they can cope with the blackest of black MIDIs.
Thankfully, most of these visualizers are open-source and have small and manageable codebases. The project with the most GitHub stars and the most generic name seemed to be the best starting point for hacking in the missing features, despite using GLSL shaders which I had no prior experience with. It was long overdue that I did something with GLSL though – it added a nice educational aspect to these hacks, and it still was easier than deciphering whatever the fastest and hyper-optimized Rust visualizer is doing.
Still, this visualizer needed a total of 18 small features and bugfixes to be actually usable for demonstrating Shuusou Gyoku's loop quirks. As such, these hacks turned into yet another tangential sub-project that could have easily consumed another two pushes if I cleaned up the code and published the result. But that would have really gone way past the budget for something that people might not even care about. So here's what we're going to do:
I've added this MIDI visualizer as a new goal to the order form. This goal is eligible for microtransactions, so you don't have to fund a full push to see the first changes committed and released.
The upstream project seems to have been abandoned recently, which is the perfect excuse for not even trying to merge in my sweeping changes with a series of pull requests. The code sure needs a lot of cleanup and deduplication, and especially a more build system-friendly way of embedding its shader source code.
Every backer who supports this goal with at least 0.1 pushes or microtransactions will get a Windows binary with my current hacked-in changes as a preview, immediately after the purchase. Shoutout to the MIT license for letting me do this 😛
As usual, once the code is done, the final cleaned-up version will be available for free for everyone, in both source code and binary release form.
Alright then! Here's how to read the visualizations:
The transparency of each note represents its velocity multiplied by the channel volume and expression. To spot volume inconsistencies, you'd compare the opacity of equivalent notes in the two ranges.
The X-axis of these visualizations uses linear/real time, so the width of each measure represents the exact time it takes to be played relative to the other measures in the visualized range. To spot tempo inconsistencies, you'd compare the distance between the bar lines.
Notes that are duplicated on two or more channels may be colored differently in the loop start and end views. These are rendering order inconsistencies and don't communicate anything about the MIDI.
Stage 1 theme (フォルスストロベリー), original and arranged version: The string and harmonica channels are slightly louder on the apparent first loop than on the others.
Apparent loop:
0:01m – 1:31m
Actual loop:
1:04m – 2:34m
Mei and Mai's theme (ディザストラスジェミニ), arranged version: The one and only quirk that's caused by different notes – the first loop has an E♭ on the slap bass channel in measure 32, but the second loop has a G♭ in the corresponding measure 72.
Apparent loop:
0:01m – 1:02m
Actual loop:
0:50m – 1:51m
Stage 3 theme (華の幻想 紅夢の宙), original and arranged version:
The trumpet channel starts out panned to the center of the stereo field (64), before being left-panned by 25% (48) at 1:04m, where it stays for the rest of the track.
Apparent loop:
0:01m – 1:29m
Actual loop:
1:04m – 2:32m
I didn't come up with a good way of visualizing panning in a 2D plane, so you have to trust your ears with this one.
Marie's theme (機械サーカス ~ Reverie), arranged version: Every apparent loop modulates up by a semitone 16 measures before it ends, and remains in that new key at the start of the next loop, so the piece technically doesn't loop at all. The original stays in G♯m throughout.
Stage 5 theme (カナベラルの夢幻少女), original version: The ritardando near the supposed end of the first loop drops from 145 BPM to 118 BPM, but only to 129 BPM in all further loops.
Apparent loop:
0:01m – 1:39m
Actual loop:
1:33m – 3:11m
Yup, that means that the intro part technically makes almost up the entire apparent loop. ZUN replaced the ritardando with instant tempo changes in the arranged version, which moves the loop to its expected place at the start of the track.
The loop start and end points are in the respective next measure past this range.
Stage 6 theme (アンティークテラー), arranged version: The string channel starts out with the maximum expression of 127, but then only goes up to 120 after some fading notes later in the piece, where it stays for the beginning of the second loop.
Apparent loop:
0:01m – 1:53m
Actual loop:
0:13m – 2:05m
Same here.
VIVIT-captured-'s first theme (夢機械 ~ Innocent Power), arranged version: Has a unique ending section that starts in Gm and then modulates through Em and Fm before it fades out on F♯m.
VIVIT-captured-'s second theme (幻想科学 ~ Doll's Phantom), original and arranged version: Another fade-related 127 vs. 120 expression inconsistency, this time on the orange square channel.
Apparent loop:
0:01m – 1:32m
Actual loop:
1:03m – 2:34m
VIVIT-captured-'s third theme (少女神性 ~ Pandora's Box), original and arranged version: Another tempo inconsistency: A slightly differently shaped ritardando before the bell tree hit in the supposed first loop.
Marisa's theme (魔女達の舞踏会), arranged version: Has a unique 8-bar ending section that is first played in Cm and then loops in C♯m while fading out.
Ending theme (ハーセルヴズ), arranged version: Probably the best-known one out of these, and I'm talking of course about the beautiful ending section. I'm making the executive decision to not loop this track in-game, and letting it fade to silence instead.
Before we package up these looped soundtracks, let's take a quick look at how they would be shown off in the Music Room. The Seihou Music Rooms carry over the per-channel keyboards from TH05, add the current per-channel volume, expression, and pan pot values, and top it off with a fake spectrum analyzer. All of these visualizations rely on MIDI data, and the Music Room would feel very dull and boring without them. Just look at Kioh Gyoku, whose Music Room basically turns into a still image in WAVE mode.
Retaining these visualizations even when playing waveform BGM was very important for me, and not just because it would make for a unique high-quality feature that would break new ground. It can also double as proof that the waveform versions are, in fact, in perfect sync with both the MIDIs they are based on, and, by extension, the respective stage scripts.
However, this would require the game to process the MIDIs and update the internal visualization state without simultaneously playing them back through the WinMM / MME / midiOut*() API. And just like graphics and text rendering, Shuusou Gyoku's original code came with zero architectural separation between platform-independent processing logic and platform-specific playback…
So I accidentally rewrote almost the entire MIDI code to achieve said separation. This also provided a great occasion to modernize this code and add some much-needed robustness for potential MIDI mods, while retaining the original code's approach of iterating over raw SMF byte streams. It might all have been very excessive for a delivery that was supposed to be just about waveform BGM support, but on the plus side, MIDI output is now portable to any other system's MIDI API as well.
Surprisingly though, it was Shuusou Gyoku's original MIDI timing that quickly turned out to be rather inaccurate, and not the waveforms. The exact numbers vary depending on the piece, but the game played back every MIDI about 1% slower than notated, adding about 2 or 3 seconds to their total playback time after 5 minutes. Tempo changes in particular were the biggest causes of desynchronizations with the waveforms…
To understand how this can happen to begin with, we have to look closer at how you're supposed to use the midiOut*() API. This API is as low-level as it gets, only covering the transmission of a single MIDI message to the selected output device right now. There is no concept of note timing at this low level, so it's completely up to the program to parse delta times and tempo change events out of the MIDI file and correctly time the calls to this API for each MIDI message. With all the code that runs between the API and the actual renderer of the synth for every single message, the resulting timing can only ever be an approximation of the MIDI file. This doesn't really matter for the timescales and polyphony levels of typical music because, again, computers are fast, but such an API is fundamentally unsuitable for accurately playing back even just a moderately complex million-note Black MIDI.
Shuusou Gyoku handles this required manual timing in the simplest possible way: It runs a MIDI processing function (Mid_Proc() in the code) at an interval of 10 ms, which processes and instantly sends out all MIDI events that have occurred at any point within the last 10 ms, maintaining merely their order. This explains not only why the original game incremented its MIDI TIMER by multiples of 10, but also the infamous missing drums when playing the soundtrack through the Microsoft GS Wavetable Synth:
ZUN reduced all drum notes to the minimum possible length allowed by the 480 PPQN pulse resolution of these MIDI files.
In regular music notation, this corresponds to 1/1920th notes.
While the exact real-time length in purely mathematical terms depends on the tempo of a piece, it only has to be ≥13 BPM for a 1/1920th note to be shorter than 10 ms.
Therefore, the higher the BPM, the higher the chance that both a drum note's Note On and Note Off messages are sent within the same call to Mid_Proc(), with the respective two midiOut*() API calls only being at best a two-digit number of microseconds apart.
So it only makes sense why cheap MIDI synths that don't even respond to reverb or release time messages completely drop any note with such a short length. After all, at a sampling rate of 44,100 Hz, a note would have to be at least 22.7 µs long to be represented by even a single PCM sample.
This also extends to the visualizations above, and was the reason why I chose to render all drum notes as fixed-size diamonds. Otherwise, they would barely be visible.
But while sending MIDI events in such quantized chunks might not be perfect, it can't be the cause behind multi-second playback slowdowns. Instead, this issue has to boil down to the way Shuusou Gyoku times each individual message, and specifically how it converts between MIDI pulse units and real-time (milli)seconds. pbg's original MIDI code chose to do this in an equally confusing and inaccurate way: it kept two counters that tracked the current MIDI pulse before and after the latest tempo change, used the value of the latter counter to decide which events to process, and only added the pulse equivalent of 10 ms to this counter at the end of Mid_Proc() in the then current tempo. The commit message for my rewritten algorithm details the problems with this approach using nice ASCII art in case you're interested, but in short, the main problem lies in how the single final addition can only consider a single tempo change within each call to Mid_Proc(). If a MIDI file contains tempo ramps with less than 10 ms between each different tempo, the original game would only use the last of these tempo values as the basis for converting the entire 10 ms back into MIDI pulses. Not to mention that maybe MIDI pulses aren't the best unit in a game that still 📝 treats the FPU as lava and doesn't use any fixed-point means of increasing the resolution of the 10 ms→pulse division either…
On the contrary, it's much more accurate to immediately convert every encountered MIDI delta time to a real-time quantity and use that unit for event timing, especially if we want to restrict ourselves to integer math. Signed 64-bit integers are enough to fit the product of the slowest possible MIDI tempo ((224 - 1) µs per quarter note) and the highest possible MIDI delta time (228 - 1) at nanosecond precision (103), with one bit to spare. Then, we arrive at a much simpler timing algorithm:
Each simultaneously playing track gets a next event timer, starting out at 0
When looking at the next event, add the converted nanosecond value of its delta time to this timer
Subtract the equivalent of 10 ms from each track's timer at the beginning of the processing function
As long as the timer is ≤0, process and send the next message
The additive nature of this timer not only naturally allows more than one event to happen within a single Mid_Proc() call, but also averages out any minor timing inconsistencies across the length of a track.
assert(length_of_tempo_message == 3);
uint32_t tempo = 0;
for(int i = 0; i < length_of_tempo_message; i++) {
- tempo += ((tempo << 8) + (*track_data++));+ tempo = ((tempo << 8) + (*track_data++));
}
Yup – the original code performed two additions per byte, which incorrectly added the interim value at every byte to the final result, and yielded a tempo that is ≈0.8% / ≈1 BPM slower than notated in the MIDI file, matching the number we were looking for. That's why the |/OR operator is the safer one to use in such a bit-twiddling context…
But now I'm curious. This is such a tiny bug that is bound to remain unnoticed until someone compares the game's MIDI output to another renderer. It must have certainly made it into other games whose MIDI code is based on Shuusou Gyoku's, or that pbg was involved with. And sure enough, not only did this bug survive Kioh Gyoku's OOP refactoring, but it even traveled into Windows Touhou, where it remained in every single game that supported MIDI playback. Now we know for a fact that pbg's Program Support role in the TH06 credits involved sharing ready-made, finished code with ZUN:
The broken tempo deserialization in the respective latest full versions of TH06 through TH10. And yes, that's TH10 – even though TH09's trial version was the last game to ship MIDI versions of its soundtrack, TH10 still contained all of pbg's MIDI code that originated back in Shuusou Gyoku, before TH11 finally removed it.
Amusingly, ZUN's compiler even started optimizing the combination of left-shifting and addition to a multiplication with 257 for TH09, which even sort of highlights this bug if you're used to reading x86 ASM.
That leaves support for MIDI loop points as the only missing feature for syncing MIDI data with a looping waveform track. While it didn't require all too much code, pbg's original zero-copy approach of iterating over raw MIDI data definitely injected a lot of complexity into the required branches. Multi-track/SMF Type 1 files require quite a bit of extra thought to correctly calculate delta times across loop boundaries that reach past the end of the respective track, while still allowing the real-time delta values to be resynchronized at tempo changes within the loop – and yes, 3 of ZUN's 19 arranged MIDI files actually do use more than one track, so this wasn't just about maximizing MIDI compatibility for mods. I stuck to the original approach mostly as a challenge and to prove that it's possible without first parsing the entire MIDI sequence into a friendlier internal representation, but I absolutely do not recommend this to anyone else.
After hardcoding the loop points detected by mly into the binary, we only need to call Mid_Proc() once per frame in the Music Room and pass the frame delta time instead of the 10 ms constant. And then, we get this:
The MIDI TIMER now shows off the arguably more interesting current MIDI pulse value rather than just formatting the PASSED TIME in milliseconds. Ironically, displaying this value in a constantly counting way takes more effort now – the new nanosecond-based timing code doesn't use any measure of total MIDI pulses anymore, and they don't naturally fall out of the algorithm either. Instead, the code remembers the total pulse value of the last event it processed and adds the real-time duration that has passed since, similar to the original timing algorithm.
This naturally causes the timer to jump from the loop end pulse to the loop start pulse, proving that Mid_Proc() is in fact looping the sequence.
Alright, now we know what to package:
We're going to have 8 BGM packs for each permutation of soundtrack (OST / AST), sound source (Romantique Tp / Sound Canvas VA), and codec (FLAC / Vorbis), making up 1.15 GiB of music data in total.
When looking at the package names, you will notice that I don't particularly highlight the FLAC versions as lossless. And for good reason – the Romantique Tp recordings had dithering and noise shaping applied to them, and the Sound Canvas VA versions will necessarily have to be volume-normalized and quantized to 16-bit during the conversion to FLAC. If we wanted a BGM pack with the actual raw Sound Canvas VA output, we'd have to implement WavPack support, which is the only lossless codec that supports 32-bit float – and even that codec could only compress these files down to 14 MiB per minute of music, or 508 MB for the entire original soundtrack. That's 1.4× the size of an equivalent thbgm.dat!
The whole packaging process will be complex enough to warrant a build system. I'd also like to generate an extensive README file for each package, not least to describe the Sound Canvas VA rendering and loop-cutting process in complete detail.
The AST packs need to bundle the MIDI files from ZUN's site for Music Room visualization. We might as well add a 9th MIDI-only AST pack then, as it will naturally fall out of the packaging pipeline anyway. Some people sure love their MIDI synths, after all.
