Turns out I was not quite done with the TH01 Anniversary Edition yet.
You might have noticed some white streaks at the beginning of Sariel's
second form, which are in fact a bug that I accidentally added to the
initial release.
These can be traced back to a quirk
I wasn't aware of, and hadn't documented so far. When defeating Sariel's
first form during a pattern that spawns pellets, it's likely for the second
form to start with additional pellets that resemble the previous pattern,
but come out of seemingly nowhere. This shouldn't really happen if you look
at the code: Nothing outside the typical pattern code spawns new pellets,
and all existing ones are reset before the form transition…
Except if they're currently showing the 10-frame delay cloud
animation , activated for all pellets during the symmetrical radial 2-ring
pattern in Phase 2 and left activated for the rest of the fight. These
pellets will continue their animation after the transition to the second
form, and turn into regular pellets you have to dodge once their animation
completed.
By itself, this is just one more quirk to keep in mind during refactoring.
It only turned into a bug in the Anniversary Edition because the game tracks
the number of living pellets in a separate counter variable. After resetting
all pellets, this counter is simply set to 0, regardless of any delay cloud
pellets that may still be alive, and it's merely incremented or decremented
when pellets are spawned or leave the playfield.
In the original game, this counter is only used as an optimization to skip
spawning new pellets once the cap is reached. But with batched
EGC-accelerated unblitting, it also makes sense to skip the rather costly
setup and shutdown of the EGC if no pellets are active anyway. Except if the
counter you use to check for that case can be 0 even if there are
pellets alive, which consequently don't get unblitted…
There is an optimal fix though: Instead of unconditionally resetting the
living pellet counter to 0, we decrement it for every pellet that
does get reset. This preserves the quirk and gives us a
consistently correct counter, allowing us to still skip every unnecessary
loop over the pellet array.
Cutting out the lengthy defeat animation makes it easier to see where the
additional pellets come from.
Cutting out the lengthy defeat animation makes it easier to see where the
additional pellets come from. Also, note how regular unblitting resumes
once the first pellet gets clipped at the top of the playfield – the
living pellet counter then gets decremented to -1, and who uses
<= rather than == on a seemingly unsigned
counter, right?
Cutting out the lengthy defeat animation makes it easier to see where the
additional pellets come from.
Ultimately, this was a harmless bug that didn't affect gameplay, but it's
still something that players would have probably reported a few more times.
So here's a free bugfix:
128 commits! Who would have thought that the ideal first release of the TH01
Anniversary Edition would involve so much maintenance, and raise so many
research questions? It's almost as if the real work only starts after
the 100% finalization mark… Once again, I had to steal some funding from the
reserved JIS trail word pushes to cover everything I liked to research,
which means that the next towards the
anything goal will repay this debt. Luckily, this doesn't affect any
immediate plans, as I'll be spending March with tasks that are already fully
funded.
So, how did this end up so massive? The list of things I originally set out
to do was pretty short:
Build entire game into single executable
Fix rendering issues in the one or two most important parts of the game
for a good initial impression
But even the first point already started with tons of little cleanup
commits. A part of them can definitely be blamed on the rush to hit the 100%
decompilation mark before the 25th anniversary last August.
However, all the structural changes that I can't commit to
master reveal how much of a mess the TH01 codebase actually
is.
Merging the executables is mainly difficult because of all the
inconsistencies between REIIDEN.EXE and FUUIN.EXE.
The worst parts can be found in the REYHI*.DAT format code and
the High Score menu, but the little things are just as annoying, like how
the current score is an unsigned variable in
REIIDEN.EXE, but a signed one in FUUIN.EXE.
If it takes me this long and this many
commits just to sort out all of these issues, it's no wonder that the only
thing I've seen being done with this codebase since TH01's 100%
decompilation was a single porting attempt that ended in a rather quick
ragequit.
So why are we merging the executables in preparation for the Anniversary
Edition, and not waiting with it until we start doing ports?
Distributing and updating one executable is cleaner than doing the same
with three, especially as long as installation will still involve manually
dropping the new binary into the game directory.
The Anniversary Edition won't be the only fork binary. We are already
going to start out with a separate DEBLOAT.EXE that contains
only the bloat removal changes without any bug fixes, and spaztron64
will probably redo his seizure-less edition. We don't want to clutter
the game directory with three binaries for each of these fork builds, and we
especially don't want to remember things like oh, but this fork
only modifies REIIDEN.EXE…
All forks should run side-by-side with the original game. During the
time I was maintaining thcrap, I've had countless bug reports of people
assuming that thcrap was
responsible for bugs that were present in the original game, and the
same is certain to happen with the Anniversary Edition. Separate binaries
will make it easier for everyone to check where these bugs came from.
Also, I'd like to make a point about how bloated the original
three-executable structure really is, since I've heard people defending it
as neat software architecture. Really, even in Real Mode where you typically
want to use as little of the 640 KiB of conventional memory as possible, you
don't want to split your game up like this.
The game actually is so bloated that the combined binary ended up
smaller than the original REIIDEN.EXE. If all you see are the
file sizes of the original three executables, this might look like a
pretty impressive feat. Like, how can we possibly get 407,812
bytes into less than 238,612 bytes, without using compression?
If you've ever looked at the linker map though, it's not at all surprising.
Excluding the aforementioned inconsistencies that are hard to quantify,
OP.EXE and FUUIN.EXE only feature 5,767 and 6,475
bytes of unique code and data, respectively. All other code in these
binaries is already part of REIIDEN.EXE, with more than half of
the size coming from the Borland C++ runtime. The single worst offender here
is the C++ exception handler that Borland forces
onto every non-.COM binary by default, which alone adds 20,512 bytes
even if your binary doesn't use C++ exceptions.
On a more hilarious note, this
single line is responsible for pulling another unnecessary 14,242 bytes
into OP.EXE and FUUIN.EXE. This floating-point
multiplication is completely unnecessary in this context because all
possible parameters are integers, but it's enough for Turbo C++ and TLINK to
pull in the entire x87 FPU emulation machinery. These two binaries don't
even draw lines, but since this function is part of the general
graphics code translation unit and contains other functions that these
binaries do need, TLINK links in the entire thing. Maybe, multiple
executables aren't the best choice either if you use a linker that can't do
dead code elimination…
Since the 📝 Orb's physics do turn the entire
precision of a double variable into gameplay effects, it's not
feasible to ever get rid of all FPU code in TH01. The exception handler,
however, can
be removed, which easily brings the combined binary below the size of
the original REIIDEN.EXE. Compiling all code with a single set
of compiler optimization flags, including the more x86-friendly
pascal calling convention, then gets us a few more KB on top.
As does, of course, removing unused code: The only remaining purpose of
features such as 📝 resident palettes is to
potentially make porting more difficult for anyone who doesn't immediately
realize that nothing in the game uses these functions.
Technically, all unused code would be bloat, but for now, I'm keeping
the parts that may tell stories about the game's development history (such
as unused effects or the 📝 mouse cursor), or
that might help with debugging. Even with that in mind, I've only scratched
the surface when it comes to bloat removal, and the binary is only going to
get smaller from here. A lot smaller.