The OST packs can fall back on the original game's MIDI files from MUSIC.DAT for their Music Room visualization, so there's no need to bundle those and infringe copyright. Ironically, the game will still require a MUSIC.DAT even if you use a BGM pack, if only for the one number in that file that says that Shuusou Gyoku's soundtrack consists of 20 tracks in total.
ZUN didn't arrange タイトルドメイド, so we need to copy the OST version recorded with the respective sound source into the AST pack.
Unfortunately, we still haven't reached the end of the complications and weird issues that haunt Shuusou Gyoku's music:
The original game reads the in-game track title directly out of the first Sequence Name event of the playing MIDI file. The waveform equivalent would be the Vorbis comment TITLE tag, which therefore should exactly match the original track's title, down to the exact placement of whitespace. As usual, if I emphasize minor things like this, it's not without reason: 幻想科学 ~ Doll's Phantom inconsistently uses halfwidth spaces at both sides of the ~, and wouldn't fit into the Music Room's limited space otherwise.
However, the AST MIDI files jam a bunch of other metadata into their Sequence Names, roughly following the format
【 $title 】 from 秋霜玉 for sc88Pro comp.ZUN
The track titles should definitely not appear in this format in-game, but how do we get rid of this format without hardcoding either the names or the magic to parse the names out of this format?
The absolute state of GS SysEx tooling rears its ugly head one final time in three of the AST MIDIs, which for some reason are missing the Roland vendor prefix byte in all of their SysEx messages and are therefore undeniably bugged. There even seemed to be another SysEx-related bug which Romantique Tp explained away, but not this one:
The irony of using invalid Reverb Macros within already invalid SysEx messages is not lost on me.
This is something we should fix even before running these files through Sound Canvas VA in order to render these with the reverb settings that ZUN clearly (and, for once, unironically) intended.
For perfect preservation of the original BGM/gameplay synchronicity, it makes sense for the waveform versions to retain the leading 1 or 2 beats of silence that the original MIDI files use for their SysEx setup. While some of the AST tracks use a slightly different tempo compared to their OST counterparts, they would still be largely in sync as ZUN didn't rearrange the layout of their setup area… except for, once again, the three tracks used in the Extra Stage. Marisa's and Reimu's boss themes aren't too bad with their 4 beats of setup, but シルクロードアリス takes the cake with a whopping 12 beats of leading silence. That's 5 seconds from the start of the Extra Stage to the first note you'd hear. 🐌
2) and 4) could theoretically be worked around in Shuusou Gyoku's MIDI code, but there's no way around editing the MIDI files themselves as far as 3) is concerned. Thus, it makes sense to apply all of the workarounds to the AST MIDIs as part of the BGM build process – parsing the titles out of the 【brackets】, inserting the Roland vendor prefix byte where necessary, and compressing the setup bars in the Extra Stage themes to match their OST counterparts. Adding any hidden magic to the MIDI code would only have needlessly increased complexity and/or annoyed some modder in the future who would then have to work around it.
Ideally, these edits would involve taking the mly dump output, performing the necessary replacements at a plaintext level, and rebuilding the result back into a MIDI file, bu~t we're unfortunately missing the latter feature. Luckily, someone else had the same idea 13 years ago and
wrote a tool in C that does exactly what we need. Getting it to compile in 2024 only required fixing a typical C thing… why are students and boomers defending this antique of a language again? 🙄
The single most glaring issue, however, is the drastic difference in volume between the individual tracks in both soundtracks. While Romantique Tp had to normalize each track to the maximum possible volume individually as a consequence of the recording process, the Sound Canvas VA renderings reveal just how inconsistent the volume levels of these MIDI files really are:
The peak amplitudes of every track in both soundtracks, as rendered by Sound Canvas VA at maximum volume. Looking at these, you might think that kaorin's 2007 recordings were purposely trying to preserve the clipping that would come out of an SC-88Pro if you don't manually adjust the volume knob for each song, but those recordings are still much louder than even these numbers.
So how do we interpret this? Is this a bug, because no one in their right mind would want their music to clip on purpose, and that in turn means that everything about these volume levels is arbitrary and unintentional? Or is this a quirk, and ZUN deliberately chose these volume levels for compositional reasons? It certainly would make sense for the name registration theme.
Once again, the AST version of シルクロードアリス is the worst offender in this regard as well, but it might also provide some evidence for the quirk interpretation. The fact that almost all of its MIDI channels blast away at full volume might have been an accident that could have gone unnoticed if the volume knob of ZUN's SC-88Pro was turned rather low during the time he arranged this piece, but the excessive left-panning must have been deliberate. Even Romantique Tp agrees:
It might have even made compositional sense if Silk Road Alice was supposed to be a "Western-style piece", but it's not.
And that's with the volume already normalized. Because this one channel of this one track is almost twice as loud as anything else in the AST, we would consequently have to bring down the volume of every other arranged track and the right channel of the same track by almost 50% if we wanted to maintain the volume differences between the individual tracks of the AST. In the process, we lose almost one entire bit of dynamic range. At this rate, you might even consider remixing and remastering the entire thing, but that would involve so many creative decisions to definitely fall into fanfiction territory…
However, normalizing each track to a peak level of 0 dBFS makes much more sense for in-game playback if you consider how loud Shuusou Gyoku's sound effects are. Once again, the best solution would involve offering both versions, but should we really add two more SCVA BGM packs just to cover volume differences? ReplayGain solves this exact problem for regular music listening in a non-destructive way by writing the per-track and per-album gain levels into an audio file's metadata. Since we need metadata support for titles anyway, we can do something similar, albeit not exactly the same for two reasons:
ReplayGain is specified to target an average volume of −17 dBFS, whereas we'd like to target a peak volume of 0 dBFS in order to always use the entire available digital scale. We've got some loud sound effects to compete with, after all.
ReplayGain expresses its gain values in dB, which is cumbersome to work with. In the realm of PCM, volume changes don't need to involve more than a simple multiplication, so let's go with a simple scalar GAIN FACTOR.
And so, we hard-apply the volume-level gain during the conversion from 32-bit float to FLAC to preserve the volume differences between the tracks, calculate the track-levelGAIN FACTOR based on the resulting peak levels, add a volume normalization toggle to the Sound / Config menu, enable it by default, and thus make everyone happy. ✅
The final interesting tidbit in building these packages can be found in the way the Sound Canvas VA recordings are looped. When manually cutting loops, you always have to consider that the intro might end with unique notes that aren't present at the end of the loop, which will still be fading out at the calculated loop start point. This necessitates shifting the loop start point by a few bars until these notes are no longer audible – or you could simply ignore the issue because ZUN's compositions are so frantic that no one would ever notice.
With the separate intro and loop files generated by mly, on the other hand, the reverb/release trails are immediately visible and, after trimming trailing silence, exactly define the number of samples that the calculated loop start point needs to be shifted by. The .loop file then remains always exactly as long, in samples, as the duration of the loop reported by mly. If a piece happens to have a constant tempo whose beat duration corresponds to an integer number of samples, we get some very satisfying, round loop durations out of this process. ☺️
So let's play it all back in-game… and immediately run into two unexpected miniaudio limitations, what the…?!
miniaudio uses a fixed linear function for its fade-out envelope, and doesn't offer anything else? We might not even want a logarithmic one this time because symmetry with MIDI's simple quadratic curve would be neat, but we sure don't want a linear function – those stay near the original volume for too long, and then turn quiet way too quickly.
There is no way to access FLAC metadata from miniaudio's public API, even though the library bundles the author's own FLAC library which has this feature?
📝 Back when I evaluated miniaudio, I alluded that I consider single-file C libraries to be massively overrated, and this is exactly why: Once they grow as massive as miniaudio (how ironic), they can quickly lead to their authors treating their dependencies as implementation details and melting down the interfaces that would naturally arise. In a regular library, dr_flac would be a separate, proper dependency, and the API would have a way to initialize a stream from an externally loaded drflac object. But since the C community collectively pretends that multi-file libraries are a burden on other developers, miniaudio ended up with dr_flac copy-pasted into its giant single file, with a silly ma_ namespacing prefix added to all its functions. And why? Did we have to move so far in the other direction just because CMake doesn't support globbing? That's a symptom of CMake not actually solving any problem, not a valid architectural decision that libraries should bend around. 🙄
So unless we fork and hack around in miniaudio, there's now no way around depending on a second, regular copy of dr_flac. Which has now led to the same project organization bloat that single-file libraries originally set out to prevent…
Sigh. At this rate, it makes more sense to just copy-paste and adapt the old BGM streaming code I wrote for thcrap in late 2018, which used dr_flac directly, and extend it with metadata support. With the streaming code moved out of the platform layer and into game logic, it also makes much more sense to implement the squared fade-out curve at that same level instead of copy-pasting and adjusting an unhealthy amount of miniaudio's verbose C code.
While I'm doing the same for the old Vorbis streaming code, it would also make sense to rewrite that one to use stb_vorbis instead of the old libogg+libvorbis reference libraries. There's no need to add two more dependencies if miniaudio already comes with stb_vorbis.c, and that library is widelyacclaimed. So, integration should be a breeze, right?
Well, surprise, rarely have I seen a C library so actively hostile toward being integrated. Both of its API variants are completely unreasonable:
The pulldata API pulls Vorbis data as needed from either a memory buffer containing the entire Vorbis file, or a C FILE* handle.
Effectively, this forces either you to give up disk streaming completely, or your program into C's terrible I/O API with all its buffering slowness and Unicode issues on Windows. The documentation even goes on to suggest just modifying the code if you need anything else, which might be acceptable in the strange world of game development this library originates from, but it sure isn't in the kind of open-source development I do.
The pushdata API expects the caller to gradually feed chunks of Vorbis data. How large do these chunks have to be? Nobody knows – and, even worse, the API doesn't retain any of the data already pushed in. If the buffer you passed is too small, which you don't get to know in advance, you have to pass the same data plus more in the next call. I get that you might want an API like this to avoid dynamic memory allocations, but not only does this API perform plenty of allocations itself, it actively forces its caller to realloc() over and over again. 🙄 The lack of seeking support reveals that this API is geared towards live-streamed audio, and it might very well be acceptable in such a case, but it's nothing we could use for BGM.
What happened to the tried-and-true idea of providing a structure with read, tell, and seek callbacks, and then providing an optional variant for C FILE* handles if you absolutely must? Sure, the whole point of Vorbis is to be small and nobody these days would care about spending a few MB on keeping an entire Vorbis file in memory, but come on. If pulldata made the deliberate and opinionated choice to only support buffers of complete Vorbis streams and argued in the name of simplicity that hand-coded disk streaming isn't worth it in this day and age, I might have even been convinced. And this is from the guy who popularized the concept of single-file C libraries in the first place?
Oh well, tupblocks go brrr. libvorbis definitely shows its age with all the old command-line tools in the lib/ directory that they never moved away and that we now have to remove from our glob. But even that just adds a single line to the Tupfile, and then we get to enjoy its much friendlier API. That sure beats the almost 800 lines of code that miniaudio had to write to integrate stb_vorbis… which I can't even link because the file is too big for GitHub. 🤷
At this point, it would have even made sense to upgrade from a 24-year-old lossy codec to an 11-year-old lossy codec and use Opus instead, since the enforced 48,000 Hz sampling rate is a non-issue when you control the entire audio pipeline. But let's keep compatibility with existing thcrap mods for now.
In the end, the Windows build ended up using only a single one of the miniaudio features that DirectSound doesn't have, and that's the ability to use the more modern WASAPI instead of DirectSound. We're still going to use miniaudio for the Linux port, but as far as Windows is concerned, it would be quite nice to backport BGM streaming to the game's original DirectSound backend. The P0275 build is pushing 1 MiB of binary size for a game that originally came in a 220 KiB binary, so it would remove a noticeable amount of bloat from GIAN07.EXE, but it would also allow waveform BGM to work in the Windows 98-compatible i586 build. If that sounds cool to you, this is the issue you want to fund.
That only left some logic and UI busywork to put it all together, which means that we've almost reached the end of things to talk about! Here's what it all looks like:
BGM pack selection is done in-game through a new submenu. The <Download> option will open the BGM pack release page in the system's preferred browser:
This window presented a great occasion for already implementing the generic boilerplate for vertically scrolling windows with an unlimited number of items. That will come in quite handy once we introduce better replay support… 👀
Even with per-track BGM volume normalization, Shuusou Gyoku's sound effects are still a bit too loud in comparison, especially when mixed on top of that excessively and unfixably left-panned AST version of the Extra Stage theme. Adding separate volume controls for BGM and sound effects really was the only sustainable solution here, and conveniently checks an important quality-of-life box the original game lacked. So important that it was the very first issue I added to the GitHub tracker of my fork:
I really wanted to have Japanese help text in these menus, as it makes them look just so much more consistent and polished. Many thanks to Elfin, who responded to my bounty offer, and will most likely also provide localizations for future features.
In-game music titles are now consistently right-aligned. Leading whitespace in 4 of the original MIDI Sequence Names suggests that pbg might have intended these titles to be centered within the 216 maximum pixels that the original code designated for music titles, but none of those 4 had the correct amount of spaces that would have been required for exact centering:
Right-aligned text matches the one certain intention I can read out of the code, and allows us to consistently trim whitespace from both the original MIDI Sequence Names and the TITLE tags in the BGM packs… at the cost of significantly changing the animation. 🤔
Maybe, all this whitespace had the explicit purpose of making the animation look the way it did originally? But hard-padding the title tags in the BGM packs would be so dumb… 😩 Let's keep it like this for now and fix the animation later.
At startup, the game now shows a new screen if any of the game's .DAT files are missing, displaying their expected absolute path. This is bound to be very important on Linux because each distribution might have its own idea of where these files are supposed to be stored. But even on Windows, this allows GIAN07.EXE to at least run and show something if one or more of these files are not present, instead of crashing at the first attempt of loading anything from them.The ¥ instead of \ is, 📝 once again, a font issue. Good luck finding a font not named MS Gothic that looks good when rendered in this game…
On a more unfortunate note, I dropped the i586 build from this release. Visual Studio 2022's CRT implements the new filesystem and threading code using Win32 API functions that are only available on Vista or later and are not covered by the one ready-made KernelEx package I was able to find, so I couldn't easily test such a build on Windows 98 anymore. Resurrecting the i586 build would therefore involve additional platform abstraction layers that we wouldn't need otherwise. Writing them wouldn't be too expensive, but it only makes sense if there's actual demand. Backporting waveform BGM to DirectSound to restore feature parity would also be a good idea here, as it would avoid the need to litter the current code with #ifdefs at any place that references anything related to BGM packs.