If only we now could start MDRV98 from this new combined binary, we wouldn't
need a second batch file either…
Which brings us to the first big research question of this delivery. Using
the C spawn() function works fine on this compiler, so
spawn("MDRV98.COM") would be all we need to do, right? Except
that the game crashes very soon after that subprocess returned.
So it's not going to be that easy if the spawned process is a TSR.
But why should this be a problem? Let's take a look at the DOS heap, and how
DOS lays out processes in conventional memory if we launch the game
regularly through GAME.BAT:
The rough layout of the DOS heap when launching TH01 from
GAME.BAT.
The batch file starts MDRV98 first, which will therefore end up below
the game in conventional memory. This is perfect for a TSR: The program can
resize itself arbitrarily before returning to DOS, and the rest of memory
will be left over for the game. If we assume such a layout, a DOS program
can implement a custom memory allocator in a very simple way, as it only has
to search for free memory in one direction – and this is exactly how Borland
implemented the C heap for functions like malloc() and
free(), and the C++ new and delete
operators.
But if we spawn MDRV98 after starting TH01, well…
MDRV98 will spawn in the next free memory location, allocate itself, return
to TH01… which suddenly finds its C heap blocked from growing. As a result,
the next big allocation will immediately fail with a rather misleading "out
of memory" error.
So, what can we do about this? Still in a bloat removal mindset, my gut
reaction was to just throw out Borland's C heap implementation, and replace
it with a very thin wrapper around the DOS heap as managed by INT 21h,
AH=48h/49h/4Ah. Like, why
did these DOS compilers even bother with a custom allocator in the first
place if DOS already comes with a perfectly fine native one? Using the
native allocator would completely erase the distinction between TSR memory
and game memory, and inherently allow the game to allocate beyond
MDRV98.
I did in fact implement this, and noticed even more benefits:
While DOS uses 16 bytes rather than Borland's 4 bytes for the control
structure of each memory block, this larger size automatically aligns all
allocations to 16-byte boundaries. Therefore, all allocation addresses would
fit into 16-bit segment-only pointers rather than needing 32-bit
far ones. On the Borland heap, the 4-byte header further limits
regular far pointers to 65,532 bytes, forcing you into
expensive huge pointers for bigger allocations.
Debuggers in DOS emulators typically have features to show and manage
the DOS heap. No need for custom debugging code.
You can change the memory placement
strategy to allocate from the top of conventional memory down to the
bottom. This is how the games allocate their resident structures.
Ultimately though, the drawbacks became too significant. Most of them are
related to the PC-98 Touhou games only ever creating a single DOS
process, even though they contain multiple executables.
Switching executables is done via exec(), which resizes a
program's main allocation to match the new binary and then overwrites the
old program image with the new one. If you've ever wondered why DOSBox-X
only ever shows OP as the active process name in the title bar,
you now know why. As far as DOS is concerned, it's still the same
OP.EXE process rooted at the same segment, and
exec() doesn't bother rewriting the name either. Most
importantly though, this is how REIIDEN.EXE can launch into
another REIIDEN.EXE process even if there are less than 238,612
bytes free when exec() is called, and without consuming more
memory for every successive binary.
For now, ANNIV.EXE still re-exec()s itself at
every point where the original game did, as ZUN's original code really
depends on being reinitialized at boss and scene boundaries. The resulting
accidental semi-hot reloading is also a useful property to retain
during development.
So why is the DOS heap a bad idea for regular game allocation after all?
Even DOS automatically releases all memory associated with a process
during its termination. But since we keep running the same process until the
player quits out of the main menu, we lose the C heap's implicit cleanup on
exec(), and have to manually free all memory ourselves.
Since the binary can be larger after hot reloading, we in fact have
to allocate all regular memory using the last fit strategy.
Otherwise, exec() fails to resize the program's main block for
the same reason that crashed the game on our initial attempt to
spawn("MDRV98.COM").
Just like Borland's heap implementation, the DOS heap stores its control
structures immediately before each allocation, forming a singly linked list.
But since the entire OS shares this single list, corruptions from heap
overflows also affect the whole system, and become much more disastrous.
Theoretically, it might be possible to recover from them by forcibly
releasing all blocks after the last correct one, or even by doing a
brute-force search for valid memory
control blocks, but in reality, DOS will likely just throw error code #7
(ERROR_ARENA_TRASHED) on the next memory management syscall,
forcing a reboot.
With a custom allocator, small corruptions remain isolated to the process.
They can be even further limited if the process adds some padding between
its last internal allocation and the end of the allocated DOS memory block;
Borland's heap sort of does this as well by always rounding up the DOS block
to a full KiB. All this might not make a difference in today's emulated and
single-tasked usage, but would have back then when software was still
developed inside IDEs running on the same system.
TH01's debug mode uses heapcheck() and
heapchecknode(), and reimplementing these on top of the DOS
heap is not trivial. On the contrary, it would be the most complicated part
of such a wrapper, by far.
I could release this DOS heap wrapper in unused form for another push if
anyone's interested, but for now, I'm pretty happy with not actually using
it in the games. Instead, let's stay with the Borland C heap, and find a way
to push MDRV98 to the very top of conventional RAM. Like this:
Which is much easier said than done. It would be nice if we could just use
the last fit allocation strategy here, but .COM executables always
receive all free memory by default anyway, which eliminates any difference
between the strategies.
But we can still change memory itself. So let's temporarily claim all
remaining free memory, minus the exact amount we need for MDRV98, for our
process. Then, the only remaining free space to spawn MDRV98 is at the exact
place where we want it to be:
Obviously, we release all the additional memory after spawning MDRV98.
Now we only need to know how much memory to not temporarily allocate. First,
we need to replicate the assumption that MDRV98's -M7
command-line parameter corresponds to a resident size of 23,552 bytes. This
is not as bad as it seems, because the -M parameter explicitly
has a KiB unit, and we can nicely abstract it away for the API.
The (env.) block though? Its minimum size equals the combined length
of all environment variables passed to the process, but its maximum size is…
not limited at all?! As in, DOS implementations can add and have
historically added more free space because some programs insisted on storing
their own new environment variables in this exact segment. DOSBox and
DOSBox-X follow this tradition by providing a configuration option for the
additional amount of environment space, with the latter adding 1024
additional bytes by default, y'know, just in case someone wants to compile
FreeDOS on a slow emulator. It's not even worth sending a bug report for
this specific case, because it's only a symptom of the fact that
unexpectedly large program environment blocks can and will happen, and are
to be expected in DOS land.