After half a year of being bought out way past the cap, I've finally got some small room left for new orders again. If it weren't for this blog post and the required research and web development work, this delivery would have probably come out in early January, taking half the time it ended up taking. So I really have to start factoring the blog posts into the push prices in a better and fairer way.
Meanwhile, the hate toward my day job only keeps growing, but there's little point in looking for a new one as long as ReC98 remains this motivating and complex. It leaves pretty much no cognitive room for any similarly demanding job. Thus, I want 2024 to be the year where ReC98 either becomes profitable enough to be my only full-time job, or where we conclusively find out that it can't, I go look for a better day job, and ReC98 shifts to a slower pace. Here's the plan:
From now on, I will immediately increase the push price whenever we reach 100% of the cap, either directly through new orders or indirectly through existing subscriptions. The price increase will be relative to how long it took to reach that point since the last re-opening.
If the store continues selling out, I will aim for per push by the end of the year.
In exchange, microtransactions (i.e., deliveries containing just code and no blog posts) will now be half the price of regular pushes for the same amount of delivered code. Or in other words: If you want to fund a goal that's eligible for microtransactions, you can now decide whether your fixed amount of money goes to 2× coding work and 0× blogging, or 1× coding work and 1× blogging.
I'll permanently increase the default level of the cap from 8 to 10 pushes. The past 12 months were full of mod releases that raised the bar, and 2024 shows no signs of stopping that trend.
If we ever reach per push, I plan to hire people for some of the contribution-ideas or anything else that might improve this project. (Well-produced YouTube videos about the findings of this project might be a nice idea!) At that point, I will have reached my goal of living decently off this project alone, and it's time for others to make money in this space as well.
With the new price of per push, this means that there's now a small window in which you can get a full push worth of functionality for , until the current cap is filled up again.
Next up: Probably TH02's endings to relax a bit. Maybe we're also getting some new Touhou-related contributions?
And now we're taking this small indie game from the year 2000 and porting
its game window, input, and sound to the industry-standard cross-platform
API with "simple" in its name.
Why did this have to be so complicated?! I expected this to take maybe 1-2
weeks and result in an equally short blog post. Instead, it raised so many
questions that I ended up with the longest blog post so far, by quite a wide
margin. These pushes ended up covering so many aspects that could be
interesting to a general and non-Seihou-adjacent audience, so I think we
need a table of contents for this one:
Before we can start migrating to SDL, we of course have to integrate it into
the build somehow. On Linux, we'd ideally like to just dynamically link to a
distribution's SDL development package, but since there's no such thing on
Windows, we'd like to compile SDL from source there. This allows us to reuse
our debug and release flags and ensures that we get debug information,
without needing to clone build scripts for every
C++ library ever in the process or something.
So let's get my Tup build scripts ready for compiling vendored libraries… or
maybe not? Recently, I've kept hearing about a hot new
technology that not only provides the rare kind of jank-free
cross-compiling build system for C/C++ code, but innovates by even
bundling a C++ compiler into a single 279 MiB package with no
further dependencies. Realistically replacing both Visual Studio and Tup
with a single tool that could target every OS is quite a selling point. The
upcoming Linux port makes for the perfect occasion to evaluate Zig, and to
find out whether Tup is still my favorite build system in 2023.
Even apart from its main selling point, there's a lot to like about Zig:
First and foremost: It's a modern systems programming language with
seamless C interop that we could gradually migrate parts of the codebase to.
The feature set of the core language seems to hit the sweet spot between C
and C++, although I'd have to use it more to be completely sure.
A native, optimized Hello World binary with no string formatting is
4 KiB when compiled for Windows, and 6.4 KiB when cross-compiled
from Windows to Linux. It's so refreshing to see a systems language in 2023
that doesn't bundle a bulky runtime for trivial programs and then defends it
with the old excuse of "but all this runtime code will come in handy the
larger your program gets". With a first impression like this, Zig
managed to realize the "don't pay for what you don't use" mantra that C++
typically claims for itself, but only pulls off maybe half of the time.
You can directly
target specific CPU models, down to even the oldest 386 CPUs?! How
amazing is that?! In contrast, Visual Studio only describes its /arch:IA32
compatibility option in very vague terms, leaving it up to you to figure out
that "legacy 32-bit x86 instruction set without any vector
operations" actually means "i586/P5 Pentium, because the startup code
still includes an unconditional CPUID instruction". In any
case, it means that Zig could also cover the i586 build.
Even better, changing Zig's CPU model setting recompiles both its
bundled C/C++ standard library and Zig's own compiler-rt polyfill
library for that architecture. This ensures that no unsupported
instructions ever show up in the binary, and also removes the need for
any CPUID checks. This is so much better than the Visual
Studio model of linking against a fixed pre-compiled standard library
because you don't have to trust that all these newer instructions
wouldn't actually be executed on older CPUs that don't have them.
I love the auto-formatter. Want to lay out your struct literal into
multiple lines? Just add a trailing comma to the end of the last element.
It's very snappy, and a joy to use.
Like every modern programming language, Zig comes with a test framework
built into the language. While it's not all too important for my grand plan
of having one big test that runs a bunch of replays and compares their game
states against the original binary, small tests could still be useful for
protecting gameplay code against accidental changes. It would be great if I
didn't have to evaluate and choose among
the many testing frameworks for C++ and could just use a language
standard.
Package
management is still in its infancy, but it's looking pretty good so far,
resembling Go's decentralized approach of just pointing to a URL but with
specific version selection from the get-go.
However, as a version number of 0.11.0 might already suggest, the whole
experience was then bogged down by quite a lot of issues:
While Zig's C/C++ compilation feature is very
well architected to reuse the C/C++ standard libraries of GCC and MinGW and
thus automatically keeps up with changes to the C++ standard library,
it's ultimately still just a Clang frontend. If you've been working with a
Visual Studio-exclusive codebase – which, as we're going to see below, can
easily happen even if you compile in C++23 mode – you'd now have to
migrate to Clang and Zig in a single step. Obviously, this can't ever
be fixed without Microsoft open-sourcing their C++ compiler. And even then,
supporting a separate set of command-line flags might not be worth it.
The standard library is very poorly documented, especially in the
build-related parts that are meant to attract the C++ audience.
Often, the only documentation is found in blog posts from a few years
ago, with example code written against old Zig versions that doesn't compile
on the newest version anymore. It's all very far from stable.
However, Zig's project generation sub-commands (zig
init-exe and friends) do emit well-documented boilerplate
code? It does make sense for that code to double as a comprehensive example,
but Zig advertises itself as so simple that I didn't even think about
bootstrapping my project with a CLI tool at first – unlike, say, Rust, where
a project always starts with filling out a small form in
Cargo.toml.
There's no progress output for C/C++ compilation? Like, at all?
This hurts especially because compilation times are significantly longer
than they were with Visual Studio. By default, the current Tupfile builds
Shuusou Gyoku in both debug and release configurations simultaneously. If I
fully rebuild everything from a clean cache, Visual Studio finishes such a
build in roughly the same amount of time that Zig takes to compile just a
debug build.
The --global-cache-dir option is only supported by specific
subcommands of the zig CLI rather than being a top-level
setting, and throws an error if used for any other subcommand. Not having a
system-wide way to change it and being forced into writing a wrapper script
for that is fine, but it would be nice if said wrapper script didn't have to
also parse and switch over the subcommand just to figure out whether it is
allowed to append the setting.
compiler-rt still needs a bit of dead code elimination work. As soon as
your program needs a single polyfilled function, you get all of them,
because they get referenced in some exception-related table even if nothing
uses them? Changing the link_eh_frame_hdr option had no
effect.
And that was not the only std.Build.Step.Compile option
that did nothing. Worse, if I just tweaked the options and changed nothing
about the code itself, Zig simply copied a previously built executable
out of its build cache into the output directory, as revealed by the
timestamp on the .EXE. While I am willing to believe that Zig correctly
detects that all these settings would just produce the same binary, I do not
like how this behavior inspires distrust and uncertainty in Zig's build
process as a whole. After all, we still live in a world where clearing
the build cache is way too often the solution for weird problems in
software, especially when using CMake. And it makes sense why it would be:
If you develop a complex system and then try solving the infamously hard
problem of cache invalidation on top, the risk of getting cache invalidation
wrong is, by definition, higher than if that was the only thing your system
did. That's the reason why I like Tup so much: It solely focuses on
getting cache invalidation right, and rather errs on the side of caution by
maybe unnecessarily rebuilding certain files every once in a while because
the compiler may have read from an environment variable that has changed in
the meantime. But this is the one job I expect a build system to do, and Tup
has been delivering for years and has become fundamentally more trustworthy
as a result.
Zig activates Clang's UBSan
in debug builds by default, which executes a program-crashing
UD2 instruction whenever the program is about to rely on
undefined C++ behavior. In theory, that's a great help for spotting hidden
portability issues, but it's not helpful at all if these crashes are
seemingly caused by C++ standard library code?! Without any clear info
about the actual cause, this just turned into yet another annoyance on
top of all the others. Especially because I apparently kept searching for
the wrong terms when I first encountered this issue, and only found
out how to deactivate it after I already decided against Zig.
Also, can we get /PDBALTPATH?
Baking absolute paths from the filesystem of the developer's machine into
released binaries is not only cringe in itself, but can also cause potential
privacy or security accidents.
So for the time being, I still prefer Tup. But give it maybe two or three
years, and I'm sure that Zig will eventually become the best tool for
resurrecting legacy C++ codebases. That is, if the proposed divorce of the
core Zig compiler from LLVMisn't an indication that the
productive parts of the Zig community consider the C/C++ building features
to be "good enough", and are about to de-emphasize them to focus more
strongly on the actual Zig language. Gaining adoption for your new systems
language by bundling it with a C/C++ build system is such a great and unique
strategy, and it almost worked in my case. And who knows, maybe Zig will
already be good enough by the time I get to port PC-98 Touhou to modern
systems.
(If you came from the Zig
wiki, you can stop reading here.)
A few remnants of the Zig experiment still remain in the final delivery. If
that experiment worked out, I would have had to immediately change the
execution encoding to UTF-8, and decompile a few ASM functions exclusive to
the 8-bit rendering mode which we could have otherwise ignored. While Clang
does support inline assembly with Intel syntax via
-fms-extensions, it has trouble with ; comments
and instructions like REP STOSD, and if I have to touch that
code anyway… (The REP STOSD function translated into a single
call to memcpy(), by the way.)
Another smaller issue was Visual Studio's lack of standard library header
hygiene, where #including some of the high-level STL features also includes
more foundational headers that Clang requires to be included separately, but
I've already known about that. Instead, the biggest shocker was that Visual
Studio accepts invalid syntax for a language feature as recent as C++20
concepts:
// Defines the interface of a text rendering session class. To simplify this
// example, it only has a single `Print(const char* str)` method.
template <class T> concept Session = requires(T t, const char* str) {
t.Print(str);
};
// Once the rendering backend has started a new session, it passes the session
// object as a parameter to a user-defined function, which can then freely call
// any of the functions defined in the `Session` concept to render some text.
template <class F, class S> concept UserFunctionForSession = (
Session<S> && requires(F f, S& s) {
{ f(s) };
}
);
// The rendering backend defines a `Prerender()` method that takes the
// aforementioned user-defined function object. Unfortunately, C++ concepts
// don't work like this: The standard doesn't allow `auto` in the parameter
// list of a `requires` expression because it defines another implicit
// template parameter. Nevertheless, Visual Studio compiles this code without
// errors.
template <class T, class S> concept BackendAttempt = requires(
T t, UserFunctionForSession<S> auto func
) {
t.Prerender(func);
};
// A syntactically correct definition would use a different constraint term for
// the type of the user-defined function. But this effectively makes the
// resulting concept unusable for actual validation because you are forced to
// specify a type for `F`.
template <class T, class S, class F> concept SyntacticallyFixedBackend = (
UserFunctionForSession<F, S> && requires(T t, F func) {
t.Prerender(func);
}
);
// The solution: Defining a dummy structure that behaves like a lambda as an
// "archetype" for the user-defined function.
struct UserFunctionArchetype {
void operator ()(Session auto& s) {
}
};
// Now, the session type disappears from the template parameter list, which
// even allows the concrete session type to be private.
template <class T> concept CorrectBackend = requires(
T t, UserFunctionArchetype func
) {
t.Prerender(func);
};
What's this, Visual Studio's infamous delayed template parsing applied to
concepts, because they're templates as well? Didn't
they get rid of that 6 years ago? You would think that we've moved
beyond the age where compilers differed in their interpretation of the core
language, and that opting into a current C++ standard turns off any
remaining antiquated behaviors…
So let's actually get my Tup build scripts ready for compiling
vendored libraries, because the
📝 previous 70 lines of Lua definitely
weren't. For this use case, we'd like to have some notion of distinct build
targets that can have a unique set of compilation and linking flags. We'd
also like to always build them in debug and release versions even if you
only intend to build your actual program in one of those versions – with the
previous system of specifying a single version for all code, Tup would
delete the other one, which forces a time-consuming and ultimately needless
rebuild once you switch to the other version.
The solution I came up with treats the set of compiler command-line options
like a tree whose branches can concatenate new options and/or filter the
versions that are built on this branch. In total, this is my 4th
attempt at writing a compiler abstraction layer for Tup. Since we're
effectively forced to write such layers in Lua, it will always be a
bit janky, but I think I've finally arrived at a solid underlying design
that might also be interesting for others. Hence, I've split off the result
into its own separate
repository and added high-level documentation and a documented example.
And yes, that's a Code Nutrition
label! I've wanted to add one of these ever since I first heard about the
idea, since it communicates nicely how seriously such an open-source project
should be taken. Which, in this case, is actually not all too
seriously, especially since development of the core Tup project has all but
stagnated. If Zig does indeed get better and better at being a Clang
frontend/build system, the only niches left for Tup will be Visual
Studio-exclusive projects, or retrocoding with nonstandard toolchains (i.e.,
ReC98). Quite ironic, given Tup's Unix heritage…
Oh, and maybe general Makefile-like tasks where you just want to run
specific programs. Maybe once the general hype swings back around and people
start demanding proper graph-based dependency tracking instead of just a command runner…
Alright, alternatives evaluated, build system ready, time to include SDL!
Once again, I went for Git submodules, but this time they're held together
by a
batch file that ensures that the intended versions are checked out before
starting Tup. Git submodules have a bad rap mainly because of their
usability issues, and such a script should hopefully work around
them? Let's see how this plays out. If it ends up causing issues after all,
I'll just switch to a Zig-like model of downloading and unzipping a source
archive. Since Windows comes with curl and tar
these days, this can even work without any further dependencies, and will
also remove all the test code bloat.
Compiling SDL from a non-standard build system requires a
bit of globbing to include all the code that is being referenced, as
well as a few linker settings, but it's ultimately not much of a big deal.
I'm quite happy that it was possible at all without pre-configuring a build,
but hey, that's what maintaining a Visual Studio project file does to a
project.
By building SDL with the stock Windows configuration, we then end up with
exactly what the SDL developers want us to use… which is a DLL. You
can statically link SDL, but they really don't want you to do
that. So strongly, in fact, that they not
merely argue how well the textbook advantages of dynamic linking have worked
for them and gamers as a whole, but implemented a whole dynamic API
system that enforces overridable dynamic function loading even in static
builds. Nudging developers to their preferred solution by removing most
advantages from static linking by default… that's certainly a strategy. It
definitely fits with SDL's grassroots marketing, which is very good at
painting SDL as the industry standard and the only reliable way to keep your
game running on all originally supported operating systems. Well, at least
until SDL 3 is so stable that SDL 2 gets deprecated and won't
receive any code for new backends…
However, dynamic linking does make sense if you consider what SDL is.
Offering all those multiple rendering, input, and sound backends is what
sets it apart from its more hip competition, and you want to have all of
them available at any time so that SDL can dynamically select them based on
what works best on a system. As a result, everything in SDL is being
referenced somewhere, so there's no dead code for the linker to eliminate.
Linking SDL statically with link-time code generation just prolongs your
link time for no benefit, even without the dynamic API thwarting any chance
of SDL calls getting inlined.
There's one thing I still don't like about all this, though. The dynamic
API's table references force you to include all of SDL's subsystems in the
DLL even if your game doesn't need some of them. But it does fit with their
intention of having SDL2.dll be swappable: If an older game
stopped working because of an outdated SDL2.dll, it should be
possible for anyone to get that game working again by replacing that DLL
with any newer version that was bundled with any random newer game. And
since that would fail if the newer SDL2.dll was size-optimized
to not include some of the subsystems that the older game required, they
simply removed (or de-prioritized) the possibility altogether.
Maybe that was their train of thought? You can always just use the official Windows
DLL, whose whole point is to include everything, after all. 🤷
So, what do we get in these 1.5 MiB? There are:
renderer backends for Direct3D 9/11/12, regular OpenGL, OpenGL ES 2.0,
Vulkan, and a software renderer,
and audio backends for WinMM, DirectSound, WASAPI, and direct-to-disk
recording.
Unfortunately, SDL 2 also statically references some newer Windows API
functions and therefore doesn't run on Windows 98. Since this build of
Shuusou Gyoku doesn't introduce any new features to the input or sound
interfaces, we can still use pbg's original DirectSound and DirectInput code
for the i586 build to keep it working with the rest of the
platform-independent game logic code, but it will start to lag behind in
features as soon as we add support for SC-88Pro BGM or more sophisticated input
remapping. If we do want to keep this build at the same feature level as
the SDL one, we now have a choice: Do we write new DirectInput and
DirectSound code and get it done quickly but only for Shuusou Gyoku, or do
we port SDL 2 to Windows 98 and benefit all other SDL 2 games as
well? I leave
that for my backers to decide.
Immediately after writing the first bits of actual SDL code to initialize
the library and create the game window, you notice that SDL makes it very
simple to gradually migrate a game. After creating the game window, you can
call SDL_GetWindowWMInfo()
to retrieve HWND and HINSTANCE handles that allow
you to continue using your original DirectDraw, DirectSound, and DirectInput
code and focus on porting one subsystem at a time.
Sadly, D3DWindower can no longer turn SDL's fullscreen mode into a windowed
one, but DxWnd still works, albeit behaving a bit janky and insisting on
minimizing the game whenever its window loses focus. But in exchange, the
game window can surprisingly be moved now! Turns out that the originally
fixed window position had nothing to do with the way the game created its
DirectDraw context, and everything to do with pbg
blocking the Win32 "syscommand" that allows a window to be moved. By
deleting a system menu… seriously?! Now I'm dying to hear the Raymond
Chen explanation for how this behavior dates back to an unfortunate decision
during the Win16 days or something.
As implied by that commit, I immediately backported window movability to the
i586 build.
However, the most important part of Shuusou Gyoku's main loop is its frame
rate limiter, whose Win32 version leaves a bit of room for improvement.
Outside of the uncapped [おまけ] DrawMode, the
original main loop continuously checks whether at least 16 milliseconds have
elapsed since the last simulated (but not necessarily rendered) frame. And
by that I mean continuously, and deliberately without using any of
the Windows system facilities to sleep the process in the meantime, as
evidenced by a commented-out Sleep(1) call. This has two
important effects on the game:
The 60Fps DrawMode actually corresponds to a
frame rate of
(1000 / 16) = 62.5 FPS,
not 60. Since the game didn't account for the missing
2/3 ms to bring the limit down to exactly 60 FPS,
62.5 FPS is Shuusou Gyoku's actual official frame rate in a
non-VSynced setting, which we should also maintain in the SDL port.
Not sleeping the process turns Shuusou Gyoku's frame rate limitation
into a busy-waiting loop, which always uses 100% of a single CPU core just
to wait for the next frame.
Sure, modern computers are fast, but a frame won't ever take an
infinitely fast 0 milliseconds to render. So we still need to take the
current frame time into account.
SDL_Delay()'s documentation says that the wake-up could be
further delayed due to OS scheduling.
To address both of these issues, I went with a base delay time of
15 ms minus the time spent on the current frame, followed by
busy-waiting for the last millisecond to make sure that the next frame
starts on the exact frame boundary. And lo and behold: Even though this
still technically wastes up to 1 ms of CPU time, it still dropped CPU
usage into the 0%-2% range during gameplay on my Intel Core i5-8400T CPU,
which is over 5 years old at this point. Your laptop battery will appreciate
this new build quite a bit.
Time to look at audio then, because it sure looks less complicated than
input, doesn't it? Loading sounds from .WAV file buffers, playing a fixed
number of instances of every sound at a given position within the stereo
field and with optional looping… and that's everything already. The
DirectSound implementation is so straightforward that the most complex part
of its code is the .WAV file parser.
Well, the big problem with audio is actually finding a cross-platform
backend that implements these features in a way that seamlessly works with
Shuusou Gyoku's original files. DirectSound really is the perfect sound API
for this game:
It doesn't require the game code to specify any output sample format.
Just load the individual sound effects in their original format, and
playback just works and sounds correctly.
Its final sound stream seems to have a latency of 10 ms, which is
perfectly fine for a game running at 62.5 FPS. Even 15 ms would be
OK.
Sound effect looping? Specified by passing the
DSBPLAY_LOOPING flag to
IDirectSoundBuffer::Play().
Stereo panning balancing? One method call.
Playing the same sound multiple times simultaneously from a single
memory buffer? One
method call. (It can fail though, requiring you to copy the data after
all.)
Pausing all sounds while the game window is not focused? That's the
default behavior, but it can be equally easily disabled with just
a single per-buffer flag.
Future streaming of waveform BGM? No problem either. Windows Touhou has
always done that, and here's
some code I wrote 12½ years ago that would even work without DirectSound
8's notification feature.
No further binary bloat, because it's part of the operating system.
The last point can't really be an argument against anything, but we'd still
be left with 7 other boxes that a cross-platform alternative would have to
tick. We already picked SDL for our portability needs, so how does its audio
subsystem stack up? Unfortunately, not great:
It's fully DIY. All you get is a single output buffer, and you have to
do all the mixing and effect processing yourself. In other words, it's the
masochistic approach to cross-platform audio.
There are helper functions for resampling and mixing, but the
documentation of the latter is full of FUD. With a disclaimer that so
vehemently discourages the use of this function, what are you supposed to do
if you're newly integrating SDL audio into a game? Hunt for a separate sound
mixing library, even though your only quality goal is parity with stone-age
DirectSound? 🙄
It forces the game to explicitly define the PCM sampling rate, bit
depth, and channel count of the output buffer. You can't
just pass a nullptr to SDL_OpenAudioDevice(),
and if you pass a zeroed SDL_AudioSpec structure, SDL just defaults
to an unacceptable 22,050 Hz sampling rate, regardless of what the
audio device would actually prefer. It took until last year for them to
notice that people would at least like to query the native
format. But of course, this approach requires the backend to actually
provide this information – and since we've seen above that DirectSound
doesn't care, the
DirectSound version of this function has to actually use the more modern
WASAPI, and remains unimplemented if that API is not available.
Standardizing the game on a single sampling rate, bit depth, and channel
count might be a decent choice for games that consistently use a single
format for all its sounds anyway. In that case, you get to do all mixing and
processing in that format, and the audio backend will at most do one final
conversion into the playback device's native format. But in Shuusou Gyoku,
most sound effects use 22,050 Hz, the boss explosion sound effect uses
11,025 Hz, and the future SC-88Pro BGM will obviously use
44,100 Hz. In such a scenario, you would have to pick the highest
sampling rate among all sound sources, and resample any lower-quality sounds
to that rate. But if the audio device uses a different sampling rate, those
lower-quality sounds would get resampled a second time.
I know that this
will be fixed in SDL 3, but that version is still under heavy
development.
Positives? Uh… the callback-based nature means that BGM streaming is
rather trivial, and would even be comparatively less complicated than with
DirectSound. Having a mutex to prevent
writes to your sound instance structures while they're being read by the
audio thread is nice too.
OK, sure, but you're not supposed to use it for anything more than a
single stream of audio. SDL_mixer exists precisely to cover such non-trivial
use cases, and it even supports sound effect looping and panning with just a
single function call! But as far as the rest of the library is concerned, it
manages to be an even bigger disappointment than raw SDL audio:
As it sits on top of SDL's audio subsystem, it still can't just use your
audio device's native sample format.
It only offers a very opinionated system for streaming – and of course,
its opinion is wrong. 😛 The fact that it only supports a single streaming
audio track wouldn't matter all too much if you could switch to another
track at sample precision. But since you can't, you're forced to implement
looping BGM using a single file…
…which brings us to the unfortunate issue of loop point definitions.
And, perhaps most importantly, the complete lack of any way to set them
through the API?! It doesn't take long until you come up with a theory for
why the API only offers a function to retrieve loop points: The
"music" abstraction is so format-agnostic that it even supports MIDI
and tracker formats where a typical loop point in PCM samples doesn't make
sense. Both of these formats already have in-band ways of specifying loop
points in their respective time units. They
might not be standardized, but it's still much better than usual
single-file solutions for PCM streams where the loop point has to be stored
in an out-of-band way – such as in a metadata tag or an entirely separate
file.
Speaking of MIDI, why is it so common among these APIs to not have
any way of specifying the MIDI device? The fact that Windows Vista
removed the Control Panel option for specifying the system-wide default
MIDI output device is no excuse for your API lacking the option as well.
In fact, your MIDI API now needs such a setting more than it was
needed in the Windows XP and 9x days.
Funnily enough, they did once receive a patch for a function to set loop
points which was never upstreamed… and this patch came from
the main developer behind PyTouhou, who needed that feature for obvious
reasons. The world sure is a small place.
As a result, they turned loop points into a property that each
individual format may
or may
not have. Want to loop
MP3 files at sample precision? Tough luck, time to reconvert to another
lossy format. 🙄 This is the exact jank I decided against when I implemented
BGM modding for thcrap back in 2018,
where I concluded that separate intro and
loop files are the way to go.
But OK, we only plan to use FLAC and Ogg Vorbis for the SC-88Pro BGM, for
which SDL_mixer does support loop points in the form of Vorbiscomments,
and hey, we can even pass them at sample accuracy. Sure, it's wrong and
everything, but nothing I couldn't work with…
However, the final straw that makes SDL_mixer unsuitable for Shuusou
Gyoku is its core sound mixing paradigm of distributing all sound effects
onto a fixed number of channels, set to 8
by default. Which raises the quite ridiculous question of how many we
would actually need to cover the maximum amount of sounds that can
simultaneously be played back in any game situation. The theoretic maximum
would be 41, which is the combined sum of individual sound buffer instances
of all 20 original sound effects. The practical limit would surely be a lot
smaller, but we could only find out that one through experiments, which
honestly is quite a silly proposition.
It makes you wonder why they went with this paradigm in the first
place. And sure enough, they actually
use the aforementioned SDL core function for mixing audio. Yes, the
same function whose current documentation advises against using it for
this exact use case. 🙄 What's the argument here? "Sure, 8 is
significantly more than 2, but any mixing artifacts that will occur for
the next 6 sounds are not worrying about, but they get really bad
after the 8th sound, so we're just going to protect you from
that"?
This dire situation made me wonder if SDL was the wrong choice for Shuusou
Gyoku to begin with. Looking at other low-level cross-platform game
libraries, you'll quickly notice that all of them come with mostly
equally capable 2D renderers these days, and mainly differentiate themselves
in minute API details that you'd only notice upon a really close look. raylib is another one of those
libraries and has been getting exceptionally popular in recent years, to the
point of even having more than twice as many GitHub stars as SDL. By
restricting itself to OpenGL, it can even offer an
abstraction for shaders, which we'd really like for the 西方Project lens ball effect.
In the case of raylib's audio system, the lack of sound effect looping is
the minute API detail that would make it annoying to use for Shuusou Gyoku.
But it might be worth a look at how raylib implements all this if it doesn't
use SDL… which turned out to be the best look I've taken in a long time,
because raylib builds on top of miniaudio
which is exactly the kind of audio library I was hoping to find.
Let's check the list from above:
🟢 miniaudio's high-level API initialization defaults to the native
sample format of the playback device. Its internal processing uses 32-bit
floating-point samples and only converts back to the native bit depth as
necessary when writing the final stream into the backend's audio buffer.
WASAPI, for example, never needs any further conversion because it operates
with 32-bit floats as well.
🟢 The final audio stream uses the same 10 ms update period (and
thus, sound effect latency) that I was getting with DirectSound.
🟢 Stereo panning balancing? ma_sound_set_pan(),
although it does require a conversion from Shuusou Gyoku's dB units into a
linear attenuation factor.
🟢 Sound effect looping? ma_sound_set_looping().
🟢 Playing the same sound multiple times simultaneously from a single
memory buffer? Perfectly possible, but requires a bit of digging in the
header to find the best solution. More on that below.
🟢 Future streaming of waveform BGM? Just call
ma_sound_init_from_file() with the
MA_SOUND_FLAG_STREAM flag.
👍 It also comes with a FLAC decoder in the core library and an Ogg
Vorbis one as part of the repo, …
🤩 … and even supports gapless switching between the intro and loop
files via a single declarative call to
ma_data_source_set_next()!