So thanks to this cruel joke, it's technically impossible to achieve what we
want to do there. Hooray! The only thing we can kind of do here is an
educated guess: Sum up the length of all environment variables in our
environment block, compare that length against the allocated size of the
block, and assume that the MDRV98 process will get as much additional memory
as our process got. 🤷
The remaining hurdles came courtesy of some Borland C runtime implementation
details. You would think that the temporary reallocation could even be done
in pure C using the sbrk(), coreleft(), and
brk() functions, but all values passed to or returned from
these functions are inaccurate because they don't factor in the
aforementioned KiB padding to the underlying DOS memory block. So we have to
directly use the DOS syscalls after all. Which at least means that learning
about them wasn't completely useless…
The final issue is caused inside Borland's
spawn() implementation. The environment block for the
child process is built out of all the strings reachable from C's
environ pointer, which is what that FreeDOS build process
should have used. Coalescing them into a single buffer involves yet
another C heap allocation… and since we didn't report our DOS memory block
manipulation back to the C heap, the malloc() call might think
it needs to request more memory from DOS. This resets the DOS memory block
back to its intended level, undoing our manipulation right before the actual
INT 21h, AH=4Bh
EXEC syscall. Or in short:
Manipulate DOS heap ➜ spawn() call ➜_LoadProg() ➜ allocate and prepare environment block ➜ _spawn() ➜ DOS EXEC syscall
The obvious solution: Replace _LoadProg(), implement the
coalescing ourselves, and do it before the heap manipulation. Fortunately,
Borland's internal low-level _spawn() function is not
static, so we can call it ourselves whenever we want to:
Allocate and prepare environment block ➜ manipulate DOS heap ➜ _spawn() call ➜EXEC syscall
So yes, launching MDRV98 from C can be done, but it involves advanced
witchcraft and is completely ridiculous.
Launching external sound drivers from a batch file is the right way
of doing things.
Fortunately, you don't have to rely on this auto-launching feature. You can
still launch DEBLOAT.EXE or ANNIV.EXE from a batch
file that launched MDRV98.COM before, and the binaries will
detect this case and skip the attempt of launching MDRV98 from C. It's
unlikely that my heuristic will ever break, but I definitely recommend
replicating GAME.BAT just to be completely sure – especially
for user-friendly repacks that don't want to include the original game
anyway.
This is also why ANNIV.EXE doesn't launch
ZUNSOFT.COM: The "correct" and stable way to launch
ANNIV.EXE still involves a batch file, and I would say that
expecting people to remove ZUNSOFT.COM from that file is worse
than not playing the animation. It's certainly a debate we can have, though.
This deep dive into memory allocation revealed another previously
undocumented bug in the original game. The RLE decompression code for the
東方靈異.伝 packfile contains two heap overflows, which are
actually triggered by SinGyoku's BOSS1_3.BOS and Konngara's
BOSS8_1.BOS. They only do not immediately crash the game when
loading these bosses thanks to two implementation details of Borland's C
heap.
Obviously, this is a bug we should fix, but according to the definition of
bugs, that fix would be exclusive to the anniversary branch.
Isn't that too restrictive for something this critical? This code is
guaranteed to blow up with a different heap implementation, if only in a
Debug build. And besides, nobody would notice a fix
just by looking at the game's rendered output…
Looks like we have to introduce a fourth category of weird code, in addition
to the previous bloat, bug, and quirk categories, for
invisible internal issues like these. Let's call it landmine, and fix
them on the debloated branch as well. Thanks to
Clerish for the naming inspiration!
With this new category, the full definitions for all categories have become
quite extensive. Thus, they now live in CONTRIBUTING.md
inside the ReC98 repository.
With the new discoveries and the new landmine category, TH01 is now at 67
bugs and 20 landmines. And the solution for the landmine in question? Simplifying
the 61 lines of the original code down to 16. And yes, I'm including
comments in these numbers – if the interactions of the code are complex
enough to require multi-paragraph comments, these are a necessary and
valid part of the code.
While we're on the topic of weird code and its visible or invisible effects,
there's one thing you might be concerned about. With all the rearchitecting
and data shifting we're doing on the debloated branch, what
will happen to the 📝 negative glitch stages?
These are the result of a clearly observable bug that, by definition, must
not be fixed on the debloated branch. But given that the
observable layout of the glitch stages is defined by the memory
surrounding the scene stage variable, won't the
debloated branch inherently alter their appearance (= ⚠️
fanfiction ⚠️), or even remove them completely?
Well, yes, it will. But we can still preserve their layout by
hardcoding
the exact original data that the game would originally read, and even emulate
the original segment relocations and other pieces of global data.
Doing this is feasible thanks to the fact that there are only 4 glitch
stages. Unfortunately, the same can't be said for the timer values, which
are determined by an array lookup with the un-modulo'd stage ID. If we
wanted to preserve those as well, we'd have to bundle an exact copy of the
original REIIDEN.EXE data segment to preserve the values of all
32,768 negative stages you could possibly enter, together with a map
of all relocations in this segment. 😵 Which I've decided against for now,
since this has been going on for far too long already. Let's first see if
anyone ever actually complains about details like this…
Alright, time to start the anniversary branch by rendering
everything at its correct internal unaligned X position? Eh… maybe not quite
yet. If we just hacked all the necessary bit-shifting code into all the
format-specific blitting functions, we'd still retain all this largely
redundant, bad, and slow code, and would make no progress in terms of
portability. It'd be much better to first write a single generic blitter
that's decently optimized, but supports all kinds of sprites to make this
optimization actually worth something.
So, next research question: How would such a blitter look like? After I
learned during my
📝 first foray into cycle counting that port
I/O is slow on 486 CPUs, it became clear that TH04's
📝 GRCG batching for pellets was one of the
more useful optimizations that probably contributed a big deal towards
achieving the high bullet counts of that game. This leads to two
conclusions:
master.lib's super_*() sprite functions are slow, and not
worth looking at for inspiration. Even the 📝 tiny format reinitializes the GRCG on every color change, wasting 80
cycles.
Hence, our low-level blitting API should not even care about colors. It
should only concern itself with blitting a given 1bpp sprite to a single
VRAM segment. This way, it can work for both 4-plane sprites and
single-plane sprites, and just assume that the GRCG is active.
Maybe we should also start by not even doing these unaligned bit shifts
ourselves, and instead expect the call site to
📝 always deliver a byte-aligned sprite that is correctly preshifted,
if necessary? Some day, we definitely should measure how slow runtime
shifting would really be…
What we should do, however, are some further general optimizations that I
would have expected from master.lib: Unrolling the vertical
loop, and baking a single function for every sprite width to eliminate
the horizontal loop. We can then use the widest possible x86
MOV instruction for the lowest possible number of cycles per
row – for example, we'd blit a 56-wide sprite with three MOVs
(32-bit + 16-bit + 8-bit), and a 64-wide one with two 32-bit
MOVs.
Or maybe not? There's a lot of blitting code in both master.lib and PC-98
Touhou that checks for empty bytes within sprites to skip needlessly writing
them to VRAM:
Which goes against everything you seem to know about computers. We aren't
running on an 8-bit CPU here, so wouldn't it be faster to always write both
halves of a sprite in a single operation?
That's a single CPU instruction, compared to two instructions and two
branches. The only possible explanation for this would be that VRAM writes
are so slow on PC-98 that you'd want to avoid them at all costs, even
if that means additional branching on the CPU to do so. Or maybe that was
something you would want to do on certain models with slow VRAM, but not on
others?
So I wrote a benchmark to answer all these questions, and to compare my new
blitter against typical TH01 blitting code:
A not really representative run on DOSBox-X. Since the master.lib sprite
functions are also unbatched, I expect them to not be much faster than
the naive C implementation.