(Oh, and it also has ma_data_set_loop_point_in_pcm_frames()
for anyone who still believes in obviously and objectively
inferior out-of-band loop points.)
🟢 Pausing all sounds while the game window is not focused? It's not
automatic, but adding new functions to the sound interface and calling
ma_engine_stop() and ma_engine_start() does the
trick, and most importantly doesn't cause any samples to be lost in the
process.
🟡 Sound control is implemented in a lock-free way, allowing your main
game thread to call these at any time without causing glitches on the audio
thread. While that looks nice and optimal on the surface, you now have to
either believe in the soundness (ha) of the implementation, or verify that
atomic structure fields actually are enough to not cause any race
conditions (which I did for the calls that Shuusou Gyoku uses, and I didn't
find any). "It's all lock-free, don't worry about it" might be
easier, but I consider SDL's approach of just providing a mutex to
prevent the output callback from running while you mutate the sound state to
actually be simpler conceptually.
🟡 miniaudio adds 247 KB to the binary in its minimum
configuration, a bit more than expected. Some of that is bloat from effect
code that we never use, but it does include backends for all three Windows
audio subsystems (WASAPI, DirectSound, and WinMM).
✅ But perhaps most importantly: It natively supports all modern
operating systems that one could seriously want to port this game to, and
could be easily ported to any other backend, including
SDL.
Oh, and it's written by the same developer who also wrote the best FLAC
library back in 2018. And that's despite them being single-file C libraries,
which I consider to be massively overrated…
The drawback? Similar to Zig, it's only on version 0.11.18, and also focuses
on good high-level documentation at the expense of an API reference. Unlike
Zig though, the three issues I ran into turned out to be actual and fixable
bugs: Two minor
ones related to looping of streamed sounds shorter than 2 seconds which
won't ever actually affect us before we get into BGM modding, and a critical one that
added high-frequency corruption to any mono sound effect during its
expansion to stereo. The latter took days to track down – with symptoms
like these, you'd immediately suspect the bug to lie in the resampler or its
low-pass filter, both of which are so much more of a fickle and configurable
part of the conversion chain here. Compared to that, stereo expansion is so
conceptually simple that you wouldn't imagine anyone getting it wrong.
While the latter PR has been merged, the fix is still only part of the
dev branch and hasn't been properly released yet. Fortunately,
raylib is not affected by this bug: It does currently
ship version 0.11.16 of miniaudio, but its usage of the library predates
miniaudio's high-level API and it therefore uses a different,
non-SSE-optimized code path for its format conversions.
The only slightly tricky part of implementing a miniaudio backend for
Shuusou Gyoku lies in setting up multiple simultaneously playing instances
for each individual sound. The documentation and answers on the issue
tracker heavily push you toward miniaudio's resource manager and its file
abstractions to handle this use case. We surely could turn Shuusou Gyoku's
numeric sound effect IDs into fake file names, but it doesn't really fit the
existing architecture where the sound interface just receives in-memory .WAV
file buffers loaded from the SOUND.DAT packfile.
In that case, this seems to be the best way:
Call ma_decode_memory() to decode from any of the supported
audio formats to a buffer of raw PCM samples. At this point, you can
choose between
decoding into the original format the sound effect is stored in,
which would require it to be converted to the playback format every
time it's played, or
decoding into 32-bit floats (the native bit depth of the miniaudio
engine) and the native sampling rate of the playback device, which
avoids any further resampling and floating-point conversion, but takes
up more memory.
Nowadays, it's not clear at all which of the two approaches is faster.
Does it actually matter if we save the audio thread from doing all those
floating-point operations on every sample? Or is that no longer true these
days because the audio thread is probably running on a different CPU core,
the rest of the game largely doesn't touch the floating-point parts of your
CPU anyway, and you'd rather want to keep sound effects small so that they
can better fit into the CPU cache? That would be an interesting question to
benchmark, but just like the similar text rendering question from the last
blog posts, it doesn't matter for this tiny 2000s retro game. 😌
I went with 2) mainly because it simplified all the debugging I was doing.
At a sampling rate of 48,000 Hz, this increases the memory usage for
all sound effects from 379 KiB to 3.67 MiB. At least I'm not
channel-expanding all sound effects as well here…
We've seen earlier that mono➜stereo expansion
is SSE-optimized, so it's very hard to justify a further doubling of the
memory usage here.
Then, for each instance of the sound, call
ma_audio_buffer_ref_init() to create a reference
buffer with its own playback cursor, and
ma_sound_init_from_data_source() to create a new
high-level sound node that will play back the reference buffer.
As a side effect of hunting that one critical bug in miniaudio, I've now
learned a fair bit about audio resampling in general. You'll probably need
some knowledge about basic
digital signal behavior to follow this section, and that video is still
probably the best introduction to the topic.
So, how could this ever be an issue? The only time I ever consciously
thought about resampling used to be in the context of the Opus codec and its
enforced sampling rate of 48,000 Hz, and how Opus advocates
claim that resampling is a solved problem and nothing to worry about,
especially in the context of a lossy codec. Still, I didn't add Opus to
thcrap's BGM modding feature entirely because the mere thought of having to
downsample to 44,100 Hz in the decoder was off-putting enough. But even
if my worries were unfounded in that specific case: Recording the
Stereo Mix of Shuusou Gyoku's now two audio backends revealed that
apparently not every audio processing chain features an Opus-quality
resampler…
If we take a look at the material that resamplers actually have to work with
here, it quickly becomes obvious why their results are so varied. As
mentioned above, Shuusou Gyoku's sound effects use rather low sampling rates
that are pretty far away from the 48,000 Hz your audio device is most
definitely outputting. Therefore, any potential imaging noise across the
extended high-frequency range – i.e., from the original Nyquist frequencies
of 11,025 Hz/5,512.5 Hz up to the new limit of 24,000 Hz – is
still within the audible range of most humans and can clearly color the
resulting sound.
But it gets worse if the audio data you put into the resampler is
objectively defective to begin with, which is exactly the problem we're
facing with over half of Shuusou Gyoku's sound effects. Encoding them all as
8-bit PCM is definitely excusable because it was the turn of the millennium
and the resulting noise floor is masked by the BGM anyway, but the blatant
clipping and DC offsets definitely aren't:
KEBARI
TAME
LASER
LASER2
BOMB
SELECT
HIT
CANCEL
WARNING
SBLASER
BUZZ
MISSILE
JOINT
DEAD
SBBOMB
BOSSBOMB
ENEMYSHOT
HLASER
TAMEFAST
WARP
Waveforms for all 20 of Shuusou Gyoku's sound effects, in the order they
appear inside SOUND.DAT and with their internal names. We can
see quite an abundance of clipping, as well
as a significant DC
offset in WARNING, BUZZ, JOINT,
SBBOMB, and BOSSBOMB.
Wait a moment, true peaks? Where do those come from? And, equally
importantly, how can we even observe, measure, and store anything
above the maximum amplitude of a digital signal?
The answer to the first question can be directly derived from the Xiph.org
video I linked above: Digital signals are lollipop graphs, not stairsteps as
commonly depicted in audio editing software. Converting them back to an
analog signal involves constructing a continuous curve that passes through
each sample point, and whose frequency components stay below the Nyquist
frequency. And if the amplitude of that reconstructed wave changes too
strongly and too rapidly, the resulting curve can easily overshoot the
maximum digital amplitude of 0
dBFS even if none of the defined samples are above that limit.
So let's store the resampled output as a FLAC file and load it into Audacity
to visualize the clipped peaks… only to find all of them replaced with the
typical kind of clipping distortion? 😕 Turns out that I've stumbled over
the one case where the FLAC format isn't lossless and there's
actually no alternative to .WAV: FLAC just doesn't support
floating-point samples and simply truncates them to discrete integers during
encoding. When we measured inter-sample peaks above, we weren't only
resampling to a floating-point format to avoid any quantization to discrete
integer values, but also to make it possible to store amplitudes beyond the
0 dBFS point of ±1.0 in the first place. Once we lose that ability,
these amplitudes are clipped to the maximum value of the integer bit depth,
and baked into the waveform with no way to get rid of them again. After all,
the resampled file now uses a higher sampling rate, and the clipping
distortion is now a defined part of what the sound is.
Finally, storing a digital signal with inter-sample peaks in a
floating-point format also makes it possible for you to reduce the
volume, which moves these peaks back into the regular, unclipped amplitude
range. This is especially relevant for Shuusou Gyoku as you'll probably
never listen to sound effects at full volume.
Now that we understand what's going on there, we can finally compare the
output of various resamplers and pick a suitable one to use with miniaudio.
And immediately, we see how they fall into two categories:
High-quality resamplers are the ones I described earlier: They cleanly
recreate the signal at a higher sampling rate from its raw frequency
representation and thus add no high-frequency noise, but can lead to
inter-sample peaks above 0 dBFS.
Linear resamplers use much simpler math to merely interpolate
between neighboring samples. Since the newly interpolated samples can only
ever stay within 0 dBFS, this approach fully avoids inter-sample
clipping, but at the expense of adding high-frequency imaging noise that has
to then be removed using a low-pass filter.
miniaudio only comes with a linear resampler – but so does DirectSound as it
turns out, so we can get actually pretty close to how the game sounded
originally:
All of Shuusou Gyoku's sound effects combined and resampled into a
single 48,000 Hz / 32-bit float .WAV file, using GoldWave's File Merger tool. By
converting to 32-bit float first and then resampling, the
conversion preserved the exact frequency range of the original
22,050 Hz and 11,025 Hz files, even despite clipping. There
are small noise peaks across the entire frequency range, but they
only occur at the exact boundary between individual sound effects. These
are a simple result of the discontinuities that naturally occur in the
waveform when concatenating signals that don't start or end at a 0
sample.
As mentioned above, you'll only get this sound out of your DAC at lower
volumes where all of the resampled peaks still fit within 0 dBFS.
But you most likely will have reduced your volume anyway, because these
effects would be ear-splittingly loud otherwise.
The result of converting 1️⃣ into FLAC. The necessary bit depth
conversion from 32-bit float to 16-bit integers clamps any data above
0 dBFS or ±1.0f to the discrete
-32,67832,767, the maximum value of such
an integer. The resulting straight lines at maximum amplitude in the
time domain then turn into distortion across the entire 24,000 Hz
frequency domain, which then remains a part of the waveform even at
lower volumes. The locations of the high-frequency noise exactly match
the clipped locations in the time-domain waveform images above.
The resulting additional distortion can be best heard in
BOSSBOMB, where the low source frequency ensures that any
distortion stays firmly within the hearing range of most humans.
All of Shuusou Gyoku's sound effects as played through DirectSound and
recorded through Stereo Mix. DirectSound also seems to use a linear
low-pass filter that leaves quite a bit of high-frequency noise in the
signals, making these effects sound crispier than they should be.
Depending on where you stand, this is either highly inaccurate and
something that should be fixed, or actually good because the sound
effects really benefit from that added high end. I myself am definitely
in the latter camp – and hey, this sound is the result of original game
code, so it is accurate at least in that regard.
All of Shuusou Gyoku's sound effects as converted by miniaudio and
directly saved to a file, with the same low-pass filter setting used in
the P0256 build. This first-order low-pass filter is a decent
approximation of DirectSound's resampler, even though it sounds slightly
crispier as the high-frequency noise is boosted a little further. By
default, miniaudio would use a 4th-order low-pass filter, so
this is the second-lowest resampling quality you can get, short of
disabling the low-pass filter altogether.
Conversion results when using miniaudio's 8th-order low-pass
filter for resampling, the highest quality supported. This is the
closest we can get to the reference conversion without using a custom
resampler. If we do want to go for perfect accuracy though, we might as
well go
for 1️⃣ directly?
These spectrum images were initially created using ffmpeg's -lavfi
showspectrumpic=mode=combined:s=1280x720 filter. The samples
appear in the same order as in the waveform above.
And yes, these are indeed the first videos on this blog to have sound! I
spent another push on preparing the
📝 video conversion pipeline for audio
support, and on adding the highly important volume control to the player.
Web video codecs only support lossy audio, so the sound in these videos will
not exactly match the spectrum image, but the lossless source files do
contain the original audio as uncompressed PCM streams.
Compared to that whole mess of signals and noise, keyboard and joypad input
is indeed much simpler. Thanks to SDL, it's almost trivial, and only
slightly complicated because SDL offers two subsystems with seemingly
identical APIs:
SDL_GameController provides a consistent interface for the typical kind
of modern gamepad with two analog sticks, a D-pad, and at least 4 face and 2
shoulder buttons. This API is implemented by simply combining SDL_Joystick
with a
long list of mappings for specific controllers, and therefore doesn't
work with joypads that don't match this standard.
According
to SDL, this is what a "game controller" looks like. Here's
the source of the SVG.
To match Shuusou Gyoku's original WinMM backend, we'd ideally want to keep
the best aspects from both APIs but without being restricted to
SDL_GameController's idea of a controller. The Joy
Pad menu just identifies each button with a numeric ID, so
SDL_Joystick would be a natural fit. But what do we do about directional
controls if SDL_Joystick doesn't tell us which joypad axes correspond to the
X and Y directions, and we don't have the SDL-recommended configuration UI yet?
Doing that right would also mean supporting
POV hats and D-pads, after all… Luckily, all joypads we've tested map
their main X axis to ID 0 and their main Y axis to ID 1, so this seems like
a reasonable default guess.
The necessary consolidation of the game's original input handling uncovered
several minor bugs around the High Score and Game Over screen that I
sufficiently described in the release notes of the new build. But it also
revealed an interesting detail about the Joy Pad
screen: Did you know that Shuusou Gyoku lets you unbind all these
actions by pressing more than one joypad button at the same time? The
original game indicated unbound actions with a [Button
0] label, which is pretty confusing if you have ever programmed
anything because you now no longer know whether the game starts numbering
buttons at 0 or 1. This is now communicated much more clearly.
ESC is not bound to any joypad button in
either screenshot, but it's only really obvious in the P0256
build.
With that, we're finally feature-complete as far as this delivery is
concerned! Let's send a build over to the backers as a quick sanity check…
a~nd they quickly found a bug when running on Linux and Wine. When holding a
button, the game randomly stops registering directional inputs for a short
while on some joypads? Sounds very much like a Wine bug, especially if the
same pad works without issues on Windows.
And indeed, on certain joypads, Wine maps the buttons to completely
different and disconnected IDs, as if it simply invents new buttons or axes
to fill the resulting gaps. Until we can differentiate joypad bindings
per controller, it's therefore unlikely that you can use the same joypad
mapping on both Windows and Linux/Wine without entering the Joy Pad menu and remapping the buttons every time you
switch operating systems.