2023-03-05-blitperf.zip
And here are the real-hardware results I've got from the PC-9800
Central Discord server:
PC-286LS
PC-9801ES
PC-9821Cb/Cx
PC-9821Ap3
PC-9821An
PC-9821Nw133
PC-9821Ra20
80286, 12 MHz
i386SX, 16 MHz
486SX, 33 MHz
486DX4, 100 MHz
Pentium, 90 MHz
Pentium, 133 MHz
Pentium Pro, 200 MHz
1987
1989
1994
1994
1994
1997
1996
Unchecked
C
GRCG
36,85
38,42
26,02
26,87
3,98
4,13
2,08
2,16
1,81
1,87
0,86
0,89
1,25
1,25
MOVS
GRCG
15,22
16,87
9,33
10,19
1,22
1,37
0,44
0,44
MOV
GRCG
15,42
17,08
9,65
10,53
1,15
1,3
0,44
0,44
4-plane
37,23
43,97
29,2
32,96
4,44
5,01
4,39
4,67
5,11
5,32
5,61
5,74
6,63
6,64
Checking first
GRCG
17,49
19,15
10,84
11,72
1,27
1,44
1,04
1,07
0,54
0,54
4-plane
46,49
53,36
35,01
38,79
5,66
6,26
5,43
5,74
6,56
6,8
8,08
8,29
10,25
10,29
Checking second
GRCG
16,47
18,12
10,77
11,65
1,25
1,39
1,02
0,51
0,51
4-plane
43,41
50,26
33,79
37,82
5,22
5,81
5,14
5,43
6,18
6,4
7,57
7,77
9,58
9,62
Checking both
GRCG
16,14
18,03
10,84
11,71
1,33
1,49
1,01
0,49
0,49
4-plane
43,61
50,45
34,11
37,87
5,39
5,99
4,92
5,23
5,88
6,11
7,19
7,43
9,1
9,13
Amount of frames required to render 2000 16×8 pellet sprites on a variety of
PC-98 models, using the new generic blitter. Both preshifted (first column)
and runtime-shifted (second column) sprites were tested; empty columns
correspond to times faster than a single frame. Thanks to cuba200611,
Shoutmon, cybermind, and Digmac for running the tests!
The key takeaways:
Checking for empty bytes has never been a good idea.
Preshifting sprites made a slight difference on the 286. Starting with
the 386 though, that difference got smaller and smaller, until it completely
vanished on Pentium models. The memory tradeoff is especially not worth it
for 4-plane sprites, given that you would have to preshift each of the 4
planes and possibly even a fifth alpha plane. Ironically, ZUN only ever
preshifted monochrome single-bitplane sprites with a width of 8 pixels.
That's the smallest possible amount of memory a sprite can possibly take,
and where preshifting consequently has the smallest effect on performance.
Shifting 8-wide sprites on the fly literally takes a single ROL
or ROR instruction per row.
You might want to use MOVS instead of MOV when
targeting the 286 and 386, but the performance gains are barely worth the
resulting mess you would make out of your blitting code. On Pentium models,
there is no difference.
Use the GRCG whenever you have to render lots of things that share a
static 8×1 pattern.
These are the PC-98 models that the people who are willing to test your
newly written PC-98 code actually use.
Since this won't be the only piece of game-independent and explicitly
PC-98-specific custom code involved in this delivery, it makes sense to
start a
dedicated PC-98 platform layer. This code will gradually eliminate the
dependency on master.lib and replace it with better optimized and more
readable C++ code. The blitting benchmark, for example, is already
implemented completely without master.lib.
While this platform layer is mainly written to generate optimal code within
Turbo C++ 4.0J, it can also serve as general PC-98 documentation for
everyone who prefers code over machine-translating old Japanese books. Not
to mention the immediacy of having all actual relevant information in
one place, which might otherwise be pretty well hidden in these books, or
some obscure old text file. For example, did you know that uploading gaiji
via INT 18h might end up disabling the VSync interrupt trigger,
deadlocking the process on the next frame delay loop? This nuisance is not
replicated by any emulators, and it's quite frustrating to encounter it when
trying to run your code on real hardware. master.lib works around it by
simply hooking INT 18h and unconditionally reenabling the VSync
interrupt trigger after the original handler returns, and so does our
platform layer.
So, with the pellet draw calls batched and routed through the new renderer,
we should have gained enough free CPU cycles to disable
📝 interlaced pellet rendering without any
impact on frame rates?
Well, kinda. We do get 56.4 FPS, but only together with noticeable and
reproducible tearing in the top part of the playfield, suggesting exactly
why ZUN interlaced the rendering in the first place. 😕 So have we
already reached the limit of single-buffered PC-98 games here, or can we
still do something about it?
As it turns out, the main bottleneck actually lies in the pellet
unblitting code. Every EGC-"accelerated" unblitting call in TH01 is
as unbatched as the pellet blitting calls were, spending an additional 17
I/O port writes per call to completely set up and shut down the EGC, every
time. And since this is TH01, the two-instruction operation of changing the
active PC-98 VRAM page isn't inlined either, but instead done via a function
call to a faraway segment. On the 486, that's:
>341 cycles for EGC setup and teardown, plus
>72 cycles for each 16-pixel chunk to be unblitted.
This sums up to
>917 cycles of completely unnecessary work for every active pellet,
in the optimal 50% of cases where it lies on an even VRAM byte,
or
>1493 cycles if it lies on an odd VRAM byte, because ZUN's code
extends the unblitted rectangle to a gargantuan 32×8 pixels in this case
And this calculation even ignores the lack of small micro-optimizations that
could further optimize the blitting loop. Multiply that by the game's pellet
cap of 100, and we get a 6-digit number of wasted CPU cycles. On
paper, that's roughly 1/6 of the time we have for each
of our target 56.423 FPS on the game's target 33 MHz systems. Might not
sound all too critical, but the single-buffered nature of the game means
that we're effectively racing the beam on every frame. In turn, we have to
be even more serious about performance.
So, time to also add a batched EGC API to our PC-98 platform layer? Writing
our own EGC code presents a nice opportunity to finally look deeper into all
its registers and configuration options, and see what exactly we can do
about ZUN's enforced 16-pixel alignment.
To nobody's surprise, this alignment is completely unnecessary, and only
displays a lack of knowledge about the chip. While it is true that
the EGC wants VRAM to be exclusively addressed in 16-bit chunks at
16-bit-aligned addresses, it specifically provides
an address register (0x4AC) for shifting the horizontal
start offsets of the source and destination to any pixel within the
16 pixels of such a chunk, and
a bit length register (0x4AE) for specifying the total
width of pixels to be transferred, which also implies the correct end
offsets.
And it gets even better: After ⌈bitlength ÷ 16⌉ write
instructions, the EGC's internal shifter state automatically reinitializes
itself in preparation for blitting another row of pixels with the same
initially configured bit addresses and length. This is perfect for blitting
rectangles, as two I/O port writes before the start of your blitting loop
are enough to define your entire rectangle.
The manual nature of reading and writing in 16-pixel chunks does come with a
slight pitfall though. If the source bit address is larger than the
destination bit address, the first 16-bit read won't fill the EGC's internal
shift register with all pixels that should appear in the first 16-pixel
destination chunk. In this case, the EGC simply won't write anything and
leave the first chunk unchanged. In a
📝 regular blitting loop, however, you expect
that memory to be written and immediately move on to the next chunks within
the row. As a result, the actual blitting process for such a rectangle will
no longer be aligned to the configured address and bit length. The first row
of the rectangle will appear 16 pixels to the right of the destination
address, and the second one will start at bit offset 0 with pixels from the
rightmost byte of the first line, which weren't blitted and remained in the
tile register.