Still, by itself, this shouldn't cause any issues with my SDL event handling
code… except, of course, if I forget a break; in a switch case.
🫠
This completely preventable implicit fallthrough has now caused a few hours
of debugging on my end. I'd better crank up the warning level to keep this
from ever happening again. Opting into this specific warning also revealed
why we haven't been getting it so far: Visual Studio did gain a whole host
of new warnings related to the C++ Core
Guidelines a while ago, including the one I
was looking for, but actually getting the compiler to throw these
requires activating
a separate static analysis mode together with a plugin, which
significantly slows down build times. Therefore I only activate them for
release builds, since these already take long enough.
Since all that input debugging already started a 5th push, I
might as well fill that one by restoring the original screenshot feature.
After all, it's triggered by a key press (and is thus related to the input
backend), reads the contents of the frame buffer (and is thus related to the
graphics backend), and it honestly looks bad to have this disclaimer in the
release notes just because we're one small feature away from 100% parity
with pbg's original binary.
Coincidentally, I had already written code to save a DirectDraw surface to a
.BMP file for all the debugging I did in the last delivery, so we were
basically only missing filename generation. Except that Shuusou
Gyoku's original choice of mapping screenshots to the PrintScreen key did
not age all too well:
And as of Windows 11, the OS takes full control of the key by binding it
to the Snipping Tool by default, complete with a UI that politely steals
focus when hitting that key.
As a result, both Arandui and I independently arrived at the
idea of remapping screenshots to the P key, which is the same screenshot key
used by every Windows Touhou game since TH08.
The rest of the feature remains unchanged from how it was in pbg's original
build and will save every distinct frame rendered by the game (i.e., before
flipping the two framebuffers) to a .BMP file as long as the P key is being
held. At a 32-bit color depth, these screenshots take up 1.2 MB per
frame, which will quickly add up – especially since you'll probably hold the
P key for more than 1/60 of a second and therefore end
up saving multiple frames in a row. We should probably compress
them one day.
Since I already translated some of Shuusou Gyoku's ASM code to C++ during
the Zig experiment, it made sense to finish the fifth push by covering the
rest of those functions. The integer math functions are used all throughout
the game logic, and are the main reason why this goal is important for a
Linux port, or any port to a 64-bit architecture for that matter. If you've
ever read a micro-optimization-related blog post, you'll know that hand-written ASM is a great recipe that often results in the finest jank, and the game's square root function definitely delivers in that regard, right out of the gate.
What slightly differentiates this algorithm from the typical definition of
an integer
square root is that it rounds up: In real numbers, √3 is
≈ 1.73, so isqrt(3) returns 2 instead of 1. However, if
the result is always rounded down, you can determine whether you have to
round up by simply squaring the calculated root and comparing it to the radicand. And even that
is only necessary if the difference between the two doesn't naturally fall
out of the algorithm – which is what also happens with Shuusou Gyoku's
original ASM code, but pbg
didn't realize this and squared the result regardless.
That's one suboptimal detail already. Let's call the original ASM function
in a loop over the entire supported range of radicands from 0 to
231 and produce a list of results that I can verify my C++
translation against… and watch as the function's linear time complexity with
regard to the radicand causes the loop to run for over 15 hours on my
system. 🐌 In a way, I've found the literal opposite of Q_rsqrt()
here: Not fast, not inverse, no bit hacks, and surely without the
awe-inspiring kind of WTF.
I really didn't want to run the same loop over a
literal C++ translation of the same algorithm afterward. Calculating
integer square roots is a common problem with lots of solutions, so let's
see if we can go better than linear.
And indeed, Wikipedia
also has a bitwise algorithm that runs in logarithmic time, uses only
additions, subtractions, and bit shifts, and even ends up with an error term
that we can use to round up the result as necessary, without a
multiplication. And this algorithm delivers the exact same results over the
exact same range in… 50 seconds. 🏎️ And that's with the I/O to print
the first value that returns each of the 46,341 different square root
results.
"But wait a moment!", I hear you say. "Why are you bothering with
an integer square root algorithm to begin with? Shouldn't good old
round(sqrt(x)) from <math.h> do the trick
just fine? Our CPUs have had SSE for a long time, and this probably compiles
into the single SQRTSD instruction. All that extra
floating-point hardware might mean that this instruction could even run in
parallel with non-SSE code!"
And yes, all of that is technically true. So I tested it, and my very
synthetic and constructed micro-benchmark did indeed deliver the same
results in… 48 seconds. That's not enough of a
difference to justify breaking the spirit of treating the FPU as lava that
permeates Shuusou Gyoku's code base. Besides, it's not used for that much to
begin with:
pre-calculating the 西方Project lens ball effect
the fade animation when entering and leaving stages
rendering the circular part of stationary lasers
pulling items to the player when bombing
After a quick C++ translation of the RNG function that spells out a 32-bit
multiplication on a 32-bit CPU using 16-bit instructions, we reach the final
pieces of ASM code for the 8-bit atan2() and trapezoid
rendering. These could actually pass for well-written ASM code in how they
express their 64-bit calculations: atan8() prepares its 64-bit
dividend in the combined EDX and EAX registers in
a way that isn't obvious at all from a cursory look at the code, and the
trapezoid functions effectively use Q32.32 subpixels. C++ allows us to
cleanly model all these calculations with 64-bit variables, but
unfortunately compiles the divisions into a call to a comparatively much
more bloated 64-bit/64-bit-division polyfill function. So yeah, we've
actually found a well-optimized piece of inline assembly that even Visual
Studio 2022's optimizer can't compete with. But then again, this is all
about code generation details that are specific to 32-bit code, and it
wouldn't be surprising if that part of the optimizer isn't getting much
attention anymore. Whether that optimization was useful, on the other hand…
Oh well, the new C++ version will be much more efficient in 64-bit builds.
And with that, there's no more ASM code left in Shuusou Gyoku's codebase,
and the original DirectXUTYs directory is slowly getting
emptier and emptier.
Phew! Was that everything for this delivery? I think that was everything.
Here's the new build, which checks off 7 of the 15 remaining portability
boxes:
Next up: Taking a well-earned break from Shuusou Gyoku and starting with the
preparations for multilingual PC-98 Touhou translatability by looking at
TH04's and TH05's in-game dialog system, and definitely writing a shorter
blog post about all that…
Thanks to handlerug for
implementing and PR'ing the feature in a very clean way. That makes at least
two people I know who wanted to see feed support, so there are probably
a few more out there.
So, Shuusou Gyoku. pbg released the original source code for the first two
Seihou games back in February 2019, but notably removed the crucial
decompression code for the original packfiles due to… various unspecified
reasons, considerations, and implications. This vague
language and subsequent rejection of a pull request
to add these features back in were probably the main reasons why no one
has publicly done anything with this codebase since.
The only other fork I know about is Priw8's private fork from 2020, but only
because WishMakers
informed me about it shortly after this push was funded. Both of them
might also contribute some features to my fork in the future if their time
allows it.
In this fork, Priw8 replaced packfile decompression with raw reads from
directories with the pre-extracted contents of all the .DAT files. This
works for playing the game, but there are actually two more things that
require the original packfile code:
High scores are stored as a bitstream with every variable separated by
an alternating 0 or 1 bit, using the same bit-level access functions as the
packfile reader. That's a quite… unique form of obfuscation: It requires way
too much code to read and write the format, and doesn't even obfuscate the
data that well because you can still see clear patterns when opening
these scorefiles in a hex editor.
Replays are 2-"file" archives compressed using the same algorithm as the
packfile. The first "file" contains metadata like the shot type, stage, and
RNG seed, and the second one contains the input state for every frame.
We can surely implement our own simple and uncompressed formats for these
things, but it's not the best idea to build all future Shuusou Gyoku
features on top of a replay-incompatible fork. So, what do we do? On the one
hand, pbg expressed the clear wish to not include data reverse-engineered
from the original binary. On the other hand, he released the code under the
MIT license, which allows us to modify the code and distribute the results
in any way we wish.
So, let's meet in the middle, and go for a clean-room implementation of the
missing features as indicated by their usage, without looking at either the
original binary or wangqr's reverse-engineered code.
With incremental rebuilds being broken in the latest Visual Studio project
files as well, it made sense to start from scratch on pbg's last commit. Of
course, I can't pass up a chance to use
📝 Tup, my favorite build system for every
project I'm the main developer of. It might not fit Shuusou Gyoku as well as
it fits ReC98, but let's see whether it would be reasonable at all…
… and it's actually not too bad! Modern Visual Studio makes this a bit
harder than it should be with all the intermediate build artifacts you have
to keep track of. In the end though, it's still only 70
lines of Lua to have a nice abstraction for both Debug and Release
builds. With this layer underneath, the actual
Shuusou Gyoku-specific part can be expressed as succinctly as in any
other modern build system, while still making every compiler flag explicit.
It might be slightly slower than a traditional .vcxproj build
due to launching
one cl.exe process per translation unit, but the result is
way more reliable and trustworthy compared to anything that involves Visual
Studio project files. This simplicity paves the way for expanding the build
process to multiple steps, and doing all the static checking on translation
strings that I never got to do for thcrap-based patches. Heck, I might even
compile all future translations directly into the binary…
Every C++ build system will invariably be hated by someone, so I'd
say that your goal should always be to simplify the actually important parts
of your build enough to allow everyone else to easily adapt it to their
favorite system. This Tupfile definitely does a better job there than your
average .vcxproj file – but if you still want such a thing (or,
gasp, 🤮 CMake project files 🤮) for better Visual Studio IDE
integration, you should have no problem generating them for yourself.
There might still be a point in doing that because that's the one part that
unfortunately sucks about this approach. Visual Studio is horribly broken
for any nonstandard C++ project even in 2022:
Makefile projects can be nicely integrated with Debug and Release
configurations, but setting a later C++ language standard requires dumb
.vcxproj hacks that don't even work properly anymore.
Folder projects are ridiculously ugly: The Build toolbar is permanently
grayed out even if you configured a build task. For some reason,
configuring these tasks merely adds one additional element to a 9-element
context menu in the Solution Explorer. Also, why does the big IDE use a
different JSON schema than the perfectly functional and adequate one from
Visual Studio Code?
In both cases, IntelliSense doesn't work properly at all even if it
appears to be configured correctly, and Tup's dependency tracking appeared
to be weirdly cut off for the very final .PDB file. Interestingly though,
using the big Visual Studio IDE for just debugging a binary via
devenv bin/GIAN07.exe suddenly eliminates all the IntelliSense
issues. Looks like there's a lot of essential information stored in the .PDB
files that Visual Studio just refuses to read in any other context.
But now compare that to Visual Studio Code: Open it from the x64_x86
Cross Tools Command Prompt via code ., launch a build or
debug task, or browse the code with perfect IntelliSense. Three small
configuration files and everything just works – heck, you even get the Tup
progress bar in the terminal. It might be Electron bloatware and horribly
slow at times, but Visual Studio Code has long outperformed regular Visual
Studio in terms of non-debug functionality.
On to the compression algorithm then… and it's just textbook LZSS,
with 13 bits for the offset of a back-reference and 4 bits for its length?
Hardly a trade secret there. The hard parts there all come from unexpected
inefficiencies in the bitstream format:
Encoding back-references as offsets into an 8 KiB ring buffer dictionary
means that the most straightforward implementation actually needs an 8 KiB
array for the LZSS sliding window. This could have easily been done with
zero additional memory if the offset was encoded as the difference to the
current byte instead.
The packfile format stores the uncompressed size of every file in its
header, which is a good thing because you want to know in advance how much
heap memory to allocate for a specific file. Nevertheless, the original game
only stops reading bits from the packfile once it encountered a
back-reference with an offset of 0. This means that the compressor not only
has to write this technically unneeded back-reference to the end of the
compressed bitstream, but also ignore any potential other longest
back-reference with an offset of 0 within the file. The latter can
easily happen with a ring buffer dictionary.
The original game used a single BIT_DEVICE class with mode
flags for every combination of reading and writing memory buffers and
on-disk files. Since that would have necessitated a lot of error checking
for all (pseudo-)methods of this class, I wrote one dedicated small class
for each one of these permutations instead. To further emphasize the
clean-room property of this code, these use modern C++ memory ownership
features: std::unique_ptr for the fixed-size read-only buffers
we get from packfiles, std::vector for the newly compressed
buffers where we don't know the size in advance, and std::span
for a borrowed reference to an immutable region of memory that we want to
treat as a bitstream. Definitely better than using the native Win32
LocalAlloc() and LocalFree() allocator, especially
if we want to port the game away from Windows one day.
One feature I didn't use though: C++ fstreams, because those are trash.
These days, they would seem to be the natural
choice with the new std::filesystem::path type from C++17:
Correctly constructed, you can pass that type to an fstream constructor and
gain both locale independence on Windows and portability to
everything else, without writing any Windows-specific UTF-16 code. But even
in a Release build, fstreams add ~100 KB of locale-related bloat to the .EXE
which adds no value for just reading binary files. That's just too
embarrassing if you look at how much space the rest of the game takes up.
Writing your own platform layer that calls the Win32
CreateFileW(), ReadFile(), and
WriteFile() API functions is apparently still the way to go
even in 2022. And with std::filesystem::path still being a
welcome addition to C++, it's not too much code to write either.
This gets us file format compatibility with the original release… and a
crash as soon as the ending starts, but only in Release mode? As it turns
out, this crash is caused by an
out-of-boundsarray
access bug that was present even in the original game, and only turned
into a crash now because the optimizer in modern Visual Studio versions
reorders static data. As a result, the 6-element pFontInfo
array got placed in front of an ECL-related counter variable that then got
corrupted by the write to the 7th element, which subsequently
crashed the game with a read access to previously deallocated danmaku script
data. That just goes to show that these technical bugs are important
and worth fixing even if they don't cause issues in the original game. Who
knows how many of these will turn into crashes once we get to porting PC-98
Touhou?
So here we go, a new build of Shuusou Gyoku, compiled with Visual Studio
2022, and compatible with all original data formats:
Inside the regular Shuusou Gyoku installation directory, this binary works
as a full-fledged drop-in replacement for the original
秋霜玉.exe. It still has all of the original binary's problems
though:
Separate Japanese locale emulation is still needed to correctly refer to
the original names of the configuration (秋霜CFG.DAT), score
(秋霜SC.DAT), and replay (秋霜りぷ*.DAT) files.
It's also required for the ending text to not render as mojibake.