There is an easy solution though: Before the horizontal loop on each line of
the rectangle, simply read one additional 16-pixel chunk from the source
location to prefill the shift register. Thankfully, it's large enough to
also fit the second read of the then full 16 pixels, without dropping any
pixels along the way.
And that's how we get arbitrarily unaligned rectangle copies with the EGC!
Except for a small register allocation trick to use two-register addressing,
there's not much use in further optimizations, as the runtime of these
inter-page blit operations is dominated by the VRAM page switches anyway.
Except that T98-Next seems to disagree about the register prefilling issue:
Every other emulator agrees with real hardware in this regard, so we can
safely assume this to be a bug in T98-Next. Just in case this old emulator
with its last release from June 2010 still has any fans left nowadays… For
now though, even they can still enjoy the TH01 Anniversary Edition: The only
EGC copy algorithm that TH01 actually needs is the left one during the
single-buffered tests, which even that emulator gets right.
That only leaves
📝 my old offer of documenting the EGC raster ops,
and we've got the EGC figured out completely!
And that did in fact remove tearing from the pellet rendering function! For
the first time, we can now fight Elis, Kikuri, Sariel, and Konngara with a
doubled pellet frame rate:
Switchable videos like these can nicely provide evidence that these
changes have no effect on gameplay, making it easy to see that the Orb
still collides with all pellets on the same frames. Also, check out the
difference in remaining conventional memory (coreleft)…
With only pellets and no other animation on screen, this exact pattern
presents the optimal demonstration case for the new unblitter. But as you
can already tell from the invincibility sprites, we'd also need to route
every other kind of sprite through the same new code. This isn't all too
trivial: Most sprites are still rendered at byte-aligned positions, and
their blitting APIs hide that fact by taking a pixel position regardless.
This is why we can't just replace ZUN's original 16-pixel-aligned EGC
unblitting function with ours, and always have to replace both the blitter
and the unblitter on a per-sprite basis.
To completely remove all flickering, we'd also like to get rid of all the
sprite-specific unblit ➜ update ➜ render sequences, and instead
gather all unblitting code to the beginning of the game loop, before any
update and rendering calls. So yeah, it will take a long time to completely
get rid of all flickering. Until we're there, I recommend any backer to tell
me their favorite boss, so that I can focus on getting that one
rendered without any flickering. Remember that here at ReC98, we can have a
Touhou character popularity contest at any time during the year, whenever
the store is open!
In the meantime, the consistent use of 8×8 rectangles during pellet
unblitting does significantly reduce flickering across the entire game,
and shrinks certain holes that pellets tend to rip into lazily reblitted
sprites:
SinGyoku's "crossing pellets" pattern, shortly before completing
the transformation back to the sphere.
To round out the first release, I added all the other bug fixes to achieve
parity with my previously released patched REIIDEN.EXE builds:
I removed the 📝 shootout laser crash by
simply leaving the lasers on screen if a boss is defeated,
prevented the HP bar heap corruption bug in test or debug mode by not
letting it display negative HP in the first place, and
So here it is, the first build of TH01's Anniversary Edition:
2023-03-05-th01-anniv.zip Edit (2023-03-12): If you're playing on Neko Project and seeing more
flickering than in the original game, make sure you've checked the Screen
→ Disp vsync option.
Next up: The long overdue extended trip through the depths of TH02's
low-level code. From what I've seen of it so far, the work on this project
is finally going to become a bit more relaxing. Which is quite welcome
after, what, 6 months of stressful research-heavy work?
It only took a record-breaking 1½ pushes to get SinGyoku done!
No 📝 entity synchronization code after
all! Since all of SinGyoku's sprites are 96×96 pixels, ZUN made the rather
smart decision of just using the sphere entity's position to render the
📝 flash and person entities – and their only
appearance is encapsulated in a single sphere→person→sphere transformation
function.
Just like Kikuri, SinGyoku's code as a whole is not a complete
disaster.
The negative:
It's still exactly as buggy as Kikuri, with both of the ZUN bugs being
rendering glitches in a single function once again.
It also happens to come with a weird hitbox, …
… and some minor questionable and weird pieces of code.
The overview:
SinGyoku's fight consists of 2 phases, with the first one corresponding
to the white part from 8 to 6 HP, and the second one to the rest of the HP
bar. The distinction between the red-white and red parts is purely visual,
and doesn't reflect anything about the boss script.
Both phases cycle between a pellet pattern and SinGyoku's sphere form
slamming itself into the player, followed by it slightly overshooting its
intended base Y position on its way back up.
Phase 1 only consists of the sphere form's half-circle spray pattern.
Technically, the phase can only end during that pattern, but adding
that one additional condition to allow it to end during the slam+return
"pattern" wouldn't have made a difference anyway. The code doesn't rule out
negative HP during the slam (have fun in test or debug mode), but the sum of
invincibility frames alone makes it impossible to hit SinGyoku 7 times
during a single slam in regular gameplay.
Phase 2 features two patterns for both the female and male forms
respectively, which are selected randomly.
This time, we're back to the Orb hitbox being a logical 49×49 pixels in
SinGyoku's center, and the shot hitbox being the weird one. What happens if
you want the shot hitbox to be both offset to the left a bit
and stretch the entire width of SinGyoku's sprite? You get a hitbox
that ends in mid-air, far away from the right edge of the sprite:
Due to VRAM byte alignment, all player shots fired between
gx = 376 and gx = 383 inclusive
appear at the same visual X position, but are internally already partly
outside the hitbox and therefore won't hit SinGyoku – compare the
marked shot at gx = 376 to the one at gx =
380. So much for precisely visualizing hitboxes in this game…
Since the female and male forms also use the sphere entity's coordinates,
they share the same hitbox.
Onto the rendering glitches then, which can – you guessed it – all be found
in the sphere form's slam movement:
ZUN unblits the delta area between the sphere's previous and current
position on every frame, but reblits the sphere itself on… only every second
frame?
For negative X velocities, ZUN made a typo and subtracted the Y velocity
from the right edge of the area to be unblitted, rather than adding the X
velocity. On a cursory look, this shouldn't affect the game all too
much due to the unblitting function's word alignment. Except when it does:
If the Y velocity is much smaller than the X one, the left edge of the
unblitted area can, on certain frames, easily align to a word address past
the previous right edge of the sphere. As a result, not a single sphere
pixel will actually be unblitted, and a small stripe of the sphere will be
left in VRAM for one frame, until the alignment has caught up with the
sphere's movement in the next one.
By having the sphere move from the right edge of the playfield to the
left, this video demonstrates both the lazy reblitting and broken
unblitting at the right edge for negative X velocities. Also, isn't it
funny how Reimu can partly disappear from all the sloppy
SinGyoku-related unblitting going on after her sprite was blitted?
Due to the low contrast of the sphere against the background, you typically
don't notice these glitches, but the white invincibility flashing after a
hit really does draw attention to them. This time, all of these glitches
aren't even directly caused by ZUN having never learned about the
EGC's bit length register – if he just wrote correct code for SinGyoku, none
of this would have been an issue. Sigh… I wonder how many more glitches will
be caused by improper use of this one function in the last 18% of
REIIDEN.EXE.
There's even another bug here, with ZUN hardcoding a horizontal delta of 8
pixels rather than just passing the actual X velocity. Luckily, the maximum
movement speed is 6 pixels on Lunatic, and this would have only turned into
an additional observable glitch if the X velocity were to exceed 24 pixels.
But that just means it's the kind of bug that still drains RE attention to
prove that you can't actually observe it in-game under some
circumstances.
The 5 pellet patterns are all pretty straightforward, with nothing to talk
about. The code architecture during phase 2 does hint towards ZUN having had
more creative patterns in mind – especially for the male form, which uses
the transformation function's three pattern callback slots for three
repetitions of the same pellet group.
There is one more oddity to be found at the very end of the fight:
Right before the defeat white-out animation, the sphere form is explicitly
reblitted for no reason, on top of the form that was blitted to VRAM in the
previous frame, and regardless of which form is currently active. If
SinGyoku was meant to immediately transform back to the sphere form before
being defeated, why isn't the person form unblitted before then? Therefore,
the visibility of both forms is undeniably canon, and there is some
lore meaning to be found here…
In any case, that's SinGyoku done! 6th PC-98 Touhou boss fully
decompiled, 25 remaining.
No FUUIN.EXE code rounding out the last push for a change, as
the 📝 remaining missile code has been
waiting in front of SinGyoku for a while. It already looked bad in November,
but the angle-based sprite selection function definitely takes the cake when
it comes to unnecessary and decadent floating-point abuse in this game.
The algorithm itself is very trivial: Even with
📝 .PTN requiring an additional quarter parameter to access 16×16 sprites,
it's essentially just one bit shift, one addition, and one binary
AND. For whatever reason though, ZUN casts the 8-bit missile
angle into a 64-bit double, which turns the following explicit
comparisons (!) against all possible 4 + 16 boundary angles (!!)
into FPU operations. Even with naive and readable
division and modulo operations, and the whole existence of this function not
playing well with Turbo C++ 4.0J's terrible code generation at all, this
could have been 3 lines of code and 35 un-inlined constant-time
instructions. Instead, we've got this 207-instruction monster… but hey, at
least it works. 🤷
The remaining time then went to YuugenMagan's initialization code, which
allowed me to immediately remove more declarations from ASM land, but more
on that once we get to the rest of that boss fight.
That leaves 76 functions until we're done with TH01! Next up: Card-flipping
stage obstacles.
OK, TH01 missile bullets. Can we maybe have a well-behaved entity type,
without any weirdness? Just once?
Ehh, kinda. Apart from another 150 bytes wasted on unused structure members,
this code is indeed more on the low end in terms of overall jank. It does
become very obvious why dodging these missiles in the YuugenMagan, Mima, and
Elis fights feels so awful though: An unfair 46×46 pixel hitbox around
Reimu's center pixel, combined with the comeback of
📝 interlaced rendering, this time in every
stage. ZUN probably did this because missiles are the only 16×16 sprite in
TH01 that is blitted to unaligned X positions, which effectively ends up
touching a 32×16 area of VRAM per sprite.
But even if we assume VRAM writes to be the bottleneck here, it would
have been totally possible to render every missile in every frame at roughly
the same amount of CPU time that the original game uses for interlaced
rendering:
Note that all missile sprites only use two colors, white and green.
Instead of naively going with the usual four bitplanes, extract the
pixels drawn in each of the two used colors into their own bitplanes.
master.lib calls this the "tiny format".
Use the GRCG to draw these two bitplanes in the intended white and green
colors, halving the amount of VRAM writes compared to the original
function.
(Not using the .PTN format would have also avoided the inconsistency of
storing the missile sprites in boss-specific sprite slots.)
That's an optimization that would have significantly benefitted the game, in
contrast to all of the fake ones
introduced in later games. Then again, this optimization is
actually something that the later games do, and it might have in fact been
necessary to achieve their higher bullet counts without significant
slowdown.
After some effectively unused Mima sprite effect code that is so broken that
it's impossible to make sense out of it, we get to the final feature I
wanted to cover for all bosses in parallel before returning to Sariel: The
separate sprite background storage for moving or animated boss sprites in
the Mima, Elis, and Sariel fights. But, uh… why is this necessary to begin
with? Doesn't TH01 already reserve the other VRAM page for backgrounds?
Well, these sprites are quite big, and ZUN didn't want to blit them from
main memory on every frame. After all, TH01 and TH02 had a minimum required
clock speed of 33 MHz, half of the speed required for the later three games.
So, he simply blitted these boss sprites to both VRAM pages, leading
the usual unblitting calls to only remove the other sprites on top of the
boss. However, these bosses themselves want to move across the screen…
and this makes it necessary to save the stage background behind them
in some other way.
Enter .PTN, and its functions to capture a 16×16 or 32×32 square from VRAM
into a sprite slot. No problem with that approach in theory, as the size of
all these bigger sprites is a multiple of 32×32; splitting a larger sprite
into these smaller 32×32 chunks makes the code look just a little bit clumsy
(and, of course, slower).
But somewhere during the development of Mima's fight, ZUN apparently forgot
that those sprite backgrounds existed. And once Mima's 🚫 casting sprite is
blitted on top of her regular sprite, using just regular sprite
transparency, she ends up with her infamous third arm:
Ironically, there's an unused code path in Mima's unblit function where ZUN
assumes a height of 48 pixels for Mima's animation sprites rather than the
actual 64. This leads to even clumsier .PTN function calls for the bottom
128×16 pixels… Failing to unblit the bottom 16 pixels would have also
yielded that third arm, although it wouldn't have looked as natural. Still
wouldn't say that it was intentional; maybe this casting sprite was just
added pretty late in the game's development?
So, mission accomplished, Sariel unblocked… at 2¼ pushes. That's quite some time left for some smaller stage initialization
code, which bundles a bunch of random function calls in places where they
logically really don't belong. The stage opening animation then adds a bunch
of VRAM inter-page copies that are not only redundant but can't even be
understood without knowing the hidden internal state of the last VRAM page
accessed by previous ZUN code…
In better news though: Turbo C++ 4.0 really doesn't seem to have any
complexity limit on inlining arithmetic expressions, as long as they only
operate on compile-time constants. That's how we get macro-free,
compile-time Shift-JIS to JIS X 0208 conversion of the individual code
points in the 東方★靈異伝 string, in a compiler from 1994. As long as you
don't store any intermediate results in variables, that is…
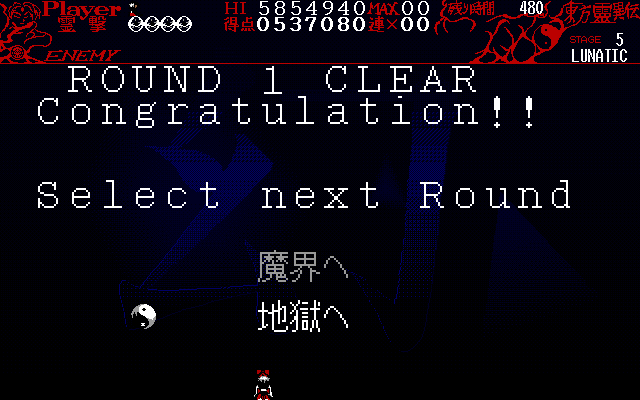
But wait, there's more! With still ¼ of a push left, I also went for the
boss defeat animation, which includes the route selection after the SinGyoku
fight.