Running the game at full speed and without graphical glitches on modern
Windows still requires a separate DirectDraw patch such as DDrawCompat. To
eliminate any remaining flickering, configure the game to use 16-bit
graphics in the Config → Graphic menu.
As well as some of its own:
The original screenshot feature is still missing, as it also wasn't part
of pbg's released source code.
So all in all, it's a strict downgrade at this point in time.
And more of a symbol that we can now start
doing actual work on this game. Seihou has been a fun change of pace, and I
hope that I get to do more work on the series. There is quite a lot to be
done with Shuusou Gyoku alone, and the 21 GitHub issues I've opened
are probably only scratching the surface.
However, all the required research for this one consumed more like 1⅔
pushes. Despite just one push being funded, it wouldn't have made sense to
release the commits or this binary in any earlier state. To repay this debt,
I'm going to put the next for Seihou towards the
small code maintenance and performance tasks that I usually do for free,
before doing any more feature and bugfix work. Next up: Improving video
playback on the blog, and maybe delivering some microtransaction work on the
side?
Whoops, the build was broken again? Since
P0127 from
mid-November 2020, on TASM32 version 5.3, which also happens to be the
one in the DevKit… That version changed the alignment for the default
segments of certain memory models when requesting .386
support. And since redefining segment alignment apparently is highly
illegal and absolutely has to be a build error, some of the stand-alone
.ASM translation units didn't assemble anymore on this version. I've only
spotted this on my own because I casually compiled ReC98 somewhere else –
on my development system, I happened to have TASM32 version 5.0 in the
PATH during all this time.
At least this was a good occasion to
get rid of some
weird segment alignment workarounds from 2015, and replace them with the
superior convention of using the USE16 modifier for the
.MODEL directive.
ReC98 would highly benefit from a build server – both in order to
immediately spot issues like this one, and as a service for modders.
Even more so than the usual open-source project of its size, I would say.
But that might be exactly
because it doesn't seem like something you can trivially outsource
to one of the big CI providers for open-source projects, and quickly set
it up with a few lines of YAML.
That might still work in the beginning, and we might get by with a regular
64-bit Windows 10 and DOSBox running the exact build tools from the DevKit.
Ideally, though, such a server should really run the optimal configuration
of a 32-bit Windows 10, allowing both the 32-bit and the 16-bit build step
to run natively, which already is something that no popular CI service out
there offers. Then, we'd optimally expand to Linux, every other Windows
version down to 95, emulated PC-98 systems, other TASM versions… yeah, it'd
be a lot. An experimental project all on its own, with additional hosting
costs and probably diminishing returns, the more it expands…
I've added it as a category to the order form, let's see how much interest
there is once the store reopens (which will be at the beginning of May, at
the latest). That aside, it would 📝 also be
a great project for outside contributors!
So, technical debt, part 8… and right away, we're faced with TH03's
low-level input function, which
📝 once📝 again📝 insists on being word-aligned in a way we
can't fake without duplicating translation units.
Being undecompilable isn't exactly the best property for a function that
has been interesting to modders in the past: In 2018,
spaztron64 created an
ASM-level mod that hardcoded more ergonomic key bindings for human-vs-human
multiplayer mode: 2021-04-04-TH03-WASD-2player.zip
However, this remapping attempt remained quite limited, since we hadn't
(and still haven't) reached full position independence for TH03 yet.
There's quite some potential for size optimizations in this function, which
would allow more BIOS key groups to already be used right now, but it's not
all that obvious to modders who aren't intimately familiar with x86 ASM.
Therefore, I really wouldn't want to keep such a long and important
function in ASM if we don't absolutely have to…
… and apparently, that's all the motivation I needed? So I took the risk,
and spent the first half of this push on reverse-engineering
TCC.EXE, to hopefully find a way to get word-aligned code
segments out of Turbo C++ after all.
And there is! The -WX option, used for creating
DPMI
applications, messes up all sorts of code generation aspects in weird
ways, but does in fact mark the code segment as word-aligned. We can
consider ourselves quite lucky that we get to use Turbo C++ 4.0, because
this feature isn't available in any previous version of Borland's C++
compilers.
That allowed us to restore all the decompilations I previously threw away…
well, two of the three, that lookup table generator was too much of a mess
in C. But what an abuse this is. The
subtly different code generation has basically required one creative
workaround per usage of -WX. For example, enabling that option
causes the regular PUSH BP and POP BP prolog and
epilog instructions to be wrapped with INC BP and
DEC BP, for some reason:
a_function_compiled_with_wx proc
inc bp ; ???
push bp
mov bp, sp
; [… function code …]
pop bp
dec bp ; ???
ret
a_function_compiled_with_wx endp
Luckily again, all the functions that currently require -WX
don't set up a stack frame and don't take any parameters.
While this hasn't directly been an issue so far, it's been pretty
close: snd_se_reset(void) is one of the functions that require
word alignment. Previously, it shared a translation unit with the
immediately following snd_se_play(int new_se), which does take
a parameter, and therefore would have had its prolog and epilog code messed
up by -WX.
Since the latter function has a consistent (and thus, fakeable) alignment,
I simply split that code segment into two, with a new -WX
translation unit for just snd_se_reset(void). Problem solved –
after all, two C++ translation units are still better than one ASM
translation unit. Especially with all the
previous #include improvements.
The rest was more of the usual, getting us 74% done with repaying the
technical debt in the SHARED segment. A lot of the remaining
26% is TH04 needing to catch up with TH03 and TH05, which takes
comparatively little time. With some good luck, we might get this
done within the next push… that is, if we aren't confronted with all too
many more disgusting decompilations, like the two functions that ended this
push.
If we are, we might be needing 10 pushes to complete this after all, but
that piece of research was definitely worth the delay. Next up: One more of
these.
Alright, tooling and technical debt. Shouldn't be really much to talk
about… oh, wait, this is still ReC98
For the tooling part, I finished up the remaining ergonomics and error
handling for the
📝 sprite converter that Jonathan Campbell contributed two months ago.
While I familiarized myself with the tool, I've actually ran into some
unreported errors myself, so this was sort of important to me. Still got
no command-line help in there, but the error messages can now do that job
probably even better, since we would have had to write them anyway.
So, what's up with the technical debt then? Well, by now we've accumulated
quite a number of 📝 ASM code slices that
need to be either decompiled or clearly marked as undecompilable. Since we
define those slices as "already reverse-engineered", that decision won't
affect the numbers on the front page at all. But for a complete
decompilation, we'd still have to do this someday. So, rather than
incorporating this work into pushes that were purchased with the
expectation of measurable progress in a certain area, let's take the
"anything goes" pushes, and focus entirely on that during them.
The second code segment seemed like the best place to start with this,
since it affects the largest number of games simultaneously. Starting with
TH02, this segment contains a set of random "core" functions needed by the
binary. Image formats, sounds, input, math, it's all there in some
capacity. You could maybe call it all "libzun" or something like
that? But for the time being, I simply went with the obvious name,
seg2. Maybe I'll come up with something more convincing in
the future.
Oh, but wait, why were we assembling all the previous undecompilable ASM
translation units in the 16-bit build part? By moving those to the 32-bit
part, we don't even need a 16-bit TASM in our list of dependencies, as
long as our build process is not fully 16-bit.
And with that, ReC98 now also builds on Windows 95, and thus, every 32-bit
Windows version. 🎉 Which is certainly the most user-visible improvement
in all of these two pushes.
Back in 2015, I already decompiled all of TH02's seg2
functions. As suggested by the Borland compiler, I tried to follow a "one
translation unit per segment" layout, bundling the binary-specific
contents via #include. In the end, it required two
translation units – and that was even after manually inserting the
original padding bytes via #pragma codestring… yuck. But it
worked, compiled, and kept the linker's job (and, by extension,
segmentation worries) to a minimum. And as long as it all matched the
original binaries, it still counted as a valid reconstruction of ZUN's
code.
However, that idea ultimately falls apart once TH03 starts mixing
undecompilable ASM code inbetween C functions. Now, we officially have no
choice but to use multiple C and ASM translation units, with maybe only
just one or two #includes in them…
…or we finally start reconstructing the actual seg2 library,
turning every sequence of related functions into its own translation unit.
This way, we can simply reuse the once-compiled .OBJ files for all the
binaries those functions appear in, without requiring that additional
layer of translation units mirroring the original segmentation.
The best example for this is
TH03's
almost undecompilable function that generates a lookup table for
horizontally flipping 8 1bpp pixels. It's part of every binary since
TH03, but only used in that game. With the previous approach, we would
have had to add 9 C translation units, which would all have just
#included that one file. Now, we simply put the .OBJ file
into the correct place on the linker command line, as soon as we can.
💡 And suddenly, the linker just inserts the correct padding bytes itself.
The most immediate gains there also happened to come from TH03. Which is
also where we did get some tiny RE% and PI% gains out of this after
all, by reverse-engineering some of its sprite blitting setup code. Sure,
I should have done even more RE here, to also cover those 5 functions at
the end of code segment #2 in TH03's MAIN.EXE that were in
front of a number of library functions I already covered in this push. But
let's leave that to an actual RE push 😛
All in all though, I was just getting started with this; the real
gains in terms of removed ASM files are still to come. But in the
meantime, the funding situation has become even better in terms of
allowing me to focus on things nobody asked for. 🙂 So here's a slightly
better idea: Instead of spending two more pushes on this, let's shoot for
TH05 MAINE.EXE position independence next. If I manage to get
it done, we'll have a 100% position-independent TH05 by the time
-Tom- finishes his MAIN.EXE PI demo, rather
than the 94% we'd get from just MAIN.EXE. That's bound to
make a much better impression on all the people who will then
(re-)discover the project.
(tl;dr: ReC98 has switched to Tup for
the 32-bit build. You probably want to get
💾 this build of Tup, and put it somewhere in your
PATH. It's optional, and always will be, but highly
recommended.)
P0001! Reserved for the delivery of the very first financial contribution
I've ever received for ReC98, back in January 2018. GhostPhanom
requested the exact opposite of immediate results, which motivated me to
go on quite a passionate quest for the perfect ReC98 build system. A quest
that went way beyond the crowdfunding…
Makefiles are a decent idea in theory: Specify the targets to generate,
the source files these targets depend on and are generated from, and the
rules to do the generating, with some helpful shorthand syntax. Then, you
have a build dependency graph, and your make tool of choice
can provide minimal rebuilds of only the targets whose sources changed
since the last make call. But, uh… wait, this is C/C++ we're
talking about, and doesn't pretty much every source file come with a
second set of dependent source files, namely, every single
#include in the source file itself? Do we really
have to duplicate all these inside the Makefile, and keep it in sync with the source file? 🙄
This fact alone means that Makefiles are inherently unsuited for
any language with an #include feature… that is, pretty
much every language out there. Not to mention other aspects like changes
to the compilation command lines, or the build rules themselves, all of
which require metadata of the previous build to be persistently stored in
some way. I have no idea why such a trash technology is even touted as a
viable build tool for code.
So, I decided to just
write my own build system, tailor-made for the needs of ReC98's 16-bit
build process, and combining a number of experimental ideas. Which is
still not quite bug-free and ready for public use, given that the
entire past year has kept me busy with actual tangible RE and PI progress.
What did finally become ready, however, is the improvement for the
32-bit build part, and that's what we've got here.
💭 Now, if only there was a build system that would perfectly track
dependencies of any compiler it calls, by injecting code and
hooking file opening syscalls. It'd be completely unrealistic for it to
also run on DOS (and we probably don't want to traverse a graph database
in a cycle-limited DOSBox), but it would be perfect for our 32-bit build
part, as long as that one still exists.
Sure, it might seem really minor to worry about not unconditionally
rebuilding all 32-bit .asm files, which just takes a couple
of seconds anyway. But minimal rebuilds in the 32-bit part also provide
the foundation for minimal rebuilds in the 16-bit part – and those
TLINK invocations do take quite some time after all.
Using Tup for ReC98 was an idea that dated back to January 2017. Back
then, I already opened
the pull request with a fix to allow Tup to work together with 32-bit
TASM. As much as I love Tup though, the fact that it only worked on
64-bit Windows ≥Vista would have meant that we had to exchange perfect
dependency tracking for the ability to build on 32-bit and older Windows
versions at all. For a project that relies on DOS compilers, this
would have been exactly the wrong trade-off to make.
What's worse though: TLINK fails to run on modern 32-bit
Windows with Loader error (0000) : Unrecognized Error.
Therefore, the set of systems that Tup runs on, and the set of systems
that can actually compile ReC98's 16-bit build part natively, would have
been exactly disjoint, with no OS getting to use both at the same time.
So I've kept using Tup for only my own development, but indefinitely
shelved the idea of making it the official build system, due to those
drawbacks. Recently though, it all came together:
The tup generate sub-command can generate a
.bat file that does a full dumb rebuild of everything, which
can serve as a fallback option for systems that can't run Tup. All we have
to do is to commit that .bat file to the ReC98 Git repository
as well, and tell build32b.bat to fall back on that if Tup
can't be run. That alone would have given us the benefits of Tup without
being worse than the current dumb build process.
In the meantime, other contributors improved Tup's own build process to
the point where 32-bit builds were simple enough to accomplish from the
comfort of a WSL terminal.
Two commits of mine
later, and 32-bit Windows Tup was fully functional. Another one later,
and 32-bit Windows Tup even gained one potential advantage over its 64-bit
counterpart. Since it only has to support DLL injection into 32-bit
programs, it doesn't need a separate 32-bit binary for retrieving function
pointers to the 32-bit version of Windows' DLL loading syscalls. Weirdly
enough, Windows Defender on current Windows 10 falsely flags that binary as
malware, despite it doing nothing but printing those pointer values to
stdout. 🤷
I've also added it to the DevKit, for any newcomers to ReC98.
After the switch to Tup and the fallback option, I extensively tested
building ReC98 on all operating systems I had lying around. And holy cow,
so much in that build was broken beyond belief. In the end, the solution
involved just fully rebuilding the entire 16-bit part by default.
Which, of course, nullifies any of the
advantages we might have gotten from a Makefile in the first place, due to
just how unreliable they are. If you had problems building ReC98 in the
past, try again now!
And sure, it would certainly be possible to also get Tup working on
Windows ≤XP, or 9x even. But I leave that to all those tinkerers out there
who are actually motivated to keep those OSes alive. My work here is
done – we now have a build process that is optimal on 32-bit
Windows ≧Vista, and still functional and reliable on 64-bit
Windows, Linux, and everything down to Windows 98 SE, and therefore also
real PC-98 hardware. Pretty good, I'd say.
(If it weren't for that weird crash of the 16-bit TASM.EXE in
that Windows 95 command prompt I've tried it in, it would also work on
that OS. Probably just a misconfiguration on my part?)