As in all other instances, the 2× scaled font is accomplished by first
rendering the text at regular 1× resolution to the other, invisible VRAM
page, and then scaled from there to the visible one. However, the route
selection is unique in that its scaled text is both drawn transparently on
top of the stage background (not onto a black one), and can also change
colors depending on the selection. It would have been no problem to unblit
and reblit the text by rendering the 1× version to a position on the
invisible VRAM page that isn't covered by the 2× version on the visible one,
but ZUN (needlessly) clears the invisible page before rendering any text.
Instead, he assigned a separate VRAM color for both
the 魔界 and 地獄 options, and only changed the palette value for
these colors to white or gray, depending on the correct selection. This is
another one of the
📝 rare cases where TH01 demonstrates good use of PC-98 hardware,
as the 魔界へ and 地獄へ strings don't need to be reblitted during the selection process, only the Orb "cursor" does.
Then, why does this still not count as good-code? When
changing palette colors, you kinda need to be aware of everything
else that can possibly be on screen, which colors are used there, and which
aren't and can therefore be used for such an effect without affecting other
sprites. In this case, well… hover over the image below, and notice how
Reimu's hair and the bomb sprites in the HUD light up when Makai is
selected:
This push did end on a high note though, with the generic, non-SinGyoku
version of the defeat animation being an easily parametrizable copy. And
that's how you decompile another 2.58% of TH01 in just slightly over three
pushes.
Now, we're not only ready to decompile Sariel, but also Kikuri, Elis, and
SinGyoku without needing any more detours into non-boss code. Thanks to the
current TH01 funding subscriptions, I can plan to cover most, if not all, of
Sariel in a single push series, but the currently 3 pending pushes probably
won't suffice for Sariel's 8.10% of all remaining code in TH01. We've got
quite a lot of not specifically TH01-related funds in the backlog to pass
the time though.
Due to recent developments, it actually makes quite a lot of sense to take a
break from TH01: spaztron64 has
managed what every Touhou download site so far has failed to do: Bundling
all 5 game onto a single .HDI together with pre-configured PC-98
emulators and a nice boot menu, and hosting the resulting package on a
proper website. While this first release is already quite good (and much
better than my attempt from 2014), there is still a bit of room for
improvement to be gained from specific ReC98 research. Next up,
therefore:
Researching how TH04 and TH05 use EMS memory, together with the cause
behind TH04's crash in Stage 5 when playing as Reimu without an EMS driver
loaded, and
reverse-engineering TH03's score data file format
(YUME.NEM), which hopefully also comes with a way of building a
file that unlocks all characters without any high scores.
Nothing really noteworthy in TH01's stage timer code, just yet another HUD
element that is needlessly drawn into VRAM. Sure, ZUN applies his custom
boldfacing effect on top of the glyphs retrieved from font ROM, but he could
have easily installed those modified glyphs as gaiji.
Well, OK, halfwidth gaiji aren't exactly well documented, and sometimes not
even correctly emulated
📝 due to the same PC-98 hardware oddity I was researching last month.
I've reserved two of the pending anonymous "anything" pushes for the
conclusion of this research, just in case you were wondering why the
outstanding workload is now lower after the two delivered here.
And since it doesn't seem to be clearly documented elsewhere: Every 2 ticks
on the stage timer correspond to 4 frames.
So, TH01 rank pellet speed. The resident pellet speed value is a
factor ranging from a minimum of -0.375 up to a maximum of 0.5 (pixels per
frame), multiplied with the difficulty-adjusted base speed for each pellet
and added on top of that same speed. This multiplier is modified
every time the stage timer reaches 0 and
HARRY UP is shown (+0.05)
for every score-based extra life granted below the maximum number of
lives (+0.025)
every time a bomb is used (+0.025)
on every frame in which the rand value (shown in debug
mode) is evenly divisible by
(1800 - (lives × 200) - (bombs × 50)) (+0.025)
every time Reimu got hit (set to 0 if higher, then -0.05)
when using a continue (set to -0.05 if higher, then -0.125)
Apparently, ZUN noted that these deltas couldn't be losslessly stored in an
IEEE 754 floating-point variable, and therefore didn't store the pellet
speed factor exactly in a way that would correspond to its gameplay effect.
Instead, it's stored similar to Q12.4 subpixels: as a simple integer,
pre-multiplied by 40. This results in a raw range of -15 to 20, which is
what the undecompiled ASM calls still use. When spawning a new pellet, its
base speed is first multiplied by that factor, and then divided by 40 again.
This is actually quite smart: The calculation doesn't need to be aware of
either Q12.4 or the 40× format, as
((Q12.4 * factor×40) / factor×40) still comes out as a
Q12.4 subpixel even if all numbers are integers. The only limiting issue
here would be the potential overflow of the 16-bit multiplication at
unadjusted base speeds of more than 50 pixels per frame, but that'd be
seriously unplayable.
So yeah, pellet speed modifications are indeed gradual, and don't just fall
into the coarse three "high, normal, and low" categories.
That's ⅝ of P0160 done, and the continue and pause menus would make good
candidates to fill up the remaining ⅜… except that it seemed impossible to
figure out the correct compiler options for this code?
The issues centered around the two effects of Turbo C++ 4.0J's
-O switch:
Optimizing jump instructions: merging duplicate successive jumps into a
single one, and merging duplicated instructions at the end of conditional
branches into a single place under a single branch, which the other branches
then jump to
Compressing ADD SP and POP CX
stack-clearing instructions after multiple successive CALLs to
__cdecl functions into a single ADD SP with the
combined parameter stack size of all function calls
But how can the ASM for these functions exhibit #1 but not #2? How
can it be seemingly optimized and unoptimized at the same time? The
only option that gets somewhat close would be -O- -y, which
emits line number information into the .OBJ files for debugging. This
combination provides its own kind of #1, but these functions clearly need
the real deal.
The research into this issue ended up consuming a full push on its own.
In the end, this solution turned out to be completely unrelated to compiler
options, and instead came from the effects of a compiler bug in a totally
different place. Initializing a local structure instance or array like
const uint4_t flash_colors[3] = { 3, 4, 5 };
always emits the { 3, 4, 5 } array into the program's data
segment, and then generates a call to the internal SCOPY@
function which copies this data array to the local variable on the stack.
And as soon as this SCOPY@ call is emitted, the -O
optimization #1 is disabled for the entire rest of the translation
unit?!
So, any code segment with an SCOPY@ call followed by
__cdecl functions must strictly be decompiled from top to
bottom, mirroring the original layout of translation units. That means no
TH01 continue and pause menus before we haven't decompiled the bomb
animation, which contains such an SCOPY@ call. 😕
Luckily, TH01 is the only game where this bug leads to significant
restrictions in decompilation order, as later games predominantly use the
pascal calling convention, in which each function itself clears
its stack as part of its RET instruction.
What now, then? With 51% of REIIDEN.EXE decompiled, we're
slowly running out of small features that can be decompiled within ⅜ of a
push. Good that I haven't been looking a lot into OP.EXE and
FUUIN.EXE, which pretty much only got easy pieces of
code left to do. Maybe I'll end up finishing their decompilations entirely
within these smaller gaps? I still ended up finding one more small
piece in REIIDEN.EXE though: The particle system, seen in the
Mima fight.
I like how everything about this animation is contained within a single
function that is called once per frame, but ZUN could have really
consolidated the spawning code for new particles a bit. In Mima's fight,
particles are only spawned from the top and right edges of the screen, but
the function in fact contains unused code for all other 7 possible
directions, written in quite a bloated manner. This wouldn't feel quite as
unused if ZUN had used an angle parameter instead…
Also, why unnecessarily waste another 40 bytes of
the BSS segment?
But wait, what's going on with the very first spawned particle that just
stops near the bottom edge of the screen in the video above? Well, even in
such a simple and self-contained function, ZUN managed to include an
off-by-one error. This one then results in an out-of-bounds array access on
the 80th frame, where the code attempts to spawn a 41st
particle. If the first particle was unlucky to be both slow enough and
spawned away far enough from the bottom and right edges, the spawning code
will then kill it off before its unblitting code gets to run, leaving its
pixel on the screen until something else overlaps it and causes it to be
unblitted.
Which, during regular gameplay, will quickly happen with the Orb, all the
pellets flying around, and your own player movement. Also, the RNG can
easily spawn this particle at a position and velocity that causes it to
leave the screen more quickly. Kind of impressive how ZUN laid out the
structure
of arrays in a way that ensured practically no effect of this bug on the
game; this glitch could have easily happened every 80 frames instead.
He almost got close to all bugs canceling out each other here!
Next up: The player control functions, including the second-biggest function
in all of PC-98 Touhou.
Well, make that three days. Trying to figure out all the details behind
the sprite flickering was absolutely dreadful…
It started out easy enough, though. Unsurprisingly, TH01 had a quite
limited pellet system compared to TH04 and TH05:
The cap is 100, rather than 240 in TH04 or 180 in TH05.
Only 6 special motion functions (with one of them broken and unused)
instead of 10. This is where you find the code that generates SinGyoku's
chase pellets, Kikuri's small spinning multi-pellet circles, and
Konngara's rain pellets that bounce down from the top of the playfield.
A tiny selection of preconfigured multi-pellet groups. Rather than
TH04's and TH05's freely configurable n-way spreads, stacks, and rings,
TH01 only provides abstractions for 2-, 3-, 4-, and 5- way spreads (yup,
no 6-way or beyond), with a fixed narrow or wide angle between the
individual pellets. The resulting pellets are also hardcoded to linear
motion, and can't use the special motion functions. Maybe not the best
code, but still kind of cute, since the generated groups do follow a
clear logic.
As expected from TH01, the code comes with its fair share of smaller,
insignificant ZUN bugs and oversights. As you would also expect
though, the sprite flickering points to the biggest and most consequential
flaw in all of this.
Apparently, it started with ZUN getting the impression that it's only
possible to use the PC-98 EGC for fast blitting of all 4 bitplanes in one
CPU instruction if you blit 16 horizontal pixels (= 2 bytes) at a time.
Consequently, he only wrote one function for EGC-accelerated sprite
unblitting, which can only operate on a "grid" of 16×1 tiles in VRAM. But
wait, pellets are not only just 8×8, but can also be placed at any
unaligned X position…
… yet the game still insists on using this 16-dot-aligned function to
unblit pellets, forcing itself into using a super sloppy 16×8 rectangle
for the job. 🤦 ZUN then tried to mitigate the resulting flickering in two
hilarious ways that just make it worse:
An… "interlaced rendering" mode? This one's activated for all Stage 15
and 20 fights, and separates pellets into two halves that are rendered on
alternating frames. Collision detection with the Yin-Yang Orb and the
player is only done for the visible half, but collision detection with
player shots is still done for all pellets every frame, as are
motion updates – so that pellets don't end up moving half as fast as they
should.
So yeah, your eyes weren't deceiving you. The game does effectively
drop its perceived frame rate in the Elis, Kikuri, Sariel, and Konngara
fights, and it does so deliberately.
📝 Just like player shots, pellets
are also unblitted, moved, and rendered in a single function.
Thanks to the 16×8 rectangle, there's now the (completely unnecessary)
possibility of accidentally unblitting parts of a sprite that was
previously drawn into the 8 pixels right of a pellet. And this
is where ZUN went full and went "oh, I
know, let's test the entire 16 pixels, and in case we got an entity
there, we simply make the pellet invisible for this frame! Then
we don't even have to unblit it later!"
Except that this is only done for the first 3 elements of the player
shot array…?! Which don't even necessarily have to contain the 3 shots
fired last. It's not done for the player sprite, the Orb, or, heck,
other pellets that come earlier in the pellet array. (At least
we avoided going 𝑂(𝑛²) there?)
Actually, and I'm only realizing this now as I type this blog post:
This test is done even if the shots at those array elements aren't
active. So, pellets tend to be made invisible based on comparisons
with garbage data.
And then you notice that the player shot
unblit/move/render function is actually only ever called from the
pellet unblit/move/render function on the one global instance
of the player shot manager class, after pellets were unblitted. So, we
end up with a sequence of
which means that we can't ever unblit a previously rendered shot
with a pellet. Sure, as terrible as this one function call is from
a software architecture perspective, it was enough to fix this issue.
Yet we don't even get the intended positive effect, and walk away with
pellets that are made temporarily invisible for no reason at all. So,
uh, maybe it all just was an attempt at increasing the
ramerate on lower spec PC-98 models?
Yup, that's it, we've found the most stupid piece of code in this game,
period. It'll be hard to top this.
I'm confident that it's possible to turn TH01 into a well-written, fluid
PC-98 game, with no flickering, and no perceived lag, once it's
position-independent. With some more in-depth knowledge and documentation
on the EGC (remember, there's still
📝 this one TH03 push waiting to be funded),
you might even be able to continue using that piece of blitter hardware.
And no, you certainly won't need ASM micro-optimizations – just a bit of
knowledge about which optimizations Turbo C++ does on its own, and what
you'd have to improve in your own code. It'd be very hard to write
worse code than what you find in TH01 itself.
(Godbolt for Turbo C++ 4.0J when?
Seriously though, that would 📝 also be a
great project for outside contributors!)
Oh well. In contrast to TH04 and TH05, where 4 pushes only covered all the
involved data types, they were enough to completely cover all of
the pellet code in TH01. Everything's already decompiled, and we never
have to look at it again. 😌 And with that, TH01 has also gone from by far
the least RE'd to the most RE'd game within ReC98, in just half a year! 🎉
Still, that was enough TH01 game logic for a while.
Next up: Making up for the delay with some
more relaxing and easy pieces of TH01 code, that hopefully make just a
bit more sense than all this garbage. More image formats, mainly.
 , activated for all pellets during the symmetrical radial 2-ring
pattern in Phase 2 and left activated for the rest of the fight. These
pellets will continue their animation after the transition to the second
form, and turn into regular pellets you have to dodge once their animation
completed.
, activated for all pellets during the symmetrical radial 2-ring
pattern in Phase 2 and left activated for the rest of the fight. These
pellets will continue their animation after the transition to the second
form, and turn into regular pellets you have to dodge once their animation
completed.