Now, it might look like a waste of time to improve a 32-bit build part
that won't even exist anymore once this project is done. However, a fully
16-bit DOS build will only make sense after
master.lib has been turned into a proper library, linked in by
TLINK rather than #included in the big .ASM
files.
This affects all games. If master.lib's data was consistently placed at
the beginning or end of each data segment, this would be no big deal, but
it's placed somewhere else in every binary.
So, this will only make sense sometime around 90% overall PI, and maybe
~50% RE in each game. Which is something else than 50% overall –
especially since it includes TH02, the objectively worst Touhou game,
which hasn't received any dedicated funding ever.
Then, it will probably still require a couple of dedicated pushes to
move all the remaining data to C land.
Oh, and my 16-bit build system project also needs to be done before,
because, again, Makefiles are trash and we shouldn't rely on them even
more.
And who knows whether this project will get funded for that long. So yeah,
the 32-bit build part will stay with us for quite some more time, and for
all upcoming PI milestones. And with the current build process, it's
pretty much the most minor among all the minor issues I can think of.
Let's all enjoy the performance of a 32-bit build while we can 🙂
Next up: Paying some technical debt while keeping the RE% and PI% in place.
📝 Posted:
🏷 Tags:
TH01 pellets are coming up next, and for the first time, we'll have the
chance to move hardcoded sprite data from ASM land to C land. As it would
turn out, bad luck with the 2-byte alignment at the end of
REIIDEN.EXE's data segment pretty much forces us to declare
TH01's pellet sprites in C if we want to decompile the final few pellet
functions without ugly workarounds for the float literals there. And while
I could have just converted them into a C array and called it a day, it
did raise the question of when we are going to do this The Right And
Moddable Way, by auto-converting actual image files into ASM or C arrays
during the build process. These arrays are even more annoying to edit in
C, after all – unlike TASM, the old C++ we have to work with doesn't
support binary number literals, only hexadecimal or, gasp, octal.
Without the explicit funding for such a converter,
I reached out to
GitHub, asking backers and outside contributors whether they'd be in
favor of it. As something that requires no RE skills and collides with
nothing else, it would be a perfect task for C/C++ coders who want to
support ReC98 with something other than money.
And surprisingly, those still exist!
Jonathan Campbell, of
DOSBox-X fame,
went ahead and implemented all the required functionality, within just a
few days. Thanks again! The result is probably a lot more portable than it
would have been if I had written it. Which is pretty relevant for future
port authors – any additional tooling we write ourselves should not
add to the list of problems they'll have to worry about.
Right now, all of the sprites are #included from the big ASM
dump files, which means that they have to be converted before those files
are assembled during the 32-bit build part. We could have introduced a
third distinct build step there, perhaps even a 16-bit one so that we can
use Turbo C++ 4.0J to also compile the converter… However, the more
reasonable option was to do this at the beginning of the 32-bit build
step, and add a 32-bit Windows C++ compiler to the list of tools required
for ReC98's build process.
And the best choice for ReC98 is, in fact… 🥁… the 20-year-old Borland C++
5.5 freeware release.
See the README for a lengthy justification, as well as
download links.
So yes, all sprites mentioned in the GitHub issue can now be modded by
simply editing .BMP files, using an image editor of your choice. 🖌
And now that that's dealt with, it's finally time for more actual
progress! TH01 pellets coming tomorrow.


 and
and  labels clearly give it away as copy-pasted:
labels clearly give it away as copy-pasted:


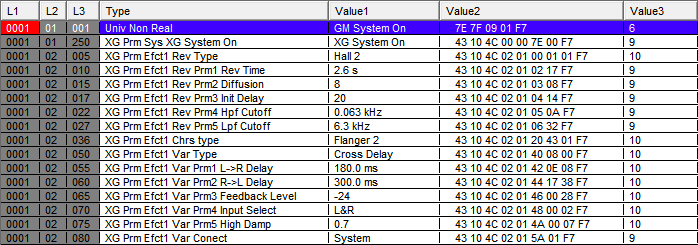
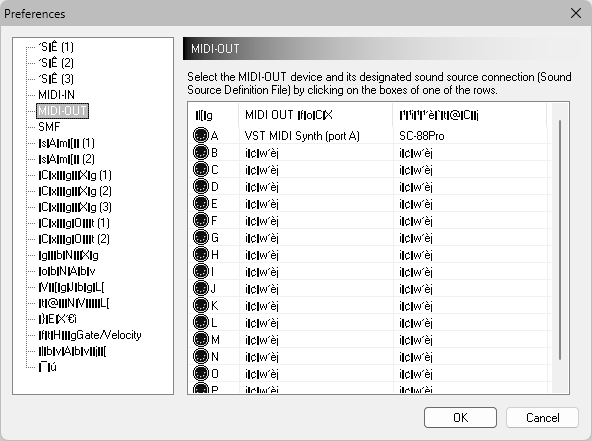
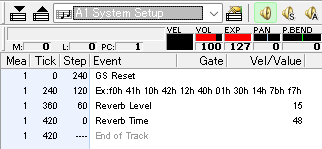

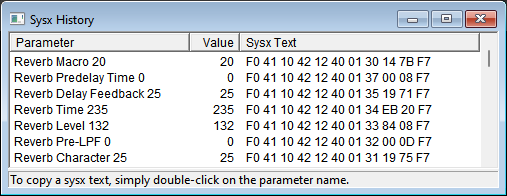
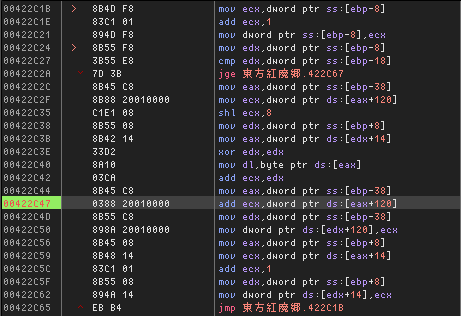

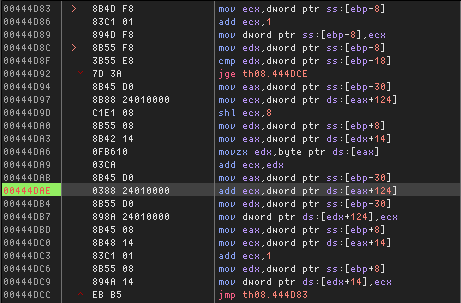
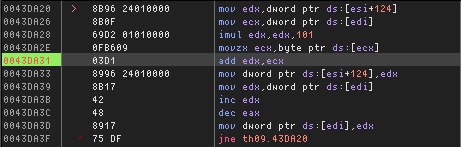
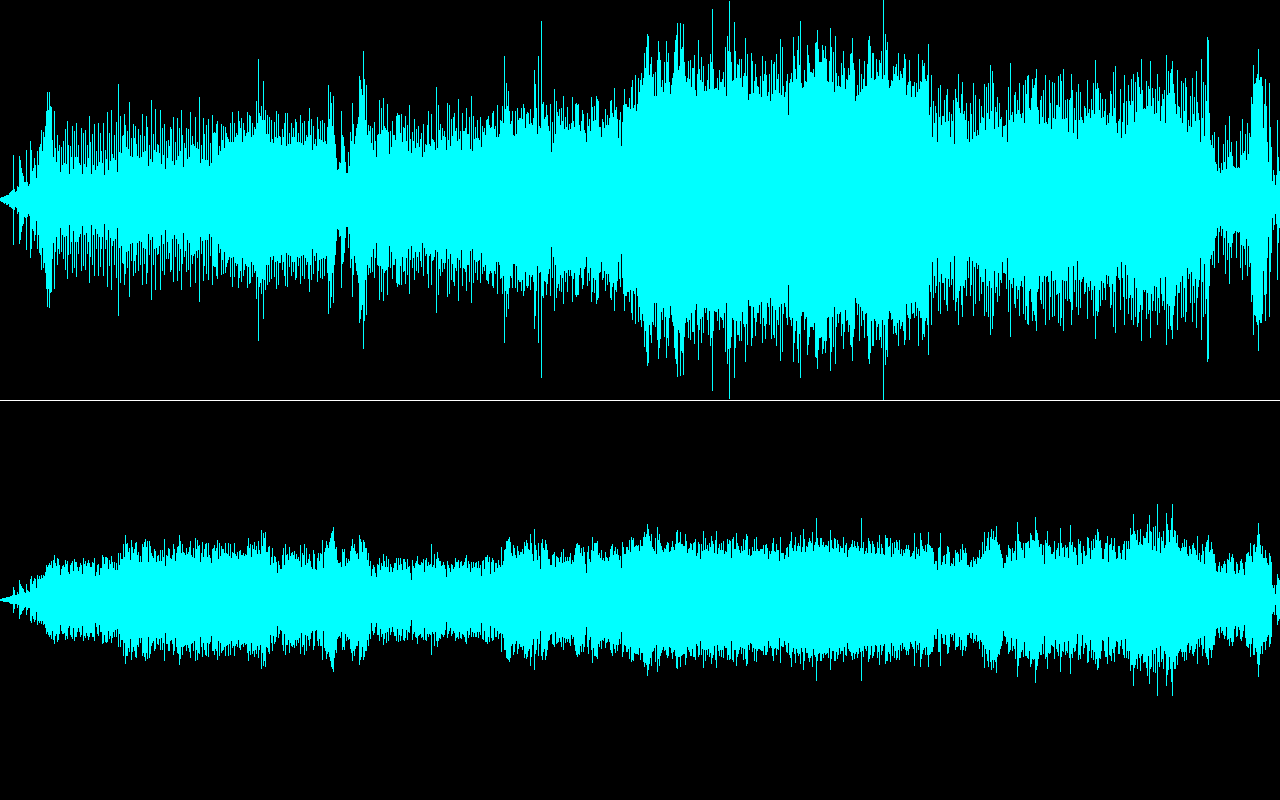
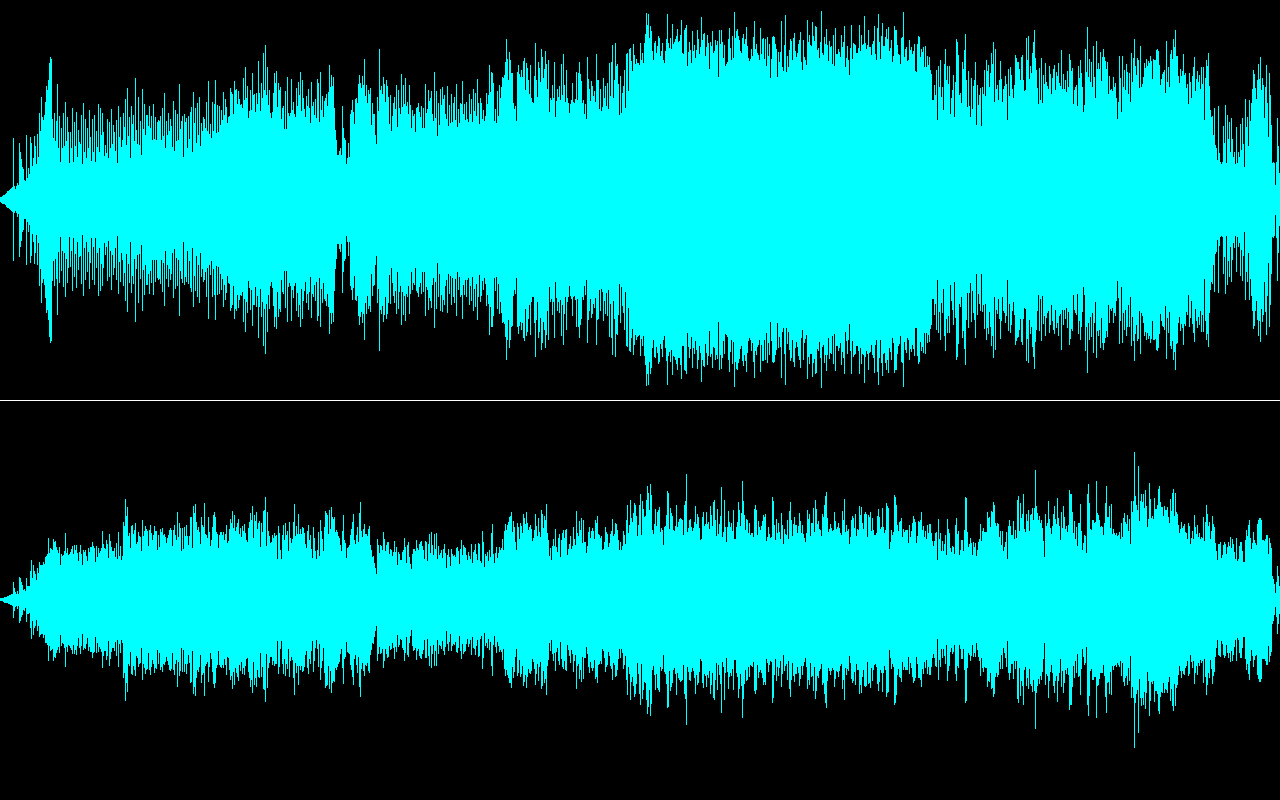

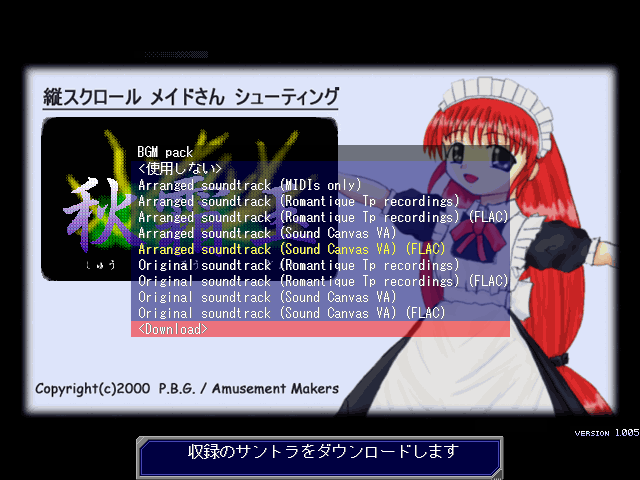









![Joypad button unbinding in the original version of Shuusou Gyoku, indicated by a rather confusing [Button 0] label](/blog/static/2023-09-30-SH01-Joypad-unmapping-original.png?9fe43b80)
![Joypad button unbinding in the P0256 build of Shuusou Gyoku, using a much clearer [--------] label](/blog/static/2023-09-30-SH01-Joypad-unmapping-P0256.png?f7adebb7)
{kind=link}